In a W.E.I.R.D. social world where anything that requires an attention span beyond 5 minutes is ignored in favour of short memes, silver bullets, and artificially “intelligent” systems, this article intends to provide an emergency brake to slow us down to a speed that allows critical self reflection.
Instead of telling people what you think they would love to hear, tell people what they need to know. Step outside the box of the established social and economic paradigm by adopting a life affirming working definition of collective intelligence that is not confined to the distorted characterisation of human potential that dominates in W.E.I.R.D. cultures.
Note: This recommendation must be applied literally. Continuing to use the old language when interacting with established institutions and the dominant culture renders the effort useless.
Think long-term
Instead of aiming for “low hanging fruit”, build trusted relationships around long-term goals.
It can be helpful to learn from outsiders and members of minorities. Onondaga Chief and Faithkeeper Oren Lyons describes a collaboration between indigenous nations that has a history that predates European “discovery” by over thousand years, and that has survived until today. The culture he describes is one example of a number of indigenous societies that have traditionally operated with a 150 year or longer look-ahead time horizon.
Recently I was delighted to read about a company here in Aotearoa that operates on a 500 year time horizon. S23M, our employee owned NeurodiVenture is 19 years old. Our measure of success is tied to a 200+ year time horizon.
Note: Time horizons shorter than 150 years encourage tribalism and counter-productive competition between groups.
Enjoy interdependence
Instead of generating “profit”, nurture relationships at human scale – with humans and with other forms of life.
The notion of disability in our society is underscored by a bizarre conception of “independence”. Humans have evolved to live in highly collaborative groups, with strong interdependencies between individuals and in many cases between groups.
In our pre-civilised past all human groups were small, and interdependence and the need for mutual assistance was obvious to all members of a group.
The tools of civilisation, including money, have undermined our appreciation of interdependence, and within the Western world have culminated in a toxic cult of competitive individualism, which ironically leads to extreme levels of groupthink.
Evolutionary biologists consider small groups to be the organisms of human societies. This has massive implications for the gene-culture co-evolution that characterises our species.
Humans are not the first hyper-social species on this planet. Insects such as ants offer great examples of successful collaboration at immense scale over millions of years. Charles Darwin and other early proponents of evolutionary theory appreciated the role of collaboration within species and between species, but many of these early insights including related empirical observations have been suppressed within the hyper-competitive narrative that has come to dominate industrialised civilisation.
Note: Robin Dunbar’s observations on human cognitive limits apply. In a transactional world, collective intelligence goes down the drain. Hierarchical organisations with several thousand staff tend to act less intelligently than a single individual, and as group size grows further, intelligence tends towards zero.
Clamp down on meritocracy
Instead of establishing a “meritocracy“, catalyse the emergence of an egalitarian culture.
All forms of meritocracy result in toxic in-group competition and prevent knowledge from flowing to places where it can be put to good use.
“Selfishness beats altruism within groups. Altruistic groups beat selfish groups. Everything else is commentary.” – David Sloan Wilson and Edward O. Wilson (2007)
Remove all incentives for in-group competition. Share risks and rewards equally, and encourage people to share their individual competency networks, without aggregating the data to determine rankings that interfere with the emergence of collective intelligence.
“Pay for merit, pay for what you get, reward performance. Sounds great, can’t be done. Unfortunately it can not be done, on short range. After 10 years perhaps, 20 years, yes. The effect is devastating. People must have something to show, something to count. In other words, the merit system nourishes short-term performance. It annihilates long-term planning. It annihilates teamwork. People can not work together. To get promotion you’ve got to get ahead. By working with a team, you help other people. You may help yourself equally, but you don’t get ahead by being equal, you get ahead by being ahead. Produce something more, have more to show, more to count. Teamwork means work together, hear everybody’s ideas, fill in for other people’s weaknesses, acknowledge their strengths. Work together. This is impossible under the merit rating / review of performance system. People are afraid. They are in fear. They work in fear. They can not contribute to the company as they would wish to contribute. This holds at all levels. But there is something worse than all of that. When the annual ratings are given out, people are bitter. They can not understand why they are not rated high. And there is a good reason not to understand. Because I could show you with a bit of time that it is purely a lottery.” – W Edwards Deming (1984)
The notions of management and leadership are entangled with the anthropocentric conception of civilisation. In a hierarchical structure most people abandon their sense of agency and the need to think critically on a daily basis.
“You never change things by fighting the existing reality. To change something, build a new model that makes the existing model obsolete.” ― Buckminster Fuller (1975)
The path to escape the box of a sick society involves rediscovering timeless and minimalistic principles for coordinating creative collaboration in the absence of capital and hierarchical structures:
Visibly extend trust to people, to release the handbrake to collaboration.
Unlock valuable tacit knowledge within a group.
Provide a space for creative freedom.
Help repair frayed relationships.
Replace fear with courage.
Note: As long as an organisation describes itself with a pyramidal organisational chart it projects a not-very-subtle-at-all signal that management by fear is to be tolerated by and is expected of anyone who joins.
Avoid distractions
Instead of “competing in the market”, build trusted relationships with other human scale groups.
Organisations are best thought of as cultural organisms. Groups of organisations with compatible operating models can be thought of as a cultural species. The human genus (homo) is the genus that includes all cultural species.
The main difference between modern emergent human scale cultural species and prehistoric human scale cultural species lies in the language systems and communication technologies that are being used to coordinate activities and to record and transmit knowledge within cultural organisms, between cultural organisms, and between cultural species.
Collaborative niche construction allows organisations and people to participate in the evolution of a living system and results in resilient social ecosystems. A few statistics from the Wikipedia list of oldest companies should provide food for thought:
According to a report published by the Bank of Korea in 2008 that looked at 41 countries, there were 5,586 companies older than 200 years. Of these, 3,146 (56%) are in Japan.
Of the companies with more than 100 years of history, most of them (89%) employ fewer than 300 people.
A nationwide Japanese survey counted more than 21,000 companies older than 100 years as of September 30, 2009.
Note: The fragile economic mono-cultures that emerge from competition are prone to boom and bust cycles – the net effect is a waste of precious time and scarce resources.
Share knowledge
Instead of hoarding and “monetising information”, distil patterns from your human scale environment and use an advice process to filter out the noise – only share trustworthy knowledge.
In a good company coordination and organisational learning happens without any need for social power structures. Before making a major decision that affects others:
A person has to seek advice from at least one trusted colleague with potentially relevant or complementary knowledge or expertise.
Giving advice is optional. It is okay to admit lack of expertise. This enables the requestor to proceed on the basis of the available evidence.
Following advice is optional. The requestor may ignore advice if she/he believes that all things considered there is a better approach or solution. Not receiving advice in a timely manner is deemed equivalent to no relevant advice being available within the organisation. This allows everyone to balance available wisdom with first hand learning and risk taking.
Note: When all your trusted collaborators engage in this practice, the result is a growing network of individual competency networks.
Relax
The real opportunity for human society and human organisations lies not in the invention of ever “smarter” forms of in-group competition, but in the recognition of human cognitive limits, and in the recognition of the priceless value that resides in competency networks.
For the first time, the age of digital networks enables us to construct cognitive assistants that help us to nurture and maintain globally distributed human scale competency networks – networks of mutual trust. It is time to tap into this potential and to combine it with the potential of zero-marginal cost global communication and collaboration.
A simple advice process establishes the vital feedback loops that enable organisations to learn and adapt in a timely manner, even in a highly dynamic context.
If you replace the toxic language of bu$yness, think long-term, enjoy interdependence, clamp down on meritocracy, avoid distractions, and share knowledge, you can relax. No one is in control. Mistakes happen on this planet all the time.
Like bees and ants, humans are eusocial animals. Through the lenses of evolutionary biology and cultural evolution, small groups of 20 to 100 people are the primary organisms within human society – in contrast to individuals, corporations, and nation states. The implications for our civilisation are profound, a topic that I explore in detail in my new book The beauty of collaboration at human scale – Timeless patterns of human limitations, which is now in the peer review stage.
The growing cracks in the thin veneer of our “civilised” economic and social operating model are impossible to ignore, to the extent that serious discussions of degrowth are increasingly finding their way into mainstream media.
No day goes by without further examples of how the logic of capital, whether privatised or in the hands of the state, gets in the way of meeting essential human needs, or actively undermines any attempt to address the needs of the non-human inhabitants of planet Earth.
“Civilised” humans are so self-absorbed that they conceptualise Earth as “their” planet without blinking an eye. It is impossible to paddle back from this extreme position without acknowledging the collective delusion induced by our “civilised” way of life.
How do we go about to construct ecological niches that contribute to the thriving of life on Earth rather than taking away from it? We have triggered the sixth mass extinction, and biodiversity is declining at unprecedented rates.
What ecological role do we want to play going forward? Note that we have successfully disqualified ourselves from the absurdly anthropocentric role of “owner”.
Are we still capable of relearning of how to engage with other species at eye level? We might be able to learn quite a bit from other less self-absorbed species.
Industrialised “civilisation” has not only triggered the loss of biodiversity, it has even compelled us to pathologise humans that don’t seem to be able to cope with the demands of “civilisation”, such that increasingly children are labelled with “developmental disorders”.
“Civilised” neuronormative humans are so dependent on the security blanket of culture, that their attempt to maintain a culturally defined sense of “normality” results in a tiny Overton window that is so narrow that every sixth person is excluded, pathologised, and ideally subjected to normalisation therapies, to better fit into so-called “normality”.
Apparently humans are not only bent on reducing biodiversity via pesticides, insecticides, destruction of habitats, and green house gas emissions, we also seem to be bent on reducing the neurodiversity that is inherent in our own species. The industrial paradigm of “civilisation” critically depends on a reliable source of compliant culturally “well adjusted” conformists.
Sadly David Graeber died few weeks ago. The world could have benefited more from his line of inquiry into industrialised bureaucracy. Here is an extract from his brilliant first lecture at LSE in 2006:
Bureaucracies public and private appear—for whatever historical reasons—to be organized in such a way as to guarantee that a significant proportion of actors will not be able to perform their tasks as expected. It also exemplifies what I have come to think of the defining feature of a utopian form of practice, in that, on discovering this, those maintaining the system conclude that the problem is not with the system itself but with the inadequacy of the human beings involved…
What I would like to argue is that situations created by violence—particularly structural violence, by which I mean forms of pervasive social inequality that are ultimately backed up by the threat of physical harm—invariably tend to create the kinds of willful blindness we normally associate with bureaucratic procedures. To put it crudely: it is not so much that bureaucratic procedures are inherently stupid, or even that they tend to produce behavior that they themselves define as stupid, but rather, that are invariably ways of managing social situations that are already stupid because they are founded on structural violence…
Bureaucratic knowledge is all about schematization. In practice, bureaucratic procedure invariably means ignoring all the subtleties of real social existence and reducing everything to preconceived mechanical or statistical formulae. Whether it’s a matter of forms, rules, statistics, or questionnaires, it is always a matter of simplification.
Usually it’s not so different than the boss who walks into the kitchen to make arbitrary snap decisions as to what went wrong: in either case it is a matter of applying very simple pre-existing templates to complex and often ambiguous situations. The result often leaves those forced to deal with bureaucratic administration with the impression that they are dealing with people who have for some arbitrary reason decided to put on a set of glasses that only allows them to see only 2% of what’s in front of them…
It only makes sense then that bureaucratic violence should consist first and foremost of attacks on those who insist on alternative schemas or interpretations. At the same time, if one accepts Piaget’s famous definition of mature intelligence as the ability to coordinate between multiple perspectives (or possible perspectives) one can see, here, precisely how bureaucratic power, at the moment it turns to violence, becomes literally a form of infantile stupidity…
The question for me is whether our theoretical work is ultimately directed at undoing, dismantling, some of the effects of these lopsided structures of imagination, or whether—as can so easily happen when even our best ideas come to be backed up by bureaucratically administered violence—we end up reinforcing them.
David Graeber had a refreshingly down to earth and entrepreneurial approach to activism, which consisted of embarking on actions that seem appropriate to create a new reality (rather than simply engaging in civil disobedience) – and ignoring the established status-quo as needed to overcome crippling cultural inertia. He conceptualised the revolt of the caring classes and encouraged the activation of bureaucratically suppressed knowledge, i.e. the things that people are not allowed to talk about, into a power that can transform society.
I have a very similar philosophy. What I write about may at times seem abstract, but it always relates to concrete initiatives and services that I am involved with. This article connects some of the topics that I have written about in recent years with related services provided by S23M or the Autistic Collaboration Trust.
Paddling back from lethal forms of monoculture
Where to from here?
We live in a highly dynamic world, and our capability to understand the world we have stumbled into is quite limited. However, once we acknowledge our limitations, it is possible to learn from our mistakes, and also from the ways of life and the survival skills we cultivated in our pre-civilised past, which served us well for several hundred thousand years.
Our destination is beyond human comprehension, but ways of life that are in tune with our biological needs and cognitive limits are always within reach, even when we find ourselves in a self-created life destroying environment. All it takes is a shift in perspective, and corresponding shifts in the aspects of our lives that we value.
I have written about the various shifts in values that are currently in progress. The following sections contain extracts and link to articles with further details and background.
Shifting from independence to interdependence
Appreciation of humility
The notion of disability in our society is underscored by a bizarre conception of “independence”.
Humans have evolved to live in highly collaborative groups, with strong interdependencies between individuals and in many cases between groups. In our pre-civilised past all human groups were small, and interdependence and the need for mutual assistance was obvious to all members of a group.
The tools of civilisation, including money, have undermined our appreciation of interdependence, and within the Western world have culminated in a toxic cult of competitive individualism, which amongst the non-autistic population ironically leads to extreme levels of groupthink.
If you consider any potential outcomes beyond a ten year time horizon the current path of industrialised “civilisation” must be described as a form of collective delusion.
COVID-19 punched a big hole into the progress myth of of our “civilisation” and has exposed cultural practices that have substantially increased the risks of pandemics over the last 50 years.
At this stage our societies are still in the early stages of (re)learning essential knowledge about pandemics. The growing risks of much deadlier pandemics emanating from industrial animal agriculture practices, natural ecosystem destruction, and accelerating climate change (also leading to increasingly extreme weather events, crop failures, and resource conflicts) are not yet part of the public discourse.
To what extent human societies will experience famines, wars, and violent revolutions in the coming decades depends on two factors:
1. How many governments pro-actively and systematically discount the interests of capitalised busyness in favour of the immediate and the long-term (200+ year horizon) needs of human communities and ecosystems.
2. The extent to which human communities deploy easily (re)configurable digital technologies that are co-designed to meet local and bioregional collaboration needs, to serve as the backbone for non-violent “revolutions” in shared values, shared knowledge commons, and new (much less energy intensive and more collaborative and diverse) ways of living.
Shifting from transactions to trusted relationships
Appreciation of mutual trust
Autists are acutely aware that culture is constructed one trusted relationship at a time – this is the essence of fully appreciating diversity.
Society must start to move beyond awareness and acceptance towards appreciation of cognitive diversity. The topic of culture is a double edged sword. On the one hand a shared culture can streamline collaboration, but on the other hand, the more open and diverse a culture, the more friendly it is towards minorities and outsiders.
It is very easy for groups of people and institutions to become preoccupied with specific cultural rituals and so-called cultural fit, whereas what matters most for collaboration and deep innovation is the appreciation of diversity and the development of mutual trust. This is obvious to many autistic people, but only very recently has cognitive diversity started to become recognised as genuinely valuable beyond the autistic community.
Shifting from hoarding information to sharing of knowledge
Appreciation of mutual understanding
By definition, we don’t understand all the people that we “don’t relate to”. In our busy civilised and hyper-social lives we come across far more than 150 people (Dunbar’s number). We interact within them on a transactional anonymous basis, and we may read about their lives, but it is impossible for us to fully understand their context, as we have not walked in their shoes from the first day in their lives, and thus lack the experience, the insights, and the tacit knowledge that shapes their unique world-views.
Thus, making decisions that potentially affect the lives of many hundred to several billion people without explicit consent of all those potentially affected, must be considered the pinnacle of human ignorance and is a strong indicator of a lack of compassion.
Prior to the information age, for several hundred thousand years humans lived in much smaller groups without written language, money, and cities. The archaeological evidence available and also the evidence from “uncivilised” indigenous cultures that have survived until recently in a few remote places point towards an interesting commonality in the social norms of such societies:
The strongest social norms in pre-civilised societies were norms that prevented individuals from gaining power over others.
“Civilisation” can be thought of as a social operating system that is afflicted by a collective learning disability induced by primate dominance hierarchies, which dampen feedback loops and flows of valuable knowledge. The result is a cultural inertia that perpetuates social power gradients and that discriminates against the discoverers of new knowledge that might undermine established social structures.
The exciting aspect about the human capacity for culture is that via a series of accidental discoveries and inventions, we have created a global network for sharing valuable knowledge, as well as opinions and misinformation. It apparently takes a virus like SARS-CoV-2 to put this network to good use, and to shift “civilised” cultural norms away from profit maximisation and back towards sharing knowledge for collective benefit.
The 10,000 year project of human civilisation or empire building is coming to an end. Human life as we knew it – shaped by the anthropocentric myths of meritocracy, technological progress, and growth – is less and less compatible with our daily experiences and with the needs of all the people and other living creatures that we care about.
Since the Cold War empires have increasingly shifted their focus from overt conventional war to economic warfare and psychological warfare. The growing economic power imbalance between the empires of the “developed” world and “less developed” nation states has significantly reduced the need for large scale direct military interventions to maintain imperial power structures.
The mainstream narrative of conventional, economic, and psychological warfare of course prefers framing of the same activities using the language of defending national interests, economic development, disruptive innovation, and achieving economies of scale.
Framing is the key tool for detracting from the many millions of human and non-human casualties.
The underlying common theme across all imperial cultures is the concept of cultural superiority, which results in a sense of entitlement and a perpetual drive to out-compete and over-power groups with different and “inferior” cultures.
Even though Western science likes to think of itself as ideology neutral it is not immune to ideological influence. The Western scientific worldview continues to be plagued by artificial discipline boundaries that significantly slow down the process of transdisciplinary knowledge transfer and the discovery of new insights that remain hidden in the deep chasms between established disciplines.
We need a language to reason about the cultural superiority complex of imperial societies and potential therapies and cures. Such a language is not only useful in biology, but also in all contexts that relate to human social behaviour and human activity within the context of biological ecosystems at all levels of scale.
The Human Lens provides thirteen categories that are invariant across cultures, space, and time – it provides an economic ideology independent reasoning framework for transdisciplinary collaboration.
The Human Lens concepts are recognisable in all historic human cultures, and they will continue to be relevant in another 1,000 years – this is what is meant by “economic ideology independent”.
Shifting from scarcity of resources to abundance of mutual aid
Appreciation of creativity
If neurodiversity is the natural variation of cognition, motivations, and patterns of behaviour within the human species, then what role do autistic traits in particular play within human cultures and what cultural evolutionary pressures have allowed autistic traits to persist over hundreds of thousands of years?
The benefits of autistic traits such as autistic levels of hypersensitivity, hyperfocus, perseverance, lack of interest in social status, and inability to maintain hidden agendas mostly do not materialise at an individual level but at the level of the local social environment that an autistic person is embedded in.
Within the bigger picture of cultural evolution autistic traits have obvious mid and long-term benefits to society, but these benefits are associated with short-term costs for social status seeking individuals within the local social environments of autistic people.
Many autistic people intuitively avoid copying the behaviours of non-autistic people. Life teaches autistic people that culturally expected behaviour often leads to sensory overload, and furthermore, that cultural practices often contain spurious complexity that have nothing to do with the stated goal of the various practices, such that a little independent exploration and experimentation usually reveals a simpler, faster, or less energy intensive way of achieving comparable results.
The unique human ability to adapt to new contexts, powered by neurodivergent creativity and the development of new tools, enabled humans to minimise conflicts and establish a presence in virtually all ecosystems on the planet. This level of adaptability is the signature trait of the human species.
Within “civilisation” autistic people tend to be highly concerned about social justice and tend to be the ones who point out toxic in-group competitive behaviours.
Autistic people are best understood as the agents of a well functioning cultural immune system within human society. This would have been obvious in pre-civilised societies, but it has become non-obvious in “civilised” societies.
Shifting from death by standardisation to celebration of diversity
Appreciation of uniqueness
In some geographies the prevalence of autism within the population is now estimated to be 1 in 35. Overall, in the US, according to CDC data, 1 in 6 children has a “developmental disability”, and in the UK, according to the Department of Education, 15% (roughly 1 in 7) of students have a “learning difference”.
I don’t have any issue with these numbers. In fact I am delighted that the extent to which people differ from one another is finally being recognised. But I do have an issue with the continuing pathologisation of people that don’t fit a standardised idealised (and hence fictional) human template. Even if we are seeing the first cracks in the pathology paradigm in relation to variances in neurocognitive functioning in the form of a partial shift from the language of disorder to condition and to difference, many of the traits associated with differences are still described in the pathologising language of diagnostic criteria.
The desire to categorise and standardise human behaviours is the underlying force of civilised societies, which reached new heights over the last 250 years, first with the mechanistic factory model of the world that defined the early industrial era, and then more recently, with the development of networked computers and with the emergence of automated information flows that currently shape significant parts of our lives and our interactions with people and with abstract technological agents.
Just because the majority of people, once they are fully programmed by our culture, perceives a growing minority of people (1 in 6) as not fully conforming to cultural expectations, does not mean that there is anything biologically or mentally wrong with these non-conformists. From a sociological and biological perspective the rising numbers of cultural non-conformists may just as well be seen as an indicator of an increasingly sick society characterised by cultural norms that are incompatible with human biological and social needs.
In our globally networked world individual inventors or small teams currently don’t have much if any control over the use of the technologies they create. Anthropocentrism and ignorance of human scale are the social diseases of our civilisation.
These diseases are obvious to most autistic people but they are only just beginning to be recognised by a growing number of people in wider society. Many signs are pointing towards a major cultural transformation based on a significant shift in values of younger generations that have grown up in an environment of continuous exploitation by technological monopolies.
Shifting from exponential growth to thriving life at human scale
Appreciation of collective intelligence
My working definition of intelligence: “finding a niche and thriving in the living world by creating good company, i.e. nurturing trusted relationships.”
In our world there is a silver lining to anything that reduces global – energy and resource hungry – busyness, like the COVID-19 pandemic.
Governments now have a unique chance to switch to a new understanding of economics, i.e regenerative management of resources and waste, that is compatible with human life on this planet – or otherwise to ignore the opportunity and lapse back into suicidal busyness as usual.
Our society could benefit a lot from a permanent cultural shift towards reduced commutes into city centres, from reduced global travel, and from increased levels of remote knowledge work. A pandemic might turn out to be an effective catalyst.
Ideas that are genuinely beneficial for society and the planet are best propagated by the slow and valuable process of knowledge sharing at eye level in Open Space, allowing for critical enquiry, independent validation, refinement where needed, and transmission of essential locally relevant context.
Using tools of persuasion beyond peer-to-peer learning may well become a taboo in the not-too-distant future. Capitalists are starting to trip over their own competitive games, desperate for new ways of remaining relevant in a post-capitalist world. The level of fear is illustrated by this headline: “Data is not the new oil – it’s the new plutonium”.
The vast majority of online social communication tools have been designed to support and promote the propagation of beliefs via the rapid process of influence rather than via the much slower process of evidence based learning and education. We live in a society driven by fear. Always ask who benefits from the fear. Fear can induce panic but it can also catalyse courage.
The cycle of fear can only be broken by the creation and replication of islands of psychological safety. Encouragingly the number of such islands is growing.
If we want to avoid repeating the mistakes of human “civilisations”, the rules for coordinating at super-human scale will have to allow for and encourage a rich diversity of human scale organisations. In a human scale social world, apart from the self-imposed constraint of human scale, there is no universally dominant organisational paradigm.
The resulting web of interdependencies can simply be thought of as “the web of life” rather than “civilisation 2.0”. We must not to again make the anthropocentric mistake of putting humans at the centre of the universe.
Organisations are best thought of as cultural organisms. Groups of organisations with compatible operating models can be thought of as a cultural species. The human genus is the genus that includes all cultural species.
In a transactional world, collective intelligence literally goes down the drain. In my experience, organisations with several thousand staff tend to act less intelligent than a single individual, and as group size grows further, intelligence tends towards zero.
The graph above assumes that as group size increases, people attempt to maintain more and more relationships – which end up deteriorating into transactional contacts with very limited shared understanding. The decline in collective intelligence can be avoided by consciously limiting the number of relationships of individuals, and by investing in trusted relationships between groups.
Hierarchical structures are inherently incompatible with the construction of trusted relationships within and between groups. Anyone who attempts to establish trusted relationships outside the hierarchical tree structure implicitly questions the effectiveness of the hierarchy, and thereby undermines one or more authorities within the structure.
The summary of existential risks in the following video is a good illustration of the full intelligence-destroying effect of hierarchical structures. Note that I don’t agree with the portrayal of the AI risks as being due to “superintelligence” – but I do see big risks. In the video the notion of “intelligence” remains undefined, and comparing different kinds of intelligence is like comparing apples and oranges, there is no linear scale.
If autistic people can’t always see the depth of the “bigger picture” of the office politics around us it does not in any way mean that we don’t see the big picture. In fact we are aware of the big picture and often we zoom in from the biggest picture right down to our immediate context and then back out again, stopping at various levels in between that are potentially relevant to our context at hand. Office politics only distract from the genuinely bigger context. Accusing autistic people of not seeing the bigger picture perhaps illustrates the social disease that afflicts our society better than anything else.
Neurodiversity friendly forms of collaboration hold the potential to transform pathologically competitive and toxic teams and cultures into highly collaborative teams and larger cultural units that work together more like an organism rather than like a group of fighters in an arena.
Time and trusted collaboration are our scarcest resources. The former is a hard constraint and the latter is the critical cultural variable on which our future depends.
We have reached a point where human societies can choose between a “collapse of human ecological footprint” based on a conscious and significant reduction of cultural and technological complexity or an “ecological collapse, including human population collapse” resulting from a perpetuation of the behaviours that are slowly but surely killing us all. Realistically both kinds of collapse will occur in parallel, and some communities may be able to avoid the latter form of collapse to a larger extent than others.
Regardless of what route we choose, on this planet no one is in control. The force of life is distributed and decentralised, and it might be a good idea to organise accordingly.
Learning how to create collaborative environments for small “human scale” groups (good companies) creates a collaborative edge over other companies as no effort is wasted on in-group competition. This in turn significantly reduces the need to spend time on “winning” direct competitions with other companies. What happens instead is that other companies are increasingly intrigued by the company’s capability.
Education is essential. When beliefs that represent evidence based facts are propagated via a critical self-reflective process of education that is at least one order of magnitude slower than the process of social transmission (imitation/copying without any deeper understanding), recipients – to a certain degree – are immunised against influence from those with opinions that contradict evidence based understanding.
Shifting from quarterly results to 200+ year time horizons
Appreciation of endeavours that only deliver results for future generations
The catastrophic bush fires in Australia offer a good illustration of how people collaborate when confronted with the kinds of disasters that global heating will increasingly inflict on our societies.
The contrast between the mutual support that emerges within local communities and the behaviour of the most powerful person in the country is not surprising, but representative of a phenomenon that has been described as “elite panic”.
People are waking up to the fact that faith in leaders is what is likely to lead to the end of our species and countless other species. In the emerging social environment of disillusioned communities and citizens, you can neither buy trust nor investments that deliver a “return on capital”. Those who attempt it actually undermine their credibility and tie themselves to a sinking ship.
We are already much closer to a world without capital than capitalists would like us to believe. In many ways such a new world is much more desirable for most of us than the delusional world of infinite “growth” that we are still being sold.
Human perception and human thought processes are strongly biased towards the time scales that matter to humans on a daily basis to the time scale of a human lifetime. Humans are largely blind to events and processes that occur in sub-second intervals and processes that are sufficiently slow. Similarly human perception is biased strongly towards living and physical entities that are comparable to the physical size of humans plus minus two orders of magnitude.
As a result of their cognitive limitations and biases, humans are challenged to understand non-human intelligences that operate in the natural world at different scales of time and different scales of size, such as ant colonies and the behaviour of networks of plants and microorganisms. Humans need to take several steps back in order to appreciate that intelligence may not only exist at human scales of size and time.
The extreme loss of biodiversity that characterises the anthropocene should be a warning, as it highlights the extent of human ignorance regarding the knowledge and intelligence that evolution has produced over a period of several billion years.
It is completely misleading to attempt to attach a price tag to the loss of biodiversity. Whole ecosystems are being lost – each such loss is the loss of a dynamic and resilient living system of accumulated local biological knowledge and wisdom.
It is delusional to think that humans are in control of what they are creating. The planet is in the process of teaching humans about their role in its development, and some humans are starting to respond to the feedback. Feedback loops across different levels of scale and time are hard for humans to identify and understand, but that does not mean that they do not exist.
A new form of global thinking is required that is not confined to the limited perspective of financial economics. The notions of fungibility and capital gains need to be replaced with the notions of collaborative economics and zero-waste cyles of economic flows.
Human capabilities and limitations are under the spot light. How long will it take for human minds to shift gears, away from the power politics and hierarchically organised societies that still reflect the cultural norms of our primate cousins, and from myopic human-centric economics, towards planetary economics that recognise the interconnectedness of life across space and time?
Rediscovering human potential and finding purpose in life
W.E.I.R.D. stands for Western, Educated, Industrialised, Rich, and Democratic. As long as society confuses homo economicus with homo sapiens we are more than “a bit off course”.
The exploitative nature of our “civilised” cultures is top of mind for many neurodivergent people. In contrast, many neuronormative people seem to deal with the trauma via denial, resulting in profound levels of cognitive dissonance.
Earlier this year I attended an online course on collective trauma, and once the trauma inflicted by the structural constraints imposed by our civilisation was mentioned, many participants had the courage to acknowledge this source of trauma.
The evolution of W.E.I.R.D. cultures can be easily understood from an anthropological perspective or via the social model of disability.
To move forward, we need to align our social operating systems with a more optimistic – and less ideologically constrained – perspective on human potential.
As human interactions are increasingly mediated by digital technologies, this entails acknowledging the ideological inertia of our current technologies. The bias that is baked into many of our technologies transforms all human interactions into a bizarre competitive game of likes, followers, and views.
W.E.I.R.D. societies face a choice between:
(A) Co-designing and embracing a less W.E.I.R.D. digital technosphere that catalyses new forms of collaboration and that actively discourages toxic competitive games.
(B) Officially renaming our species to homo economicus, and relying on W.E.I.R.D. technologies to squash any ideologically inconvenient collaborative or altruistic human tendencies.
In terms of developing a more collaborative social operating system it turns out we don’t have to start from scratch.
Cultural evolution allows human society to evolve much faster than the speed of genetic evolution, which is constrained by the interval between generations. However, within any given society, the vast majority of people only experience a very limited sense of individual agency. Gene-culture co-evolution has led to a mix of capabilities in a group where:
1. The beliefs and behaviours of the vast majority of people are shaped by cultural transmission from the people around them – the majority of people primarily learn by imitation.
2. A minority of atypical people is much less influenced by cultural transmission – this minority learns by consciously observing the human and non-human environment, and then drawing inferences that form the basis of beliefs and behaviours.
The extremely important role that culture has played and still plays in human evolution represents a transformational change in the mechanisms available to evolution – it is a major step in the evolution of evolution, comparable to less than two handful of other major steps such as the emergence of the first cells, the emergence of multi-celled life forms, the emergence of sexual reproduction, etc.
Cultural evolution allows the behaviour of human societies to evolve much faster than the behaviour of other complex life forms, to the point that our collective knowledge and medical technologies allow us to engage in an evolutionary arms race with various strains of microbes that used to represent a serious threat to human health.
Whilst in some domains humans have been able to harness our capacity for culture for the benefit of all humans, in other domains our capacity for culture has been used to establish and operate highly oppressive and stratified societies.
Autistic culture is minimalistic, able to accommodate profound differences in individual cognitive lenses, and it is the source of deep innovation.
Mental health statistics tell us that mainstream culture has diverged too far from autistic culture. In many organisations bullying has reached toxic levels. Trends in mental health statistics in the wider population hint at a problem far beyond the autistic community. Large parts of society are already paralysed by irrational fear of change, i.e. “the system is bad but at least it’s familiar”.
To move forward we need a system of language tools and interaction patterns that allow the people within small groups to increase their level of shared understanding.
The objectives of the autism and neurodiversity civil rights movements overlap significantly with the interests of those who advocate for greater levels of psychological safety in the workplace and in society in general.
In the workplace the topic of psychological safety is relevant to all industries and sectors. Creating and maintaining a psychologically safe environment is fundamental for the flourishing of all staff, yet in most organisations psychological safety is the exception rather than the norm.
Given our first hand experience with innovation in these sectors and our involvement in autistic self advocacy and neurodiversity activism, the S23M team has decided to conduct a global survey on psychological safety in the workplace. The resulting data will be of particular interest for autistic and otherwise neurodivergent people who are experiencing bullying and more or less subtle forms of discrimination at work.
You can assist our effort by participating in the survey, and by encouraging your friends to participate in the survey.
For our journey into the future we need appropriate tools for addressing challenges and needs over different time horizons.
Below is an overview of tools that I have been involved in developing. Many of these tools are available in the public domain and can be accessed free of charge by individuals and small companies. Please get in touch in case you have questions regarding any of these resources.
The 10,000 year project of human civilisation or empire building is coming to an end. Human life as we knew it – shaped by the anthropocentric myths of “meritocracy”, technological “progress”, and “growth” – is less and less compatible with our daily experiences and with the needs of all the people and other living creatures that we care about.
A brief history of the end of the era of human empires
The discovery of Antarctica by Fabian Gottlieb von Bellingshausen and Mikhail Lazarev in 1820 can serve as a useful working definition for the beginning of the end of the “civilised” human “conquest” of the planet. From that point onwards no significant territories remained to be discovered and claimed, and the competition between “civilised” empires increasingly focused on dominating the biggest chunks of the known finite planetary pie of territories, people, and “resources”.
The industrial revolution and the systematic discovery and exploitation of coal and oil reserves provided human societies with new and seemingly endless sources of energy for machine assisted human busyness and material infrastructure development and artefact creation. Like teenagers discovering the growing physical powers of their bodies, entire societies were enthralled by their new found physical powers, and started probing the limits of what is possible, often at the expense of neighbours who had not yet caught the bug of industrialised “progress”, which could very conveniently be quantified in terms of material “productivity” and “efficiency”.
The increasing reliance on energy hungry machines for maintaining and advancing material progress had a major influence on human cultural evolution, leading to the celebration of feats of human engineering and a growing belief in a causal link between mechanisation and “progress”, and an association of machines with “progress”.
The invention of the voltaic cell in 1800 by Alessandro Volta paved the path for the development of electric telegraphy in the 1830s, the telephone a few decades later, and wireless telegraphy and radio in the period of 1890 to 1920. These developments enabled new forms of communication and facilitated further cultural evolution via the quasi-instantaneous propagation of (mis)information to large numbers of people across arbitrary distances.
Enabled by machine power, radio technology, and the hierarchically organised cultural institutions of empires, the human “leaders” of the 20th century triggered the most deadly wars in human history, culminating in the development and deployment of nuclear weapons.
Most people don’t voluntarily sign up for a war with their neighbours, but the rise of mass communication and manipulation technologies proved to be highly effective for propagating superiority myths, and for dehumanising the people of “less advanced” cultures and those who don’t conform to the culturally prescribed template of “normality”.
Since the Cold War empires have increasingly shifted their focus from overt conventional war to economic warfare and psychological warfare. The growing economic power imbalance between the empires of the “developed” world and “less developed” nation states has significantly reduced the need for large scale direct military interventions to maintain imperial power structures. “Civilised” warfare in the 21st century consists of the following components:
Global economic institutions are equipped with the ability to dictate the terms on which nation states with limited financial power are able to engage with the rest of the world (economic warfare).
The reserve banks of states with significant financial power use the dial of interest rates and their ability to issue credit to shape the global economic “climate” (economic warfare).
The financial power of largest transnational corporations exceeds the financial powers of the majority of nation states, and incrementally, the balance of power shifts further from governments towards transnational corporations (economic warfare).
Individuals with significant financial wealth are empowered to wield significant influence over the transnational corporations that they have invested in, and as a result they also wield significant influence over the economic “climate” in many nation states (economic warfare).
Transnational corporations use their financial power (often in combination with local or domain specific monopolistic powers) to bathe entire populations in a never ending stream of PR and marketing messages, assisted by profit oriented media organisations that depend on corporate advertising revenue (economic warfare and psychological warfare).
Whilst the governments of financially powerful nation states are strongly influenced by the financial powers of transnational corporations, they remain the official operators of military power, and use these powers for “surgical” strikes as needed to prevent smaller nation states from ever ignoring the established imperial “rules of the game” (conventional warfare and psychological warfare).
The effects of economic warfare are conveniently indirect but very effective and brutal.
Around one in ten children are born with a low birth weight, and in South Asia, it is one in four, and approximately 45% of deaths among children under five are linked to undernutrition. These deaths often occur in low- and middle-income countries where childhood obesity levels are rising at the same time. Nutrition is the main cause of death and disease in the world. The developmental, economic, social and medical impacts of malnutrition are serious and lasting.
Nine out of ten people breathe polluted air every day. In 2019, air pollution is considered by WHO as the greatest environmental risk to health. Microscopic pollutants in the air can penetrate respiratory and circulatory systems, damaging the lungs, heart and brain, killing 7 million people prematurely every year from diseases such as cancer, stroke, heart and lung disease. Around 90% of these deaths are in low- and middle-income countries, with high volumes of emissions from industry, transport and agriculture, as well as dirty cookstoves and fuels in homes.
Noncommunicable diseases, such as diabetes, cancer and heart disease, are collectively responsible for over 70% of all deaths worldwide, or 41 million people. This includes 15 million people dying prematurely, aged between 30 and 69. Over 85% of these premature deaths are in low- and middle-income countries.
More than 1.6 billion people (22% of the global population) live in places where protracted crises (through a combination of challenges such as drought, famine, conflict, and population displacement) and weak health services leave them without access to basic care.
The effects of psychological warfare can be seen in the dissonance between the narratives that transnational corporations tell about themselves and:
their low contribution to the tax revenues and in some cases their ability to influence tax policies,
the ecological externalities that they create,
the extent to which their activities amount to amplification of economic inequalities via financial speculation that is disconnected from the production and recycling of life sustaining necessities,
their ability to undercut local companies that offer superior services (with less ecological and economic externalities).
Economists estimate that financial speculation amounts to at least 50% of global economic activity.
Tax policies that provide favourable economic conditions for transnational corporations and financial investors have had the following effect:
Between 1990 and 2020, U.S. billionaire wealth soared 1,130 percent in 2020 dollars, an increase more than 200 times greater than the 5.37 percent growth of U.S. median wealth over this same period. Between 1980 and 2018, the tax obligations of America’s billionaires, measured as a percentage of their wealth, decreased 79 percent.
The very concept of economic value creation has been hijacked by the beneficiaries of increasing levels of financialisation in developed economies:
What we value and how we value it is one of the most contested, misunderstood and important ideas in economics. Economist Mariana Mazzucato’s comprehensive “The Value of Everything” explores how ideas about what value is, where it comes from and how it should be distributed have changed in the past 400 years, and why value matters now more than ever. Mazzucato emphasizes the need to reopen debate to make economies more productive, equitable and sustainable. The 2008 financial crisis was just a taste of looming problems — climate disruption, massive biodiversity and ecosystem-services decline, even the possible collapse of Western civilization — unless we learn to value what really matters.
The international System of National Accounts and gross domestic product (GDP) both value economic activity on the basis of market transactions — only goods and services sold in markets are counted. Much of that activity is beneficial, but some is best seen as a cost to be avoided. GDP conflates the two. For instance, growth of crime demands more police and security devices; these add to GDP, but more crime is not desirable. Increases in air and water pollution, serious illness and divorce are all counted as positive in GDP, whereas the distribution of income is ignored, as are the value of household and volunteer work, ecosystem services and community support. As economist and statistician Simon Kuznets, GDP’s main architect, warned, a country’s welfare cannot be inferred from GDP: “Goals for more growth should specify more growth of what and for what.”
Mazzucato argues persuasively that GDP is a “hodge-podge” that “invites lobbying rather than reasoning about value”. She notes that it “justifies excessive inequalities of income and wealth and turns value extraction into value creation”.
The mainstream narrative of conventional, economic, and psychological warfare of course prefers framing of the same activities using the language of defending national interests, economic development, disruptiveinnovation, and achieving economies of scale.
Framing is the key tool for detracting from the many millions of human and non-human casualties.
The underlying common theme across all imperial cultures is the concept of cultural superiority, which results in a sense of entitlement and a perpetual drive to out-compete and over-power groups with different and “inferior” cultures.
The limits of the Western scientific worldview
The notion of life as a competitive game found its way into the science of biology by interpreting Darwin’s theory of evolution through the cultural lens of capitalism. The complementary perspective of life and evolution as a cooperative game as described by Pyotr Alexeyevich Kropotkin in Mutual Aid: A Factor of Evolution in 1902 was largely ignored in “developed” capitalist societies throughout most of the 20th century.
In the capitalist narrative the collapse of the Soviet Union and the economic success of China following Mao’s death are interpreted as evidence for the superiority of capitalism and market based competition over other forms of organising economic activity. In the Western “developed” world, capitalist ideology developed a symbiotic relationship with the science of evolutionary biology, culminating in books such as “The Selfish Gene” by Richard Dawkins in 1975 and in the hyper-competitive interpretations of human nature that are baked into Neoliberal ideology.
For many years evolutionary biologists such as E.O Wilson (sometimes referred to as “the father of sociobiology” and “the father of biodiversity”), Elisabet Sahtouris, and David Sloan Wilson, who where exploring alternative framings and complementary aspects of biological evolution (cooperation in the evolution of social species, multi-level selection theory, and gene-culture co-evolution), did not receive much attention.
Only in the last 20 years have the cooperative aspect of evolution and multi-level selection theory been more widely recognised as a valid theoretical framework for evolution in general, including in the context of gene-culture co-evolution.
In parallel with the growing awareness of the role of cooperation in evolution, critical views of capitalism have become part of the allowable sphere of academic and political discourse in Western “developed” societies, whilst in the “real” world of corporate business the competitive view of economic life still dominates.
Even though Western science likes to think of itself as ideology neutral it is not immune to ideological influence. The Western scientific worldview continues to be plagued by artificial discipline boundaries that significantly slow down the process of transdisciplinary knowledge transfer and the discovery of new insights that remain hidden in the deep chasms between established disciplines.
The ideological influence in Western science is visible in metrics of academic success such as the number of publications in journals and various journal ranking schemes. Academics have to conform to predetermined criteria of success and “productivity” if they want to climb the career ladder in universities and research institutions that are run as profit generating businesses, especially in countries that have fully embraced the Neoliberal ideology.
This (short) talk from 2011 and (longer) interview from 2020 with Elisabet Sahtouris provide a good introduction to a broader and more inclusive framing of evolutionary theory that also acknowledges the value of insights that are part of alternative non-Western frameworks of knowledge and reasoning.
There is a lot to be learned from traditions outside the Western monoculture of busyness. In New Zealand for example, Māori researchers are working towards an Economy of Mana that aims to better provide for Māori aspirations in all realms of life.
In this article I relate gene-culture co-evolution to the role of neurodiversity in human societies from an anthropological perspective, including references to relevant academic literature. Over the last 20 years Western societies have increasingly pathologised neurodiversity and in particular autistic people who do not readily and subconsciously absorb cultural norms from their social environment. I have severe concerns about the pathologisation of people that don’t fit a standardised (and hence fictional) human template. The notion of disability in Western societies is underscored by a bizarre conception of “independence”.
Understanding the superiority complex of empires
It is time to consider the possibility of a social disease and that manifests in sick cultural norms and sick institutions rather than in individual “inmates”. Pretending that there is nothing wrong with our cultural norms and institutions only generates disastrous mental health statistics that deflect from the deeper problems that need to be addressed.
Many scientists are blind to the limits of quantitative techniques. 30 years of working in the capacity of a “knowledge archaeologist” (surfacing tacit knowledge from domain expertise in all kinds of disciplines and making it explicit and validating/refining it in transdisciplinary groups in a form that catalyses shared understanding) have taught me to appreciate the value of visual conceptual models of human knowledge and motivations.
Biologists like David Sloan Wilson and Daniel Christian Wahl have recognised the need for a common language for reasoning about multi-level complex collaborative systems that are subject to evolutionary forces. We need a language to reason about the cultural superiority complex of imperial societies and potential therapies and cures.
Such a language is not only useful in biology, but also in all contexts that relate to human social behaviour and human activity within the context of biological ecosystems at all levels of scale. The formal visual conceptual languages of the MODA + MODE human lens and the ecological lens have been designed specifically for this purpose.
Visual diagrams in the notation of the human lens and the ecological lens
(including less formal concept diagrams that people intuitively produce when collaborating around a whiteboard) for reasoning about multi-level complex collaborative systems work so well because they map directly to the networked and metaphor based structure of our mental models – much more so than the linear language which we speak and write.
The human lens provides thirteen categories that are invariant across cultures, space, and time – it provides an economic ideology independent reasoning framework for transdisciplinary collaboration.
The human lens allows us to make sense of the world and the natural environment from a human perspective, to evolve our value systems, and to structure and adapt human endeavours accordingly.
All 13 human lens concepts reflect foundational aspects of human cognition and the human capacity for symbolic thought within an ecological context, and are found in all cultures under various labels.
The human lens concepts are recognisable in all historic human cultures, and they will continue to be relevant in another 1,000 years – this is what is meant by “economic ideology independent”.
This is important because language is always a contentious topic in a transdisciplinary context, since each discipline uses a different language. The human lens can be used to model all aspects of the relationships between economic agents and all aspects of collaboration within economic agents. Expressed in the human lens, human life at human scale can be described in terms of feedback across levels of scale as follows:
Adding the fiction of homo economicus into the picture yields:
The textual labels I chose reflect my personal bias, but the depicted agents and the links between them simply represent undeniable resource and information flows. Enforcing the ideology of homo economicus has the following effects:
Colour coding the stressed agents and the primary and secondary economic “externalities” produces the following picture:
Using the same colour coding, zooming into capitalised busyness, the actors in the global economic theatre and their roles can be visualised as follows:
Zooming back out to the summary of life at human scale, and visualising the core symptoms of our sick cultures yields:
Humans have been aware of the growing ecological crisis triggered by industrialised societies for more than 60 years. We know and feel what is wrong, but without an adequate language we are not able to pinpoint the most promising leverage points for interventions at a systemic level.
Knowledge distillation, conservation, and transfer
The visual languages of the human lens and the living agent lens are useful for distilling and refining knowledge in a small group environment. Knowledge conservation over long time horizons and effective knowledge transfer to outsiders can be catalysed by the ongoing maintenance of five complementary representations of knowledge:
Collective tacit domain knowledge within a group about a specific domain.
Explicit visual models of tacit knowledge that reflect the results of a SECI knowledge creation spiral in the language of the human lens.
Software tool support for data structures that correspond 1-to-1 to the formal visual models.
Model validation via instantiation in terms of sample information model instances that are easily recognisable by those who contributed their tacit knowledge to the modelling effort.
A document that contains one or more narratives that walks readers who may not have been involved in the modelling effort through the sample model instances. The number of narratives needed depend on the diversity of the sample model instances and the complexity of the domain.
This level of attention to knowledge validation and transfer is rarely achieved in industrialised societies that confuse busyness with productivity, persuasiveness with the “key to personal success”, and consumption with a “high standard of living”. The resulting over-emphasis on persuasive storytelling and the corresponding loss of appreciation of tacit knowledge and models with explanatory power is a major cause for concern.
A few years ago Alan Kay, a pioneer of object-oriented programming and windowing graphical user interface design observed:
It used to be the case that people were admonished to “not re-invent the wheel”. We now live in an age that spends a lot of time “reinventing the flat tire!”
The flat tires come from the reinventors often not being in the same league as the original inventors. This is a symptom of a “pop culture” where identity and participation are much more important than progress. … In the US we are now embedded in a pop culture that has progressed far enough to seriously hurt places that hold “developed cultures”.
My measure of success for S23M, our employee owned company, is tied to a 200+ year time horizon. We strive to create good company for all our team members. If all the pairwise relationships between team members and the relationships with our customers and partners are in good health, then the company is in good health. The company was founded in 2002 and will be successful if it is still healthy and alive in 200 years according to the same criteria.
A few statistics (Wikipedia list of oldest companies) that should provide food for thought for the disciples of Neoliberalism and “sustainable economic growth”:
According to a report published by the Bank of Korea in 2008 that looked at 41 countries, there were 5,586 companies older than 200 years. Of these, 3,146 (56%) are in Japan.
Of the companies with more than 100 years of history, most of them (89%) employ fewer than 300 people.
A nationwide Japanese survey counted more than 21,000 companies older than 100 years as of September 30, 2009.
Last week I was thrilled to read about a company that operates on a 500 year time horizon:
While most companies might plan five years ahead at most, Māori company Kono is looking 500 years into the future. The company wants to be a good kaitiaki (caretaker) of the more than 1000 hectares of land and sea it farms at the top of the South Island. Kono chief executive Rachel Taulelei says the company works intergenerationally and has a “clear responsibility” to ensure its assets and resources will still be here in 500 years. Kono is the food and beverage arm of Wakatū Incorporation, a Nelson company that represents around 4000 owner families, all affiliated to at least one of four iwi at the top of the South Island – Ngāti Rārua, Ngāti Koata, Te Ātiawa and Ngāti Tama.
The above streams of activities and feedback loops map to:
The correspondence is no accident. Software companies that combine deep domain specific expertise with the capability to conduct experiments and a commitment to systematic commonality and variability analysis operate in a quality and productivity league that differs by one or more orders of magnitude from software companies that don’t apply a software product line approach (evolutionary principles) to their work.
What is the significance of the correspondence?
The practical significance of the correspondence is profound, as it provides us with a collaborative framing and terminology for evolutionary processes, including evolution guided by conscious human design, without any reference to the hyper-competitive cultural bias of Neoliberalism or the deeply misguided assumption that competitive markets are the best mechanism for “driving” cultural evolution.
Software product line engineering can be understood as a form of collaborative niche construction.
Human guided cultural evolution
No successful software company would ever organise in terms of competing teams to develop the best possible product. Quite the opposite is the case. Software companies that take a product line approach operate dedicated work-streams and teams for each of the four core activities within the evolutionary process:
experimentation (with variations in implementation technology choices and operational environments to better meet customer needs),
platform engineering (selection of common features that are useful for specific categories/species of customers that use the product line),
product engineering (replication of best engineering practices in the assembly of concrete products for specific customers).
product line operations (sustaining the provision of services to customers and processing feedback from customers).
The members within each team collaborate on a daily basis, whereas the collaboration between the four teams is based on weekly, monthly and quarterly feedback loops.
Open sharing of knowledge in precise notations, creative collaboration with customers, conscious experimental design, and parallel experiments replace information hoarding, deception, social competition, and the not-so-invisible hand of the market.
Successful software products that are used by many thousands or millions of customers are best thought of as a domain specific language system that complements human cognitive abilities and that facilitates and mediates collaboration and/or social competition between humans.
In a networked world with ubiquitous internet connectivity and pervasive use of Internet enabled personal devices software plays a significant role in guiding – or even forcing – human cultural evolution.
Externally, experienced software companies develop fast paced collaborative feedback loops with customers in order to minimise misunderstandings and to gain a deeper understanding of the commonalities and the variabilities of customer needs in specific niches and geographies, which is fed into the evolutionary process that shapes the future scope and functionality of the product line.
Software product design conducted in isolation, without giving customers the ability to shape the design, is a form of social engineering, whether intentional or not.
All users of the Internet are familiar with the social externalities: online social media platforms dictate the possible communication and collaboration patterns, and in doing so may decide to optimise for maximum
“engagement” with their platforms,
“advertising revenue”,
“information extraction” about user preferences,
not in order to serve the needs of users (who may want to collaborate with peers in other locations on topics and problems that matters to their life), but ultimately to maximise the “return on investment” for the owners of the platform in the metrics of success prescribed by the sick Neoliberal paradigm.
The huge opportunities and dangers of mediating human communication and collaboration and/or social competition via software platforms can not be overstated.
The language systems that we create with the help of software can either amplify the unique human capacity for compassion and creative collaboration or they can amplify social competition and the brutal power politics that characterise primate dominance hierarchies.
The COVID-19 pandemic is the latest reminder of how dependent our societies have become on software as an extension of the language system we use on a daily basis. The words we type into our screens may look familiar, but the ways in which they are processed, and who gets to see them and interpret them, are increasingly beyond our control. Similarly the words and images we are fed via our screens have been pre-processed, filtered, arranged, and decorated in ways that are largely beyond our control.
There are huge differences between the software platforms at our disposal. Whilst many software platforms encourage toxic competitive social games other software platforms are the most amazing tools for catalysing specific kinds of collaboration.
As a software platform co-designer (i.e. language system co-designer) I am acutely aware of how the work of specific organisations and teams can be greatly improved for all participants, by finding ways
to reduce misunderstandings,
to catalyse knowledge flows and a greater level of shared understanding,
and to reduce cognitive load by giving users the tools to automate repeating patterns of coordination tasks according to their individual preferences and according to dynamically evolving needs.
There is a fundamental qualitative difference between (a) software platforms that serve the Neoliberal paradigm and (b) software platforms that are operated by employee owned companies and have been co-designed with the communities and organisations that use the software, to catalyse adherence to communally agreed patterns of collaboration, and to automate administrative chores.
Coordinating collaboration at super-human scale
Humans are the local world champions of self delusion on this planet. In particular we are prone to overestimating our ability to understand each other. However, once we appreciate that even our “educated” Western scientific worldview is not free from ideological bias, we can develop a better conceptual model of how individual and collective human belief systems and related bodies of knowledge evolve.
It is helpful to distinguish the following categories of beliefs and related knowledge:
Beliefs based on scientific theories backed by empirical evidence that we are intimately familiar with. Such beliefs may be affected by paradigmatic bias and the quality or bias inherent in the supporting evidence. We need to be cognisant of corresponding blind spots in our understanding of the world when applying such beliefs in our reasoning. Only a small minority of our beliefs fall into this category.
Beliefs based on scientific theories backed by empirical evidence that we are not intimately familiar with. Such beliefs may be affected by paradigmatic bias and the quality or bias inherent in the supporting evidence. We have no idea of the potential blind spots in our understanding of the world when applying such beliefs in our reasoning. In the few cases where the theories have been developed by trusted friends and colleagues within our personal competency network, we can decide to rely on their understanding of the limits of applicability and potential blind spots. If we are “educated”, a sizeable minority of our beliefs fall into this category.
Beliefs based on personal experiences and observations. We know that no human can maintain more than 150 relationships with other people, and that all our assumptions about the lives and needs of humans are based on the very small set of people that we relate to. For those who identify as autistic, a significant number of beliefs held (possibly the majority) fall into this category. By definition, we don’t understand all the people that we “don’t relate to”. Thus, making any decisions that potentially affect the lives of many hundred to several billion people without explicit consent of all those potentially affected (a daily occurrence in government institutions and corporations), must be considered the pinnacle of human ignorance.
Beliefs that represent explicit social agreements between specific people regarding communication and collaboration. Such agreements can be verbal or in writing. Some agreements, such as laws issued by regional or national governments, apply to large groups of people and have been developed with limited input from those who are affected. For those who identify as autistic, a significant number of beliefs held fall into this category, especially agreements with family members, friends, and colleagues.
Beliefs based on what others have told us and what we have been encouraged to believe by parents, teachers, and friends, … and politicians and advertisers, including beliefs that we have absorbed from our social environment subconsciously, i.e. beliefs for which we can’t recall the origin. For those who do not identify as autistic, the majority of beliefs held fall into this category.
All categories of human beliefs are associated with some level of uncertainty regarding the validity and applicability to a specific context at hand. A belief in the universally competitive nature of homo economicus falls into the fifth category. When beliefs related to Neoliberal ideology are reflected in laws (category 4. above), they are internalised as cultural norms by large parts of the population, and when the externalities of hyper-competitive profit maximising behaviour hit with full force, homo economicus has become a self-fulfilling prophecy.
Autistic people can be considered as the cultural immune system of human societies. They are less influenced by socially transmitted and subconsciously absorbed beliefs (category 5). Laws and rules that depathologise autism and protect the rights of neurominorities could go a long way towards re-establishing a healthy cultural immune system within society that is capable of containing and stamping out social diseases such as Neoliberal ideology.
Towards wise societies
Once we concede human human cognitive limits (Dunbar’s number) and the lack of “scientific” evidence based justification for most of our cultural norms, we can begin to grasp the possibilities that open up when we commit to developing a more appropriate set of explicit agreements for communication and collaboration that:
encourage trusted collaboration at human scale (consistent with our scientific understanding of human cognitive limits);
position the prosocial principles as the foundation for all collaboration between different groups (consistent with the available evidence from societies that are effective at managing shared resources in sustainable ways);
encourage the use of creative collaboration and in particular Open Space Technology for co-designing and evolving agreements for communication and collaboration between groups at super-human scale;
encourage the development and evolution of locally, regionally, and globally appropriate Open Source software platforms that serve as a language system for communication and collaboration at all levels of scale, in accordance with locally, regionally, and globally agreed rules and laws.
The Internet allows all scientific knowledge, including related evidence and analytical tools, as well as all explicit social agreements to be shared globally, for mutual learning. The future of “globalisation” is not one of energy intensive global busyness (trade of physical goods and resources) but one of a global knowledge commons that is maintained in perpetuity for the benefit of all current and future human societies.
At (local) human scale, global or national statistical averages about humans and human behaviour become meaningless.
In local and regional systems of knowledge explicit social agreements regarding codes of conduct and personal experiences with specific individuals in the local context are as important as globally applicable evidence based scientific knowledge.
Conversely, at global and national scales, elaborate explicit social agreements for codes of conduct inevitably gloss over locally relevant environmental conditions, and can easily do more harm than good, and the same applies to assumptions that are based on the personal experiences of individuals.
Global agreements for collaboration need to be grounded in evidence based science that relates to our understanding of planetary limits and ecosystem health.
Local cultures that strive to be inclusive and committed to providing for the needs of their neurominorities and other vulnerable minorities will discover that they enjoy a collaborative and creative advantage that optimally equips them to adapt to rapidly changing environmental conditions.
Inclusive cultures catalyse trusted collaboration at a bioregional scale and contribute valuable insights to the global knowledge commons.
It is fitting to conclude this article with a few observations from evolutionary biologist Elisabet Sahtouris:
In 1800 only 3% of the human population lived in cities; their exponential rate of growth shows well over half of us are now in urban areas, and predictions for 2050 have 70% of us living in cities worldwide—a percentage that holds already, and is even higher, in some developed countries. The overall trend is clear and if nation states fail under the burden of our perfect storm of crises, cities will have to play ever more important roles in all aspects of human civilization.
The internal problems cities face now are the same glaring ones facing their nations and their world—joblessness, homelessness, health crises, unequal educational and other opportunities, racial tensions, environmental degradation, energy grid failures, traffic congestion, political corruption and so on. Thirteen of our twenty largest cities globally, as well as far more smaller ones, are coastal. Their sealevel airports, piers and sewage systems, as well as other infrastructure and populations, are directly threatened by climate change, as is already evident.
Our hope lies in the resilience of humanity itself—in the vast array of opportunities for engaging the citizenry of cities in peaceful means of solving their problems and developing resilience in the face of oncoming disasters. Inspiring and building internal cooperation through truly democratic citizen engagement, each city can solve problems and become a healthy partner and role model for other cities.….
To explain my intention for ‘ecosophy,’ let me go back a few decades to tell a personal story. During the first Clinton administration in the early ‘90s, I lived in Washington DC and attended the meetings of the President’s Commission on Sustainability with great interest and hope. At the end of one lengthy debate on whether the commission needed to include economics, when its mandate was only concern with environmental issues, I was fortunate to be given three minutes to address the commission.
As the debate had been heavily weighted against including economics and I had so very little time, I pointed out the etymology of the two words, economy and ecology. Both words come from the ancient Greek word for household: oikos (pronounced ee’ kos, at least in modern Greek). The word ‘economy’ (oikos + nomos = oikonomia) means the rule or governance of the household. The word ‘ecology’ (oikos + logos = oikologia) means the creative organization of the household.
I asked, “How can we talk about only one of the most important aspects of running our human household without the other? The problem is not whether to integrate economy with ecology, but that we have separated them.” I added my hope that they invite a child and a Native American grandmother to their future deliberations—the child to remind them for whom they were working; the grandmother to remind them of the need for wisdom, as well as consideration of future generations, preferably seven of them. That completed my three minutes.
It is in concert with these root meanings of ecology and economy that I give the word ‘ecosophy’ (oikos + sophia = oikosophia) the meaning it would have had in ancient Greece, had it come into use there:
Ecosophy: wisely run household of human affairs or, even more simply: Wise Society
The perfect storm of crises we now face may well prove to be the challenge that drives us into our greatest evolutionary leap. Economy must be made subservient to ecology if we want to continue our life on Earth as a healthy, embedded global human society. Economy based on principles of a conscious universe’s mature ecosystems, including that of our bodies, becomes Ecosophy. We know deep in our hearts and souls that this must be done; all we need is the courage to lead the way for all!
Capitalism, via the construction of abstract tokens as interest bearing debt, maximises the efficiency of the accumulation of abstract tokens, specifically it maximises the accumulation of abstract tokens in the hands of those institutions and individuals that claim to have the “authority” to issue debt and that design the social rules around the transfer, repackaging, and annulment of debt.
As long as access to capital affords individuals the “right” to make decisions that significantly impact on the lives of others, the distribution of debt and ownership rights related to land and means of production in society have a huge influence over the well-being of communities and families. This state of affairs is highly problematic, as all humans have limited cognitive capacity and limited ability to understand the lives and needs of other people.
The more capital an individual accumulates, the more their decisions start to impact the lives of hundreds, thousands, and in some cases millions and billions of people.
At the same time, we know that no human can maintain more than 150 relationships with other people, and that all our assumptions about the lives and needs of humans are based on the very small set of people that we relate to. By definition, we don’t understand all the people that we “don’t relate to”. In our busy civilised and hyper-social lives we come across far more than 150 people (Dunbar’s number). We interact within them on a transactional anonymous basis, and we may read about their lives, but it is impossible for us to fully understand their context, as we have not walked in their shoes from the first day in their lives, and thus lack the experience, the insights, and the tacit knowledge that shapes their unique world-views.
Thus, making decisions that potentially affect the lives of many hundred to several billion people without explicit consent of all those potentially affected, must be considered the pinnacle of human ignorance and is a strong indicator of a lack of compassion.
Of course many societies acknowledge the dangers associated with big social power gradients and like to present themselves as democratic, pointing to regular elections and legislation that is developed by democratically elected representatives, claiming that this allows all citizens to contribute to important decisions that shape the operating model of society. There are numerous problems with this naive claim:
At national, regional, and even municipal level, each elected office holder represents a number of people that far exceeds the human cognitive limit of 150.
In many societies citizens only have very limited ability and opportunity to contribute to discussions and important decisions that will affect their lives beyond the participation in elections every few years.
In most societies immense amounts of decision making powers are concentrated at the national, regional, and municipal levels, and the decision making powers at the level of local communities are quite limited. Social power gradients manifest in pyramidal organisational designs within government institutions and corresponding communication structures.
In a rapidly changing world that is affected by human induced climate change and ecological collapse, elections every few years represent a feedback loop that is far too slow for preventing further damage to the highly complex ecological systems that enable human existence on this planet.
All modern “civilised” societies rely on the construction of abstract tokens as interest bearing debt and related tools (interest rates, government bonds, etc.) as a key means for influencing economic activity within their jurisdiction. This delegates significant decision making powers to small privileged elites who are granted preferential access to financial capital.
Capitalised profit maximising corporations are not subject to democratic governance. Instead shareholders and their representatives have the ability to implement whatever organisational design they deem most appropriate for profit maximisation – usually a pyramidal management structure that treats employees and suppliers as resources to be exploited. Once a profit maximising corporation has acquired a monopoly position in a particular domain, it even treats customers as a resource to be exploited. In most jurisdictions the cost of penalties for ignoring or subverting antitrust legislation is negligible.
Just like in many government organisations the number of employees in corporations often far exceeds the human cognitive limit of 150. As a result not only do shareholders, who are often not employed by the organisation, wield a huge influence, but the appointed top level managers regularly make decisions that affect many hundred or thousands of employees.
The fixation on governance via abstract monetary metrics and controls (debt creation, budget allocation, interest rates, various forms of taxation, tax rates, etc.) leads to extremely over-simplified models of economic activity and contributes to an illusion of control, whilst creating huge blind spots for externalities that can’t be articulated in monetary metrics. Concepts such as the triple bottom line are well meaning but woefully inadequate attempts for shedding light on the blind spots created by the heavy reliance on monetary metrics. Ignorance is not a good foundation for decision making.
An honest analysis of the measurable “achievements” of democratic governance as exemplified in current practices in the so-called “developed” world paints a dim picture of collective human intelligence: human activities have triggered the sixth mass extinction event on this planet, billions of humans are malnourished, our ecological footprint has been unsustainable for several decades, and the climate is changing at a rate that is orders of magnitudes faster than all earlier climatic changes in the history of the planet. And even in the light of all these results, monetary metrics are still used as the foundation for economic discussion and decision making.
The systematic analysis of earlier human “civilisations” (societies with cities, written language, and money) conducted by historian Joseph Tainter shows us that so far all “civilisations” have eventually “collapsed”, i.e. they have resulted in a much less centralised and less resource intensive organisation of human affairs.
For observations on the obsolescence of the current capitalist economic operating system in particular, I recommend listening to this very timely interview with anthropologist David Graeber, the author of Debt, The First 5,000 Years.
“Normal” is like standing on the railway tracks, looking at the coming train and asking how fast it is approaching. – David Graeber
The information age
The history of human civilisations to-date can be described as the information age, in which decisions within human societies are driven significantly by information encoded in written rules and in monetary metrics. The information age predates the invention of digital computers by several thousand years.
The physical manifestation of written language and abstract monetary tokens induces and reinforces an illusion of:
permanence (written words can survive many generations),
universal applicability (written words can be transported across large distances without distortion),
precision (written numbers allow quantification to quasi arbitrary levels of precision), and even an illusion of
shared understanding (via our associative memory familiar written words from unfamiliar people remind us of our personal experiences, and it is easy to forget that others may associate different experiences with the same words).
Written conventions and the fungibility of money equipped “civilised” societies not only with a tool for trade and complex transactions, but also with a tool for storing “value”. The act of quantification of value relies on a tacit consensus amongst the users of an abstract currency. A civilised society allows selfish and unscrupulous people to accumulate money by negotiating hard when selling to strangers and when buying from other strangers. The invention of interest bearing debt offered further “leverage”.
Money can be described as the abstract tool that has allowed humans to extend and scale the dominance hierarchies found in other primate societies to groups of many thousands and millions of people.
Via the reliance on money “civilised” societies actively encourage hoarding of information and resources. In “civilised” societies three types of human behaviour can be observed in the context of economic interactions:
Altruism
Reciprocal altruism
Profit maximisation
Most people rely on one of these three strategies as their default mode of operation when dealing with friends and family, and with a potentially different default mode of operation when dealing with strangers. “Civilised” societies systematically disadvantage altruistic and compassionate people in favour of profit maximisers who are superficially charming and who can get away with creative interpretation of social rules.
Economics can be described as the discipline that attempts to legitimise the behaviour of profit maximisation alongside reciprocal altruism.
It should not really be surprising that to-date all “civilised” societies have eventually ended in collapse. Hoarding of information is not conducive to collective intelligence, and hoarding of resources leads to increasingly resource intensive cultural practices and to a growing ecological footprint.
In our times the close link between information hoarding and resource intensive cultural practices is exemplified by phrases such as:
Web 2.0 is about controlling data
The user [information producer] is the product
Monetisation of data
Data is the new oil
In the heat of civilised busyness it is easy to overlook that fact that money itself is simply abstract data, and that an objective such as “monetisation of data” encourages companies to develop absurd services that don’t serve any human need beyond the aggregation of capital on behalf of those who are obsessed with hoarding money.
Digital computers have accelerated the production of economic inequalities and have led to entire “industries” that attempt to monetise data, and which, in the pursuit of this objective, further increase resource and energy consumption. Bitcoin and similar cryptocurrencies epitomise this trend.
The global Bitcoin network is consuming more than seven gigawatts of electricity. Over the course of a year that’s equal to around 64 TWh or terawatt hours of energy consumption. That’s more than the country of Switzerland uses over the same time period (58 TWh per year). – The Verge, 4 July 2019
Across the board, all “civilisations”, past and present, consist of organised groups of people that are so large that many interactions are “transactions” between people that don’t know much if anything about each other.
Life in “civilised” societies routinely puts people in situations of cognitive overload. People are forced to get used to the stress of transacting with anonymous strangers and are subject to social pressures to conform to norms and demands that have been decided in far away places, by rulers and bureaucrats who have no understanding of the local context in specific parts of their “empire”.
The knowledge age
In contrast to the myths about “human nature” that power civilisations, human babies are naturally inclined to help strangers, without any need for coercion or external “incentives”:
…helping [unrelated] others with simple physical problems is a naturally emerging human behaviour …at fourteen to eighteen months of age, before most parents have seriously started to expect their children, much less train them, to behave pro-socially. …parental rewards and encouragement do not seem to increase infants’ helping behaviour.
Parents take heed: the parental encouragement did not affect the infant’s behaviour at all; they helped the same amount with or without it.
… the infants were so inclined to help in general that to keep the overall level of helping down – so that we could potentially see differences between conditions – we had to provide a distracter activity in which they were engaged when the opportunity to help arose. Nevertheless, in the vast majority of cases, they pulled themselves away from this fun activity – they paid a cost – in order to help the struggling adult.
– Michael Tomasello, Why We Cooperate, Boston Review Books, 2009
Prior to the information age, for several hundred thousand years humans lived in much smaller groups without written language, money, and cities. The archaeological evidence available and also the evidence from “uncivilised” indigenous cultures that have survived until recently in a few remote places point towards an interesting commonality in the social norms of such societies:
The strongest social norms in pre-civilised societies were norms that prevented individuals from gaining power over others.
The key to the social co-operation in complex stateless societies is that they must effectively deal with the “free-rider” problems inherent in groups made up of ego-directed people. Overcoming these collective action problems is essential to understanding the evolution of social complexity in our species. These more successful stateless societies create social organisations that allow individual members of the group to benefit in ways that they cannot in smaller population sizes.
The lack of coercion in complex stateless societies is a key feature of this social phenomenon… unlike leaders in state societies, those in stateless ones do not possess coercive power over others. This is an extremely important observation: the emergence of of complex stateless societies was not a costly process in which the vast bulk of people were forced to give up resources or labor to ego-directed aggrandizers… ad-hoc managerial leadership will emerge to deal with the free-rider problems, on the one hand, and the need to reward co-operators, on the other. This is a kind of leadership created by the group; it is not forced on the group either by aggrandizers or by environmental stresses.
Informal social coercion exists in all stateless societies, and is manifested in taboo, black magic, and so forth. However, stateless societies are notable for their absence of institutionalised elites with power to obligate others without a substantial consensus among the community… power in stateless societies by leaders is ad hoc and granted or withdrawn by the community at large.
…people in small groups create rules and norms to govern the production and exchange of resources, behaviors that makes sustained economic co-production possible. These norms and rules are structured through various kinds of ritual and taboo. These rituals schedule tasks, reward co-operators, and enhance pay-off for prosocial behaviour by all members of the group. They maintain fairness and punish non-co-operators.
…small groups provide a context in which most people know each other. The ability to create social histories of most people and to use these reputations in future interactions is possible in small-group contexts in ways not possible in large groups.
people in successful groups recognise both the individual and the collective advantage of co-operation, and some individuals in the group are willing to absorb some costs onto themselves to maintain norms of fairness in exchange for prestige,
Unfortunately the language used by social scientists, including anthropologists, is biased by our culture, and makes use of terms such as ‘leaders’ and ‘prestige’, which carry some semantics in “civilised” societies that do not apply in pre-civilised societies.
The notion of ‘leadership’ as described in the extract above refers refers to an appreciation for valuable domain specific tacit knowledge and skills, and to the trust that is extended to individuals with empirically validated valuable knowledge and skills.
Similarly the notion of ‘prestige’ described in the extract above refers to individuals who consistently act in altruistic ways and contribute their knowledge in ways that benefit the group, who as a result enjoy the trust of many members of the group.
To date the vast majority of anthropological research ignores the role of neurodiversity in shaping human societies. Social scientists routinely assume neurotypical social motivations when observing and interpreting human behaviours. Taking into account that neurodivergent and especially autistic people may not at all be interested in ‘prestige’ in the sense of social status, but are rather motivated by a strong sense of curiosity and individual agency, allows for a more nuanced interpretation.
Regardless of cultural context, the curiosity and unusual sensory abilities of autistic and otherwise neurodivergent individuals result in deep domain specific knowledge and related specialised skills. Some of the acquired knowledge and skills may turn out to be valuable to society and attract the attention of others. In pre-civilised societies neurodivergent individuals will likely have been recognised as trustworthy carriers of valuable knowledge and competencies, the easily transferable parts of which will then have been preserved and propagated to others via cultural transmission.
In pre-civilised societies valuable knowledge was shared and carefully transmitted to future generations. In the absence of written language the knowledge transmission process involved all senses and intensive interaction between recognised masters and motivated novices.
Great climbers and highly skilled hunters, as well as those that excel in other locally valued domains, are sought out, deferred to, and naturally emerge as influential across a wide range of domains. Such respected individuals are rarely ill-tempered or erratic, and instead they are often renowned for their generosity. This phenomenon occurs even in societies that are highly egalitarian, possessing no formal leadership roles or hierarchy.
… once humans became good cultural learners, they needed to locate and learn from the best models. The best models are those that who seem to possess the information most likely to be valuable to learners, now or later in their lives. To be effective, learners must hang around their chosen models for long periods and at crucial times. Learners also benefit if their models are willing to share nonobvious aspects of their practices, or at least not actively conceal the secrets of their success.
… humans reliably develop emotions and motivations to seek out particularly skilled, successful, and knowledgeable models and then are willing to pay deference to those models in order to gain their cooperation, or at least acquiescence, in cultural transmission. This deference can come in many forms, including giving assistance, gifts and favours, as well as speaking well of them in public.
The extract above underscores that autistic individuals will likely have played a key role in knowledge transmission, as they tend to be the ones who are incapable of keeping hidden agendas and consistently ‘willing to share nonobvious aspects of their practices’ with others.
Literally hundreds of experiments in dozens of countries using a variety of experimental protocols suggest that, in addition to their own material payoffs, people have social preferences: subjects care about fairness and reciprocity, are willing to change the distribution of material outcomes among others at a personal cost to themselves, and reward those who act in a pro-social manner while punishing those who do not, even when these actions are costly.
Initial skepticism about the experimental evidence has waned as subsequent experiments with high stakes and with ample opportunity for learning failed to substantially modify the initial conclusions.
This shift in the view of human motives has generated a wave of new research. First, and perhaps most important, a number of authors have shown that people deviate from the selfishness axiom and that this can lead to radical changes in the kinds of social behavior that result. For example, Fehr and Gächter (2002) have shown that social preferences leading to altruistic punishment can have very important effects on the levels of social cooperation (Ostrom et al. 1992).
… once culture gets off the ground it enables adaptation to new niches, situations, climates, and ecologies in a vastly more efficient way than can be achieved by ordinary natural selection… Societies with culture… quickly adapt to circumstances of any kind, … without waiting for the cumbersome process of natural selection to do its work.
The combination of neurodiversity and the human capacities for collaboration and cultural transmission that defined the knowledge age enabled humans to thrive for many hundred thousand years in a diverse range of circumstances – until humans invented the ingredients of “civilisation”, which, via the introduction of written language and money, shifted attention away from valuable knowledge to the accumulation of social power.
Whereas pre-civilised societies appreciated the talents of autistic and otherwise neurodivergent people, the tools of “civilised” societies provide irresistible opportunities for ego-directed aggrandizers, which I am tempted to describe as “human primates” who are only interested in the acquisition of social power and related status symbols.
The knowledge age 2.0
“Civilisation” can be thought of as a social operating system that is afflicted by a collective learning disability induced by primate dominance hierarchies, which dampen feedback loops and flows of valuable knowledge. The result is a cultural inertia that perpetuates social power gradients and that discriminates against the discoverers of new knowledge that might undermine established social structures.
The exciting aspect about the human capacity for culture is that via a series of accidental discoveries and inventions, we have created a global network for sharing valuable knowledge, as well as opinions and misinformation. It apparently takes a virus like SARS-CoV-2 to put this network to good use, and to shift “civilised” cultural norms away from profit maximisation and back towards sharing knowledge for collective benefit.
I’ll hand over to one of my autistic peers for a synopsis:
It is fascinating to notice that SARS-CoV-2 has very rapidly induced cultural changes that affect the foundations of “civilisation”:
Cities – explicitly designed to facilitate rapid sequences of human interactions in anonymous contexts, have been forced to adopt and enforce rules for physical distancing and limiting social interaction.
Written language – when used as a tool for propaganda and distortion, now contributes to the spread of the virus, and yet can play a critical role when used for sharing valuable knowledge.
Money – when used as a tool to protect social power gradients and profits, now has become a negative indicator that signals a lack of trustworthiness.
It is clear that the future of human societies now critically depends on cultural evolution of these foundations. Concepts such as cities and written language as well as quantitative metrics may survive, but their scope of applicability and the operational rules and rituals associated with them may be transformed to such an extent that we will invent new words to clearly distinguish between the old semantics of the information economy and the new semantics of the emerging knowledge age.
In a world increasingly not only connected by trade in goods, but also by exchange of violence, information, viruses, emissions, the importance of social preferences in underwriting human cooperation, even survival, may now be greater even than it was amongst that small group of foragers that began the exodus from Africa 55,000 years ago to spread this particular cooperative species to the far corners of the world.
Planetary intelligence is achieved by creating a feedback loop of mutual learning between the rapid learning cycles (mutations) of viruses and learning cycles at human scale, which are now amplified via a global digital network at super-human scale. Humans are learning the hard way that messing with that network for misinformation and attempts of hierarchical control works against humans and the entire planetary ecosystem.
Once ego-directed aggrandizers with “leadership aspirations” are again recognised as the biggest threat to society, our capacity for culture may again make us more intelligent than the other primates. We can reorient towards a kinder human scale world that nurtures a global knowledge commons and that celebrates mutual aid.
As China battles one of the most serious virus epidemics of the century, the impacts on the country’s energy demand and emissions are only beginning to be felt.Electricity demand and industrial output remain far below their usual levels across a range of indicators, many of which are at their lowest two-week average in several years. These include:
Coal consumption at power plants was down 36%
Operating rates for main steel products were down by more than 15%, while crude steel production was almost unchanged
Coal throughput at the largest coal port fell 29%
Coking plant utilization fell 23%
Satellite-based NO2 levels were 37% lower
Utilization of oil refining capacity was lowered by 34%
At their peak, flight cancellations were reducing global passenger aviation volumes by 10%, but the sector appears to be recovering, with global capacity down 5% on year in February as a whole.
All told, the measures to contain coronavirus have resulted in reductions of 15% to 40% in output across key industrial sectors. This is likely to have wiped out a quarter or more of the country’s CO2 emissions over the past four weeks, the period when activity would normally have resumed after the Chinese new-year holiday. (See methodology below.)Over the same period in 2019, China released around 800m tonnes of CO2 (MtCO2), meaning the virus could have cut global emissions by 200MtCO2 to date.
The potentially bad news (also via Carbonbrief.org):
The key question is whether the impacts are sustained, or if they will be offset – or even reversed – by the government response to the crisis.
However, the Chinese government’s coming stimulus measures in response to the disruption could outweigh these shorter-term impacts on energy and emissions, as it did after the global financial crisis and the 2015 domestic economic downturn.
Governments now have a unique chance to switch to a new understanding of economics, i.e regenerative management of resources and waste, that is compatible with human life on this planet – or otherwise to ignore the opportunity and lapse back into suicidal busyness as usual.
Our society could benefit a lot from a permanent cultural shift towards reduced commutes into city centres, from reduced global travel, and from increased levels of remote knowledge work. A pandemic might turn out to be an effective catalyst on multiple levels:
“Don’t try and predict, just think about preparation from your business side, I know we’re doing this at the Reserve Bank. Folks, liquidity is probably going to help, so talk to your bankers and make sure they don’t start sucking that away from you. And bankers, be long-term and be hard thinking about this sort of stuff. These events are always going to happen, it’s just this year’s activity and, who knows, it’s probably not the only one this year. So all businesses should always have that preparation. The Reserve Bank is also doing a lot of mahi in the background around what low or negative interest rates would mean for the New Zealand economy. Can banks do a negative number if it was a small negative interest rate? Now, all of this is preparation, it’s not a prediction.”
Ideas that are genuinely beneficial for society and the planet are best propagated by the slow and valuable process of knowledge sharing at eye level in Open Space, allowing for critical enquiry, independent validation, refinement where needed, and transmission of essential locally relevant context.
We can’t engineer a society through memetics the way a biologist might hope to engineer an organism through genetics. To do so would bypass our higher faculties, our reasoning, and our collective autonomy. It is unethical, and, in the long run, ineffective. It’s also deliberately antihuman.
Sure, well-meaning and prosocial counterculture groups have attempted to spread their messages through the equivalents of viral media. They subvert the original meanings of corporate logos, leveraging the tremendous spending power of an institution against itself with a single clever twist. With the advent of a new, highly interactive media landscape, internet viruses seemed like a great way to get people talking about unresolved issues. If the meme provokes a response, this logic argues, then it’s something that has to be brought to the surface.
The vast majority of online social communication tools have been designed to support and promote the propagation of beliefs via the rapid process of influence rather than via the much slower process of evidence based learning and education. We live in a society driven by fear. Always ask who benefits from the fear. Fear can induce panic but it can also catalyse courage.
The cycle of fear can only be broken by the creation and replication of islands of psychological safety. Encouragingly the number of such islands is growing.
Collaboration at human scale
Even though I mention the concept of human scale in many of my articles, I have my doubts about how many readers take the time to think through the full implications of living in super-human scale societies.
My hope is that the COVID-19 pandemic triggers a shift in awareness and sensitivity to the extreme risks generated by our attempts to operate super-human scale institutions and systems using organisational designs that provide a small minority of individuals with enormous social powers – often orders of magnitudes beyond individual human cognitive limits, severely constraining the individual agency of the vast majority of people – thereby reducing our collective intelligence correspondingly by orders of magnitude.
“Study after study confirms that most people have about five intimate friends, 15 close friends, 50 general friends and 150 acquaintances. This threshold is imposed by brain size and chemistry, as well as the time it takes to maintain meaningful relationships”, Robin Dunbar says. – Scientific American, September 2018
These numbers guide my thinking on human scale and have shaped the NeurodiVenture operating model that limits the size of good company to 50 people, which in the case of S23M is enforced by our company constitution. The NeurodiVenture model is closely aligned with observations made by E. F. Schumacher in his 1966 essay on Buddhist economics and his book Small is Beautiful.
Larger organisations that contain structures of command and control are not only learning disabled, they are also also detrimental to mental health and trusted collaboration.
The NeurodiVenture operating model not only raises neurodiversity as a top level concern for good company, but by imposing a hard limit on group size, it also ensures that every member of the team has spare cognitive capacity for building and maintaining trusted relationships with the outside world. It is a good idea for every member to maintain some of their 50 general friend relationships with people in other companies.
Let’s assume on average every member has 10 general friend relationships with people in other companies. Then collectively a good company can maintain a very impressive number of strong trusted relationships with other good companies. For example a company of 40 people would have a mind-boggling capacity of up to 40 * 10 = 400 general friend relationships with other companies. The important observation here is that we are talking about genuine and trust based relationships between people and not about superficial and untrusted transactional interactions. Collaborating in good company, even across the organisational boundary, is genuinely enjoyable!
In order for individuals to collaborate effectively and in order to effectively coordinate activities across the organisation it makes sense for emergent groups of regular (daily) collaborators to be given recognisable labels – the result is a structure of teams. A theoretical debate over whether teams should be allowed to overlap completely misses the point. What matters is that high performing collaborative teams tend to have 7 +/- 2 members.
Within a good company (smaller than 50 people) and especially within a team, everyone is acutely aware of the competencies of all the other members. In a NeurodiVenture all members expose (write down and share) these so-called individual competency networks for the benefit of everyone within the company. Transparency of all individual competency networks for the benefit of everyone within the company is perhaps the most radical idea within the NeurodiVenture model. Transparency of individual competency networks enables meta knowledge (who has which knowledge and who entrusts whom with questions or needs in relation to specific domains of knowledge) to flow freely within an organisation.
I could compile a much longer list of advantages of the NeurodiVenture operating model supported by 8 years (and counting) of operating experience, but many of these advantages are simply corollaries of the cognitive limits highlighted by Dunbar’s research.
Learning how to create collaborative environments for small human scale groups (good companies) creates a collaborative edge over other companies as no effort is wasted on in-group competition. This in turn significantly reduces the need to spend time on “winning” direct competitions with other companies. What happens instead is that other companies are increasingly intrigued by the company’s capability.
Collaboration at super-human scale
In a super-human scale social world that is increasingly toxic for individual mental and physical health, a diversity of human scale paradigms will eventually crowd out the super-human “global” / “national” / “mega-city” scale paradigm that dominates today.
Agency at super-human scale is an emergent phenomenon that can not be attributed to any specific individual. Living within “civilisation” we are surrounded by super-human scale structures and it is difficult for most people to imagine collaboration at human scale without being embedded in some bigger hierarchical system.
If we want to avoid repeating the mistakes of human “civilisations”, the rules for coordinating at super-human scale will have to allow for and encourage a rich diversity of human scale organisations. In a human scale social world, apart from the self-imposed constraint of human scale, there is no universally dominant organisational paradigm.
The resulting web of interdependencies can simply be thought of as the web of life rather than “civilisation 2.0”. We must not to again make the anthropocentric mistake of putting humans at the centre of the universe.
Organisations are best thought of as cultural organisms. Groups of organisations with compatible operating models can be thought of as a cultural species. The human genus is the genus that includes all cultural species. The NeurodiVenture operating model is the social DNA of an emergent cultural species that has developed an immune system that enables it to survive and even thrive in three complementary contexts:
within super-human scale societies afflicted by terminal cancer
within social environments that contain a growing number of NeurodiVentures
within social environments that contain other human scale cultural species within the human genus
Each human scale cultural organism represents an aggregation of agency that manifests itself in individual relationships and interactions across the organisational boundary. In a non-hierarchical cultural organism there is no single individual that “leads”, instead external representation and decision making of the cultural organism is distributed across all the individual relationships between the cultural organism and other cultural organisms.
Shocks to human social systems like the COVID-19 pandemic are catalysing a transformation from extremely brittle super-human scale structures towards human scale structures that are understandable from within human cognitive limits. We will have to get used to the fact that super-human scale structures are the products of bio/cultural ecosystem evolution rather than the imagined products of individual human ingenuity or human “leadership”. Remember, on this planet no-one is in control.
The following two articles offer further observations on the co-ordination of activities at super-human scale:
Evolution of social ecosystems – This article illustrates that we are already much closer to a world without capital than capitalists would like us to believe. It introduces a visual non-linear language system for reasoning about collaboration beyond human scale. The article also examines the differences between human scale cultural species and super-human scale “civilised” societies in terms of collective intelligence, and the differences between modern emergent human scale cultural species (like NeurodiVentures) and prehistoric human scale cultural species in terms of language systems and communication technologies.
Autistic collaboration for life – This article dives deep into interactions between NeurodiVentures and other human scale organisations. Many details are described with the help of compact formal visual concept graphs. I intend to unpack the implications in less compact narrative form in future articles.
Catalysing cultural transformation
Human capabilities and limitations are under the spot light. How long will it take for human minds to shift gears, away from the power politics and hierarchically organised societies that still reflect the cultural norms of our primate cousins, and from myopic human-centric economics, towards planetary economics that recognise the interconnectedness of life across space and time?
The future of democratic governance could be one where people vote for human understandable open source legislation that is directly executable by open source software systems. Corporate and government politicians will no longer be deemed as an essential part of human society. Instead, any concentration of power in human hands is likely to be recognised as an unacceptable risk to the welfare of society and the health of the planet.
Language frames people’s thoughts and emotional response. The best we can do is to consciously use language that broadens our perspective to include all living agents within the biosphere.
Niche construction and symbiosis rather than competition – to create organisations and services that are fit for purpose and valued by the wider community
Company rather than business – to focus on the people and things we care about rather than what is simply keeping us busy
Values rather than value – to avoid continuously discounting what is priceless
Physical waste rather than wealth – to focus us on the metrics that do matter
Human scale and individual agency rather than large scale and growth – to create structures and systems that are understandable and relatable
Competency networks and catalysts rather than leadership and leaders – to get things done and distribute decision making to where the knowledge resides
Coordination rather than management – to address all the stuff that can increasingly be automated, management is often the biggest obstacle to automation
Creativity and divergent thinking rather than best practices – when facing the need to innovate and improve
For humans it is not possible to reason about the Anthropocene entirely without human bias. The best we can do is to consciously use language that broadens our perspective to include all living agents within the biosphere.
Burning fossil fuels
The catastrophic bush fires in Australia offer a good illustration of how people collaborate when confronted with the kinds of disasters that global heating will increasingly inflict on our societies. On the one hand, from Love and respect shine though in a time of crisis (5 January 2020) :
The fires leave terrible destruction in their wake, but they also leave deeper human bonds…
You might imagine that, at a time like this, people would become selfish, trying to protect their own place; worried about how their own sheds and homes and stock will emerge.
I’ve seen little evidence of that. Instead, every moment seems to be spent worried about someone else.
When it comes to political clumsiness, the Prime Minister’s Hawaiian holiday was hard to top. But the Liberal Party advertisement released late yesterday, as dozens of communities faced horror bushfire conditions, came close.
The ad shows Scott Morrison in the field, taking charge (angry locals refusing to shake his hand are nowhere to be seen). Firefighters battle the flames with abundant support from Defence Force personnel and aerial assets. The Federal Government’s contributions are proudly listed in on-screen text. Uplifting background music instils confidence that this is a man with a plan.
There will no doubt be debate as to whether this is indeed a party political advertisement capitalising on the disaster, or simply an effort to disseminate information.
But when it walks like a duck and quacks like a duck …
The contrast between the mutual support that emerges within local communities and the behaviour of the most powerful person in the country is not surprising, but representative of a phenomenon that has been described as “elite panic”. From Disarm the lifeboats (4 January 2020) :
Disaster experts can predict how most people will react: Most will try to work together to save the most people possible. As Erik Auf Der Heide, a leading disaster expert with the Centers for Disease Control and Prevention, has written, “antisocial behaviors are uncommon in typical disaster situations.” I’ve observed this myself, in natural disasters in places as different as Haiti and Staten Island, for almost all people.
But there is a notable exception. The richest people on the ship are the least likely to cooperate. There is a formal term for this, based on a 2008 paper by the sociologists Caron Chess and Lee Clarke. It’s called “elite panic.” As Rebecca Solnit has written, “Elites tend to believe in a venal, selfish, and essentially monstrous version of human nature.” And as such, they believe that only “their power keeps the rest of us in line.” If the ship—or human society—is disrupted, they think, “our seething violence will rise to the surface.”
People are waking up to the fact that faith in leaders is what is likely to lead to the end of our species and countless other species. Translated from this article:
A society based on cunning, on people who deceive others
The “business” is hidden for the majority of people, but it is business of companies that have grown at an unprecedented speed. So you end up with a problem: you have a society based on cunning, on people who deceive others. With such a model of society, we should not be surprised at having become unable to solve the real problems. We are now disconnected from reality.
We do not deal properly with the issue of climate change. We do not deal properly with the issues of peace, war, immigration, food resources, water resources, public health, and all these important issues. We became incompetent because society as a whole began to focus on how to deceive and trick people.
– Jaron Lanier, VR technology pioneer, 2019
In the emerging social environment of disillusioned communities and citizens, you can neither buy trust nor investments that deliver a “return on capital”. Those who attempt it actually undermine their credibility and tie themselves to a sinking ship.
Oil was the engine of growth in the twentieth century, then for a little while, data was considered to be the new oil, and now, as the “externalities” of 100 years of oil based economics manifest in personal experiences, we can conclude that oil is the new data.
Burning capital
We are already much closer to a world without capital than capitalists would like us to believe. In many ways such a new world is much more desirable for most of us than the delusional world of infinite “growth” that we are still being sold.
In fact, investment capital has become a negative signal:
The more capital someone has, the less trustworthy they are.
A venture that depends on external investors is less trustworthy than a venture that does not depend on external investors.
Patents and other forms of proprietary intellectual property are increasingly recognised as tools for growing capital, which reduces the trustworthiness of all ventures that rely on proprietary intellectual property for generating profits for investors (see Telsa‘s attempt to remain credible).
People increasingly recognise philanthropy as attempts by capitalists to distract from the externalities caused by their investment activities and to artificially enhance their reputations, and indirectly to enhance the value of their investments.
The way forward will increasingly involve:
Negative interest rates, to provide capitalists with (a) a less-toxic tool for disposing of capital, (b) time to re-learn how to develop trust based relationships, and (c) integrate into new emerging social structures that operate on zero capital. Negative interest rates are already a reality today, and they will become more and more common.
The resulting web of interdependencies can simply be thought of as the web of life rather than “civilisation 2.0”. We must not again make the anthropocentric mistake of putting humans at the centre of the universe.
Related initiatives
The Aut Collab community welcomes all individuals and groups who fully appreciate the value of neurodiversity. Aut Collab acts as a hub for mutual support and encourages neurodivergent individuals to connect and establish inclusive non-hierarchical organisations. Over the last two decades it has become clear that autistic cognitive lenses are an essential element in all human societies, especially in the context of innovation and in terms of reducing spurious complexity in human culture. It is time to liberate autism from the pathology paradigm. Autistic people are often noted for their their honesty, their naivety, and their inability to be exploitative. The lack of self-promotional ability is typically at odds with cultural expectations.
The P2P Foundationis a non-profit organization and global network dedicated to advocacy and research of commons-oriented peer to peer (P2P) dynamics in society. P2P is an abbreviation of “peer to peer”, sometimes also described as “person to person” or “people to people”. P2P is a process or dynamic that can be found in many communities and movements self-organising around the co-creation of culture and knowledge. Well known general examples include the free/open source software movement; free culture; open hardware; and open access in education and science.
The Post Growth Instituteis an international organisation accelerating the world’s shift to a society that thrives within ecological limits. ‘Post-growth’ is a worldview that sees society operating better without the demand of constant economic growth. It proposes that widespread economic justice, social well-being and ecological regeneration are only possible when money inherently circulates through our economy. In all its forms, the dominant economic system – capitalism – is committed to economic growth. Ongoing economic growth threatens our survival as a species. Transitioning to a post-growth economy represents our best option in response to the threat of social and ecological collapse.
The Degrowth web portal is a learning resource on degrowth as a social movement and as a theory. By ‘degrowth’, we understand a form of society and economy which aims at the well-being of all and sustains the natural basis of life. To achieve degrowth, we need a fundamental transformation of our lives and an extensive cultural change. The current economic and social paradigm is ‘faster, higher, further’. It is built on and stimulates competition between all humans. This causes acceleration, stress and exclusion.You can find answers to the question “What is degrowth?”, search for audio, video and text materials in our library, learn about the current projects and the past and next international Conferences on Degrowth, or get involved in many different ways.
Globally, governments are still in the early stages of exploring a transition to new non-fossil fuel economies. Currently the global economy including agriculture, and horticulture are heavily dependent on fossil fuels, and there is a very high risk that political compromise will delay the end of outmoded practices. The integral role that fossil fuels play in the current global economy cannot be overstated, and any significant reduction in their role will result in a total remodelling of economic indicators. What is more, the close correlation of economic growth, and the implicit assumptions relating to positive GDP data, are seriously problematic when seeking to mitigate anthropogenic climate change and environmental degradation.
Given the urgency to reduce greenhouse gas emissions to limit self-reinforcing climate feedback loops, even a 2 or 3 year delay before embarking on a path of drastic emissions reductions may lead the climate into a territory where any attempts to limit the average temperature rise to 2°C, or less, become futile.
In order to mitigate the risk that humanity will not move fast enough to avoid social and environmental crises, we must prepare ourselves by concentrating on our ability to adapt, which in turn is dependent on our ability to explore a broad range of potential climate change scenarios and a broad range of possible mitigation pathways.
From a scientific perspective, based on the data available and the observable trends, actions to de-carbonise the economy which are framed with a 2050 deadline are inadequate. Firstly, the time frame is not aggressive enough to prevent potentially catastrophic levels of warming, and secondly, given the complexity of the climate there is also an urgent need for actions based on the precautionary principle.
Scientific uncertainty is not a justification for government to take a light regulatory approach when voters and their entire ecosystem face such existential moral hazard. In the same way that no one would allow their children to board an airplane if the risk of a deadly crash would be 10% (or even 0.1%), we should not have blind confidence in our collective ability to de-carbonise the global economy in time to prevent severe climate changes.
Adaptation actions must consider scenarios of at least 4-6°C of warming by 2100 and the likely consequences of such levels of warming in terms of threats such as:
sea level rise, ocean acidification, and the salination of freshwater aquifers,
impact on agriculture and food production,
the spread of diseases, and the human and animal health risk of temperature increases,
increases in extreme / catastrophic weather events,
limits to the ability of local communities to cope with these consequences.
Preparing for adaptation to severe climate change must seriously consider the risk of social collapse at local, regional, national, and even transnational levels. In a global economy, when a major climate-induced social collapse occurs, we can not assume smooth continued operation of local or global economic and financial systems. Furthermore any de-carbonisation initiatives that depend on concepts such as financialised emission trading schemes may turn out to be ineffective.
These risks underscore the need for a climate change modelling tool chain that assists domain experts from various disciplines, as well as policy designers, to systematically and with relative ease explore, and communicate a broad range of options to reduce the risk and to contain the impact.
At the moment, the way we respond and adapt to climate change impacts is not well coordinated or communicated. Many of the risks, impacts and actions to adapt are dealt with across a number of different legislative and regulatory regimes.
There are gaps in our information. We have some knowledge about the physical impact of sea-level rise on our coastlines and communities but we currently don’t know much about the impact that rising seas and temperatures will have on economic and ecological systems. We also do not know what the impact of ongoing extreme weather events would be on production in the primary sector. Together these impacts could seriously disrupt current geographical, geological and meteorological advantages enjoyed by certain economic sectors.
We do not fully understand the ecological interdependencies related to the acidification of the oceans and the potential collapse of the complex food chain dependent on phytoplankton, and the oxygenation of the seas and atmosphere. We do not know if we are approaching a tipping point in ocean temperatures brought about CO2 absorption and rising acidification. We do not fully understand the water cycle and how the eutrophication of oceans and the salination of waterways interact with freshwater aquifers, impacting water resources and land-based food capacity.
There is more work to do to understand the possible impacts on our health, biodiversity and culture beyond the traditional timescales projected by economists, statisticians and politicians. A new transdisciplinary approach to climate change mitigation is needed to take precautions against the worst impacts that could affect all aspects of human societies, both locally and globally.
Exploring climate change mitigation and adaptation
Economic assumptions are never neutral and this is especially true of GDP and growth expectations that can hide equity costs within pricing markets on 10, 50, and 100 year timescales. The assumptions made in any economic models must also be explicit about equity issues and the level of commitment to achieve specific equity targets.
An evidence-based approach must be based on known patterns of physical resource flows and resource demands, and on explicit assumptions about changes to these patterns due to the need for climate change mitigation, and will, therefore, promote well informed political debate.
Climate change mitigation and adaptation is a complex transdisciplinary challenge. Any potentially useful modelling tool chain must be able to take into account the following constraints and limitations:
The reality of human cognitive limits, including the limits of quantitative methods, the limits of qualitative methods, and the limits of language.
The influence of ideologies and cultural norms on human behaviour, in combination with cultural inertia.
Changes of government and potentially significant changes in climate change related policies every few years.
The growing likelihood of extreme weather events of new levels of severity and the effects on agricultural production, economic infrastructure, and human lives.
The potential failure to limit local and global temperature increase to 1.5ºC or 2ºC even within the next 20 years.
The potential breakdown of established economic ideology due to local and global climate disasters within the next 20 years.
The need to rapidly reduce the ecological and energy footprint of human civilisation, and the level of incompatibility of reduced resource consumption with the established economic ideology.
The human potential, creativity, and resilience that can be unlocked by trusted collaboration at human scale.
The potential need to replace established financial economic paradigm with a viable resource and waste based alternative on short notice, and the ability to iterate on economic paradigm in order to adapt to rapid climate change and to deal with acute ecological disasters.
A modelling and simulation tool chain that does not consider the above constraints and possibilities will be of very limited use for the exploration of climate change mitigation and adaptation pathways, and will not be able to assist policy designers and implementers.
The S23M team envisages a modelling framework and a tool chain design that assists modellers, policy designers, policy implementers, the public, and industry representatives from all economic sectors to incrementally learn from each other about the unfolding reality of climate change, the changing social and economic support needs of local communities, and the need to invest in new types of economic infrastructure that are of strategic importance for our collective ability to adapt to climate change.
Uncertainties around climate and social norms
Just as the world wars wreaked havoc on society and the environment, the climate crisis creates a similar disjuncture with the past. The future of human societies is going to be dominated by two broad trends that are already visible now.
Increasing numbers of climate related increasingly severe weather events (severe rainfalls and flooding, cyclones and coastal erosion, heat waves, droughts, etc.), and downstream effects on agricultural production and ecosystem functions. The inherent level of uncertainty around the rate at which global temperatures will continue to rise and the rates at which national economies will be able to rapidly reduce green house gas emissions leads to a corresponding level of uncertainty around the frequency and magnitude of future severe weather events.
Increasingly levels of climate change related anxiety in the population, which may rise to the surface following severe weather events or disasters, leading to rapid shifts in social norms (financial economic growth is no longer the main or only target of economic policy, etc.). Further changes in social norms are inevitable, but the timing is impossible to predict – leading to significant uncertainty about future climate change mitigation related goals and legislation.
This means that classical financial economic modelling techniques and metrics such as GDP are no longer useful for assessing the impact of climate change and for assessing the cost of climate change mitigation actions. Whilst we can’t predict the future, we do know that the future will not be a continuation of historic economic trends, and it may also not be influenceable in any adequate way via classical economic tools such as interest rates, tax rates (carbon tax, etc.) and market mechanisms (emissions trading schemes, etc.).
Instead, going forward, national and local governments are well advised to rely on the development of agent based models using the resources, events, and agents (REA) paradigm to combine:
available physical climate models,
available scientific data about local bioregions and microclimates,
available data on historic and current regional economic activities categorised by sectors and industries, measured in physical quantities of resources (kg) and goods (quantities of specific categories of goods),
with the tacit knowledge of subject matter experts and local practitioners in relevant disciplines.
REA models of resource flows and economic activity can be developed and validated incrementally by groups of subject matter experts, both at the macro level as well as at the regional (meso) level, and they can serve as a formal foundation for agent based simulations of economic activities in combination with a range of very different climate change and climate change mitigation scenarios.
This approach allows modellers to run simulations that take a precautionary approach in relation to the uncertainties around severe weather events and around shifts in social norms outlined above. The REA data resulting from the simulations can be translated from physical metrics into local monetary metrics based on the different assumptions about social norms and economic rules that underpin the various simulation runs.
The resulting portfolio of possible climate change mitigation scenarios, including formal representations of all the assumptions about future social norms and economic rules, provide policy designers with a tool box for educating politicians and the public about the available options and associated investments in specific climate change mitigation and adaptation activities.
A growing number of researchers and practitioners are working on resource based accounting methods, and some are already working on the development of regenerative economic ecosystems at a bioregional level that are specifically designed for resilience against climate change.
An economic ideology independent reasoning framework
Preparation for potentially severe climate change and economic disruption is only possible with the help of economic and ecological modelling and simulation tools that don’t make implicit (hard-coded) assumptions about the way economic systems work. In this context financial economic modelling techniques are at best inadequate if not useless.
Over a period of 30 years and longer significant shifts in economic ideology are inevitable in order to adapt effectively to changes in climate, to the effects of increasingly extreme weather events, and to related social challenges.
Governments need suitable multi-dimensional economic and ecological modelling tools for reasoning about human collaboration and resource flows at various levels of scale that can be configured on demand, to reflect emergent economic and ecological practices that may differ radically from current “best practice”.
The MODA + MODE human lens provides thirteen categories that are invariant across cultures, space, and time – it provides an economic ideology independent reasoning framework for transdisciplinary collaboration. The human lens allows us to make sense of the world and the natural environment from a human perspective, to evolve our value systems, and to structure and adapt human endeavours accordingly.
The human lens is a meta language that can be used to design multi-paradigm and multi-dimensional modelling and simulation tools for resource flows between economic agents as well as resource flows between ecological systems and economic systems.
The human lens is comprised of:
The system lens, to support the formalisation and visual representation of knowledge and resource flows in complex socio-technological systems based the three categories of resources, events, and agents (the REA paradigm, an accounting model developed by E.W. McCarthy in 1982 for representing activities in economic ecosystems). The system lens can be applied at all levels of organisational scale, resulting in fractal representations that reflect the available level of tacit knowledge about the modelled systems.
The semantic lens, to support the formalisation and visual representation of values and economic motivations of the agents identified in the systems lens. The semantic lens provides a configuration framework for articulating ethical, cultural, and economic value systems as well as a reasoning framework for evaluating socio-technological system design scenarios and research objectives with the help of the five categories of social, designed, symbolic, organic, and critical.
The logistic lens, to support the formalisation and visual representation of value creating activities and heuristics within socio-technological systems. The logistic lens provides five categories for describing value creating activities: grow (referring to the production of food and energy), make (referring to the design, engineering, and construction of systems), sustain (referring to the maintenance of production and system quality attributes), move (referring to the transportation of resources and flows of information and knowledge), and play (referring to creative experimentation and other social activities). The logistic lens can be used to model and understand feedback loops across levels of scale (from individuals, to teams, organisations, and economic ecosystems) and between agents (companies, regulatory bodies, local communities, research institutions, educational institutions, citizens, and governance institutions). The categories of the logistic lens assist in the identification of suitable quantitative metrics for evaluating performance against the value system articulated via a configuration of the semantic lens.
All 13 human lens concepts reflect foundational aspects of human cognition and the human capacity for symbolic thought within an ecological context, and are found in all cultures under various labels.
The human lens concepts are recognisable in all historic human cultures, and they will continue to be relevant in another 1,000 years – this is what is meant by “independent of economic ideology”. This is important because language is always a contentious topic in a transdisciplinary context, since each discipline uses a different language. The human lens can be used to model all aspects of the relationships between economic agents and all aspects of collaboration within economic agents.
Furthermore the fractal characteristic of the human lens allows the representation of groups of collaborating economic agents and the representation of abstract relationships between such groups.
The grow category in the logistic lens can be used to instantiate specific subcategories in the land use sector for forestry, horticulture, dairy farming etc. Additionally the base categories of the logistic lens provide a framework for the transport (move, referring to the transportation of resources and flows of information and knowledge), electricity (grow, referring to the production of food and energy), and industry sectors (make, referring to the design, engineering, and construction of systems). The base categories in the logistic lens are designed to encourage zero waste system designs, the sustain category (referring to the maintenance of production and system quality attributes) can be used to instantiate models that focus on maintenance, repair, and decomposition for reuse of economic resources and that explicitly indicate, and as needed, quantify, residual waste streams. Finally the play category (referring to creative experimentation and other social activities) can be used to instantiate models that focus on important cultural practices, on the education sector and on research and innovation).
A distinguishing feature of the MODA + MODE meta paradigm is that it allows for consistent formalisation of discipline specific paradigms and local domain specific languages, such that domain experts are able to continue to use their preferred paradigms and terminologies.
Agent based economic and ecological models can be created and populated with available data and assumptions (scenarios) about economic sectors and ecological practices at various levels of scale in time and space, and these models can then be used to:
Visualise qualitative and quantitative economic dependencies and resource flows, including but not limited to links from sectoral models to thoroughly understand the interactions between the energy and land use sectors.
Run agent based simulations of activities in the economic and ecological spheres to explore different scenarios and their implications.
Generate corresponding multi-dimensional economic and ecological accounting tools that can be used to coordinate human economic activities.
All the categories and semantic links between categories and instances in the example model above are easily made available for processing by software tools. The example shows concrete resources (orange), events and activities (blue), as well as agents (green) and their motivations (red).
The semantic lens allows us to create explicit models of different worldviews and paradigms, so that all relevant value systems and cultural differences are not only acknowledged, but become an integral part of the language used to describe economic activities and their purpose.
Visual semantic models can be used to trace motivations back over several levels to specific cultural or individual values. In this way assumptions and worldviews are made explicit, and cultural context can be integrated into economic and logistical models to any desired level of detail. In particular local knowledge and values can be reflected in the configuration of economic models, alongside scientific knowledge about the natural world and the climate, facilitating the co-design of mitigation and adaptation activities in collaboration with local populations.
The human lens in combination with an inclusive consultative and transdisciplinary approach provides results that are traceable to underlying datasets and economic assumptions and that can assist policy designers in answering important questions under a range of different climate change scenarios:
What emissions reductions are technically and economically feasible when factoring in the interactions between sectors and economy-wide constraints?
What are the economic consequences of different levels of emissions reductions, different types of policy interventions, and different scenarios of technological and economic change?
What distributional impact could emissions budgets or emissions policies have on different sectors, regions, generations and socio-economic groups?
What impact will domestic emissions policies have on the ability to meet global emission reduction targets?
What impact will overseas markets and policies have on local emissions, production and trade?
In an increasingly unpredictable world that can easily be disrupted by severe climate related events, a modelling and simulation tool as described above may be essential for preventing or limiting social collapse, allowing local populations to rapidly explore the viability of new sequences of adaptive actions, before jointly agreeing on and committing to specific (and potentially radical) changes in economic and ecological practices.
Modelling and simulation tool chain design
A suitable modelling tool that supports the human lens and representations of both quantitative and qualitative / semantic models can be implemented with the help of category theory (which is the abstract “systems integration language of mathematics”) and with denotational semantics (to map formal models to concrete computational platforms and data storage technologies) .
A basic implementation of the human lens for qualitative modelling is achievable with a Unified Modeling Language (UML) modelling tool and via the configuration of a UML Profile that includes suitable UML stereotype definitions for the thirteen human lens concepts.
An even more basic implementation is afforded by markers and a whiteboard or by pencil and paper, but then of course the models can’t be used to drive automation and agent based simulation tools.
The full potential of the human lens can be harnessed with a tool like S23M’s Open Source Cell Platform that provides an unlimited multi-level instantiation capability and that enforces strict semantics for agent based modelling.
The Cell Platform provides a clean formalisation based on the axioms of category theory that is recursively bootstrapped from the structure of an ordered pair, without any spurious complexity induced by the underlying implementation technology (the Java Virtual Machine – JVM). Additionally the Cell Platform:
Uses denotational semantics (a unique machine readable semantic identity for each concept) to completely separate the concern of naming from the concern of semantic modelling, allowing each agent to introduce preferred labels and symbols.
Enables communication and collaboration between agents based on artefacts (information resources), and events which equates to native support for the REA paradigm.
Provides an API in the language of category theory that exposes the recursive construction of models, and that hence allows extensions, restrictions, and other variations of all concepts.
Allows agents to make selected models discoverable, to make selected models visible to other agents, and to declare semantic equivalences between concepts in different models that are then recognisable by the reasoning engine within the Cell Platform.
Provides support for 4-state information quality logic (true, false, unknown, not applicable) to allow agents to easily process incomplete data and any structures they may find in the models from other agents – without resulting in ambiguous semantics.
Supports logic and reasoning entirely within the abstract language of category theory, since semantic equivalences are defined between semantic identities rather than between human assigned labels.
The S23M team envisages a transdisciplinary modelling and simulation framework for climate change mitigation and adaptation scenarios that allows domain experts from various disciplines to contribute models of sectors of the economy and aspects of ecosystems within their preferred paradigm and in their preferred terminology into a modelling tool chain that includes explicit support for:
Managing and enforcing the limits of applicability of specific models.
Recording all assumptions that are associated with a model or specific scenario in a form that is accessible to software tools.
Reviewing and flagging inconsistencies between the assumptions associated with different models or aspects of the domain of interest.
Formal version and variant management for all models, data sets, and sets of assumptions that are associated with specific climate change mitigation pathways.
Formal traceability between sets of assumptions, and related models and results of agent based simulations.
The human lens meta language, to enable
Specification of suitable qualitative and quantitative goals in suitable metrics, including metrics for the quantification of resource flows and green house gas emissions in physical units, and chemical types/properties.
Modelling cultural norms and expected or potential shifts in cultural norms.
Modelling the economic ideology and expected or potential shifts in economic ideology.
Modelling cross-sector dependencies and resource flows at different levels of scale, including desirable shifts in such dependencies.
Modelling of concrete economic agents that are of strategic economic importance, including the dependencies between these agents – to provide a foundation for performing dynamic agent based simulations under a range of different assumptions.
Semantic integration between different aspect and sector models, including the specification of any required transformations of input and output data structures.
As needed, translating the results of agent based simulations back into traditional financial economic metrics, to assist experimental and iterative development of suitable policies and regulatory frameworks for achieving desired national and regional level outcomes.
The purpose of such a modelling and simulation tool chain is to allow rapid exploration and iterative refinement of different mitigation and adaptation scenarios. Policy makers and the wider population need to see “first hand” (as far as that is possible) that busyness as usual and related measures to “decarbonise” the economy via traditional economic tools within the framework of financial economics are inadequate for dealing with the challenge presented by the climate crisis.
Organisations are best thought of as cultural organisms. Groups of organisations with compatible operating models can be thought of as a cultural species. The human genusis the genus that includes all cultural species. Since the emergence of humans around two million years ago, evolution has produced many different cultural species within the human genus.
It is becoming clear (Dunbar) that only human scale organisations are understandable for individual humans and have the potential to provide psychologically safe and healthy environments for humans. A careful analysis of human history demonstrates that super-human scale organisations are inherently unsafe for individual humans, and that completely atomised societies are inconceivable, as they are apparently incompatible with human social needs.
Viewed from within the context of human evolution, the emergence of “civilised” (super-human scale) societies and the construction of empires is a social cancer that feeds on cultural species and has resulted in the destruction of cultural species and in a severe reduction in the number of healthy cultural species. Based on this understanding we can conclude that the human genus has been declining in adaptive fitness since the dawn of “civilisation” around 10,000 years ago.
The NeurodiVenture operating model is the social DNA of an emergent cultural species that has developed an immune system that enables it to survive and even thrive in three complementary contexts:
within super-human scale societies afflicted by terminal cancer
within social environments that contain a growing number of NeurodiVentures
within social environments that contain other human scale cultural species within the human genus
The minimalistic aspect of the NeurodiVenture operating model supports a huge diversity between cultural organisms and overall equips the NeurodiVenture cultural species with a level of resilience that differs markedly from the brittleness and pathological cultural inertia that characterises super-human scale societies.
The main difference between modern emergent human scale cultural species and prehistoric human scale cultural species lies in the language systems and communication technologies that are being used to coordinate activities and to record and transmit knowledge within cultural organisms, between cultural organisms, and between cultural species.
The main commonality between prehistoric societies and modern human scale cultural species is the critical importance of knowledge for survival, and a cultural appreciation for the value of knowledge and the value of trust based collaboration at eye level both within cultural organisms and between cultural organisms.
The main difference between all human scale cultural species and super-human scale “civilised” societies lies in the devaluation of knowledge and reliance on anonymous transactions and abstract monetary metrics, and in a corresponding devaluation of trust based collaboration at eye level.
The end of capital
Peter Thiel and Eric Weinstein, the manager of Thiel Capital, are two people who are not afraid to share their thoughts. It is interesting to see how they can spend 3 hours framing their quite astute observations on human society entirely within the box of capitalism and “meritocracy”, and how this frame prevents them from reaching deeper insights about human limitations and human creativity.
Human scale does not exist in Peter Thiel’s world. Instead Peter and Eric attempt to explain everything in terms of individuals, individual merit, organisations, growth, and progress in science and technology (without any attempt to delineate the boundary between science and technology). In the dialogue referenced above they both go to great lengths to complain about the extent to which virtually all organisations have become sociopathic, but they don’t realise how insisting on an individual talent or merit scale and a universal metric (capital) is the perfect breeding ground for the corruption that they complain about. It is as if they complain about all the hierarchical structures that differ from an envisaged ideal and universal “meritocratic” hierarchy that is defined by criteria stipulated by Peter Thiel & Co.
Whilst long, the above dialogue is highly recommended for all those who are still convinced that capital must be part of the furniture of all technologically advanced societies.
The dialogue between Peter Thiel and Eric Weinstein illustrates that some of the most fundamentalist capitalists question whether there has been any substantial technological progress at all over the last 40 years.
I concur with the diagnosis of stagnation in many areas of knowledge, but from my perspective economic growth and capital are counter-productive and dangerously misleading metrics going forward. Capital is a legacy technology that will need to be phased out if humans want to have any chance at avoiding the self-destructive pattern of civilisation building and collapse that has characterised the last 10,000 years.
We need to be clear about the remaining life expectancy of capital as a relevant metric at super-human scale. In the short term human scale employee owned companies and cooperatives can opportunistically work within a capital-driven world, but over the next 30 to 100 years the role of capital will likely be reduced to zero – it’s going to be an obsolete legacy technology just like the telegraph is a legacy technology today.
The interest in human scale employee owned companies is growing globally, as such companies are capable of thriving in a capitalist environment due to their collaborative advantage, but they are also ideally positioned to thrive in other emergent environments that are less toxic for the planet.
Domain-specific metrics that measure physical properties are going to become much more important than abstract metrics at super-human scale. Abstract metrics are only safe (low risk of corruption) for local resource distribution at human scale.
From economics to the web of life
If we want to avoid repeating the mistakes of human “civilisations”, the rules for coordinating at super-human scale will have to allow for and encourage a rich diversity of human scale organisations.
In a human scale social world, apart from the self-imposed constraint of human scale, there is no universally dominant organisational paradigm. In a super-human scale social world that is increasingly toxic for individual mental and physical health, a diversity of human scale paradigms will eventually crowd out the super-human [global/national/mega-city] scale paradigm that dominates today.
The resulting web of interdependencies can simply be thought of as the web of life rather than “civilisation 2.0”. We must not to again make the anthropocentric mistake of putting humans at the centre of the universe.
At human scale cultural evolution operates as follows:
On the relationships between cultural organisms and on the links between cultural species.
Relationships can strengthen or weaken, new relationships can be established, and established relationships can be be discontinued or put on hold. At any point in time the relationship between two cultural organisms can be described in terms of the binary trust based relationships between specific individuals. The duration of relationships can last from months through to many decades and possibly longer.
By individuals who may chose to leave or join a cultural organism, travelling along the link to a related cultural organism of the same cultural species.
From an individual’s perspective such a change in organisational membership is minor. The individual retains their individual competency network, and the change can be described as the emergence of new regular collaboration patterns within the individual’s competency network and the weakening of earlier regular collaboration patterns – it is very much comparable to a change in team membership within a cultural organism. From the perspective of the cultural organism involved the change reflects a desirable change or optimisation in the interaction patterns across the organisational boundary that is well received by most of the individuals involved – a new team is welcoming a new member and another team in the related cultural organism will reconfigure accordingly. The duration of organisational membership may last from months through to many decades or an entire lifetime.
By individuals who may chose to leave or join a cultural organism, travelling along the link to a related cultural organism of a different cultural species.
Again, from an individual’s perspective such a change in organisational membership is relatively minor. The individual retains their individual competency network, and the change can be described as the emergence of new regular collaboration patterns within the individual’s competency network and the weakening of earlier regular collaboration patterns – but in this case the individual will need to integrate into a new culture. Often such a change will be motivated by the neurological disposition and specific talents and interests of the individual, who may have discovered via personal interactions across the organisational boundary that she or he would be more comfortable in the target culture. From the perspective of the cultural organisms involved the change reflects an opportunity for cultural cross pollination across the organisational boundary that may improve the collaboration patterns across the cultural species boundary. The average number of shifts between cultural species will be zero across a typical human life, and the number of shifts will likely be one or more for many neurodivergent individuals, who will feel compelled to search for a cultural environment that is well suited for their particular needs and cognitive lens.
By individuals who may chose to leave or join an unrelated cultural organism of the same cultural species.
This scenario represents a mixture of scenarios 1 and 2 above. The individual will have had to establish a relationship to someone in a different cultural organism, and hence the change represents an emergent relationship between two cultural organisms. The duration of the new relationship may last from months through to many decades or possibly longer.
By individuals who may chose to leave or join an unrelated cultural organism of a different cultural species.
This scenario represents a mixture of scenarios 1 and 3 above. The individual will have had to establish a relationship to someone in a different cultural organism of a different cultural species, and hence the change represents an emergent relationship between two cultural organisms. This scenario may be fairly rare, as it involves establishing a cross-species relationship between cultural organisms that had no prior contact. The resulting relationship may start off very much as an experiment or exploration with outcomes that are difficult to predict. It may result in the individual having found a more accommodating target culture in terms of their neurological disposition, and the link between the two cultural organism may only be short lived.
At human scale individuals enjoy a significant level of agency, with the ability to remain in a given cultural organism as long as they desire, and to move to a different cultural organism when this is aligned with individual neurological dispositions, talents and interests. All atomic changes in relationships and memberships leave an individual’s existing competency network intact and at all times the individual is part of a cultural organism that provides a livelihood for the individual.
Similarly cultural organisms enjoy a significant level of agency at human scale, as all individuals in the organism may create new relationships across the organisational boundary as needed, for example coordinated via a simple advice process and as needed via deliberation in Open Space. Cultural organisms that don’t operate an egalitarian culture will quickly find themselves at a disadvantage, as they are held back by cultural inertia. At some point their members may decide to join more egalitarian cultural organisms.
Agency at super-human scale is an emergent phenomenon that can not be attributed to any specific individual. Living within “civilisation” we are surrounded by super-human scale structures and it is difficult for most people to imagine collaboration at human scale without being embedded in some bigger hierarchical system.
Each human scale cultural organism represents an aggregation of agency that manifests itself in individual relationships and interactions across the organisational boundary. In a non-hierarchical cultural organism there is no single individual that “leads”, instead external representation and decision making of the cultural organism is distributed across all the individual relationships between the cultural organism and other cultural organisms.
Large sets of collaborating cultural organisms (some of which may be given labels for the purpose of communication and reasoning about them) without any hierarchical command and control are unattractive for sociopathic empire builders. The lack of hierarchical structure is a key element of the immune system against organisational cancer.
Visualising human collaboration
Human spoken and written languages are useful, but we need better [non-linear] languages systems for reasoning about collaboration beyond human scale.
The human lens is a meta language that can be used to construct better language systems.
The human lens can be used to model all aspects of the relationships between cultural organisms and all aspects of the relationships within cultural organisms. Furthermore the fractal characteristic of the human lens also allows the representation of groups of collaborating cultural organisms and the representation of abstract relationships between such groups.
When such structural and relational abstractions are agreed between cultural organisms, the result is a formal abstract framework that defines agreed collaboration patterns. Abstract collaboration frameworks can be worked out collaboratively in Open Space, and as needed choices between alternative approaches to specific details can be made via a democratic process involving all members from all cultural organisms that are involved. The focus of democratic governance at super-human scale completely shifts away from the selection of “leaders” to the selection of suitable collaboration frameworks for ecosystems of collaborating cultural organisms.
Below is a high level overview of valuable resource flows represented with the help of the logistic lens within the human lens.
The represented abstract categories can be refined as needed in corresponding models of concrete instances of resources and agents.
In a simplistic capitalistic world such complex multi-dimensional collaborations patterns tend to be linearised into legal agreements that are dominated by a simplistic one-dimensional metric – capital.
We can use the same visual notation as above to create models of dysfunctional feedback loops (or negative “externalities” in the language of economics).
In a networked digital world agreed collaboration patterns can be formalised with the human lens, making use of physical metrics to quantify flows of resources and energy, without any need to resort to abstract metrics. The technologies for resource based accounting exist today.
Below is an example of a high level commonality and variability analysis of the agriculture sector represented using the categories of resources, events, and agents (the REA paradigm).
The visualised categories are the commonalities that characterise the sector. Corresponding representations of concrete instances of these categories with the help of the logistic lens and connections between these instances lead to models of value producing processes and activities that can be refined to any desirable level of detail.
Where we stand today
The only thing that stands in the way of phasing out the legacy technology of capital is cultural inertia and the ongoing indoctrination in outdated economic ideology delivered by our education systems.
In the coming decades metrics that measure physical properties (energy use, resource use, waste metrics) are going to become much more important than abstract monetary metrics. We will increasingly discover that abstract metrics (“currencies”) are only safe to use for resource distribution at a local human scale, and that at super-human scale the risk of corruption of abstract metrics simply becomes too large to be acceptable.
To comprehend where we currently stand it is useful to conduct a little thought experiment. What would happen if the global financial system collapses or if all the technology infrastructure underpinning the financial system collapses?
If everybody just continued with all their daily activities as usual as far as possible, irrespective of their ability to be paid or to pay, the following would happen:
In the technologically “less advanced” parts of the world the impact would be minimal. People would continue to go about their lives, collaborate along the lines of trusted relationships, and as required come up with alternative no/low tech accounting systems at human scale.
In the technologically “advanced” parts of the world the impact would be much larger. Many technological systems and complex automated supply chains that assume working connections to banking systems would be disrupted. Above and beyond the inability to purchase physical goods online, people would quickly run out of credit tokens on their phones and on public transport, preventing them from using such services. In general, all technologies that rely on embedded links to banking systems would become disabled, whilst all technologies without such links remain unaffected. People could continue to visit retail shops and pick up goods or deliver supplies – and just as in the technologically less advanced parts of the world people will likely quickly come up with low tech accounting systems at human scale.
The overall result of using alternative low tech local accounting systems would be a much reduced ability to rapidly shift abstract credit tokens around the world.
The main people who would get concerned would be all those who used to be able “to make a living” from speculation, from rent seeking, and from shifting abstract tokens around the world. Those same people will likely not have access to any of the trusted relationships at human scale that are essential for surviving in a non-financialised world. Similarly many of the people who used to have “second and third level” bullshit jobs (all those people in jobs involved in operating the technology that supports the financial system) may discover that they lack useful trusted relationships at human scale.
In a world where many global supply chains for physical goods are disrupted, and where technological failures refocus collaboration on local trusted relationships at human scale, resources and goods would flow at slower rates, and the flows that continue to take place would largely be local, focused on the absolute necessities of life. In some geographies food shortages would quickly become extreme, and the overall reduction in long distance transportation would significantly reduce energy consumption.
Interestingly renewable energy sources and connected electricity distribution networks and connected customers would only be disrupted in locations where they are deeply entangled with banking systems.
The outlined scenarios could very quickly result in civil unrest, especially in the “advanced” parts of the world that are further removed from trust based collaboration at human scale, but this observation can in no way be taken as a “proof” that a world without capital is inconceivable:
Dismissing a world without capital because we personally have never experienced world without global money is simply a case of ignorance and lack of imagination fuelled by fear of the unknown.
In prehistoric times humans survived and increasingly thrived without money for many hundred thousand years. People’s life expectancy may have been shorter than today, but prehistoric humans where highly capable in transmitting complex knowledge over many generations, allowing them to adapt to many different climate zones and to a huge range of different local ecological contexts.
A small number of technologically “backward” societies still share more characteristics with prehistoric cultures than with the WEIRD (Western Educated Industrialised Rich Democratic) cultures that dominate today.
With relatively minor adaptations many of the technologies we use today could be disconnected from the global financial system and could resume operations in a post-capital world. The magnitude of the changes required are in many ways comparable to the magnitude of the changes to remove Y2K limitations from our software systems – not trivial but far from impossible, and perfectly achievable within a few years. As part of this transformation our technologies could be wired up to resource based accounting technologies that track flows of resources and goods purely in terms of physical metrics. The result would be a global logistics infrastructure capable of tracking resource flows without the translating (liquefying) everything into an abstract 1-dimensional metric of capital that instantaneously disappears through conceptual wormholes to facilitate universal fungibility for everything under the sun – everything and everyone is for sale.
Some of the effects outlined above such as a reduction in global resource flows, a refocus on local flows of resources, and a reduction in energy consumption would be highly desirable in terms of reducing greenhouse gas emissions and a rapid transition to a zero carbon economy. A transition towards resource based accounting as outlined above would allow us to re-enable global resource flows under a completely new regime of governance: we would be able to plan and budget in terms of resource needs and we would be able to very easily monitor agreed limits of energy and resource consumption in raw physical units without any distortions.
Considering all of the above, we can conclude that we are already much closer to a world without capital than capitalists would like us to believe. In many ways such a new world is much more desirable for most of us than the delusional world of infinite “growth” that we are still being sold.
The title of this post is the title of a book project I am working on, to provide organisations with a useful sense of direction, giving them the option to snap out of busyness as usual mode when they are ready. Whether this then happens in a timely manner may vary from case to case. It is not something that anyone has much control over.
As the title suggests, the book is about collaboration, about scale, and about humans, about beauty, and about limits. It has been written from my perspective as an autistic anthropologist by birth and a knowledge archaeologist by autodidactic training.
I attempt to address the challenges of ethical value creation in the Anthropocene. There is no shortage of optimistic books that celebrate human achievements and there is also no shortage of pessimistic books that proclaim the end of the human species. In contrast I approach the Anthropocene from the fringe of human society, from the perspective of someone who does not relate to abstract human group identities.
Evolutionary biologist David Sloan Wilson observes that small groups are the organisms within human society – in contrast to individuals, corporations, and nation states. The implications for our “civilisation” are profound. It is time to curate and share the lessons from autistic people, and help others create good company by pumping value from a dying ideological system into an emerging world.
Since the very beginning civilisation has always been more about a myth of progress than about anything that benefits local communities and families. – except perhaps for the benefit of not being killed as easily by a neighbouring horde of more or less civilised people. Once the history of civilisation is understood as series of progress myths, where each civilisation looks towards earlier or competing civilisations with a yardstick that is tailored to prove that its own myths and achievements are clearly superior to anything that came before, it is possible to identify the loose ends and the work-arounds of civilisation that are usually presented as progress.
The result is a historical narrative that makes for slightly less depressing reading than 10,000 years of conflict and wars. Instead, human history can be understood as a series of learning experiences that present us with the option to break out of the tired, old, and increasingly destructive pattern once it has been recognised. Whether our current global civilisation chooses to complete the familiar pattern of growth and collapse in the usual manner is a question that is up to all of us.
Regardless of what route we choose, on this planet no one is in control. The force of life is distributed and decentralised, and it might be a good idea to organise accordingly.
To understand why beauty, human scale, collaboration, and limits are essential for human sanity, we only need to look at the ugly reality of super-human scale institutions that currently surround us.
For concrete examples of making and taking in the global economy look no further than the wheeling and dealing that Vandana Shiva’s examines in her work. She makes astute observations on the role that Microsoft and other global technology companies play in rolling out intensive industrial agriculture to all corners of the planet.
Beyond the tactic of economic arm-twisting global corporations have perfected the art of accounting, shifting 40% of their profits ($600 billion annually) into tax havens with tax rates from 0% to less than 10%. Governments that represent their people rather than corporate interests would legislate against this practice – but they don’t.
Here is an excellent paper by A. Pluchino. A. E. Biondo, and A. Rapisarda on the intelligence of the economic game and the logic of capital, not even considering the effects of psychopathic social gaming. Synopsis:
On random factors that influence “social success”
… there is nowadays an ever greater evidence about the fundamental role of chance, luck or, more in general, random factors, in determining successes or failures in our personal and professional lives. In particular, it has been shown that scientists have the same chance along their career of publishing their biggest hit; that those with earlier surname initials are significantly more likely to receive tenure at top departments; that one’s position in an alphabetically sorted list may be important in determining access to over-subscribed public services; that middle name initials enhance evaluations of intellectual performance; that people with easy-to-pronounce names are judged more positively than those with difficult-to-pronounce names; that individuals with noble-sounding surnames are found to work more often as managers than as employees; that females with masculine monikers are more successful in legal careers; that roughly half of the variance in incomes across persons worldwide is explained only by their country of residence and by the income distribution within that country; that the probability of becoming a CEO is strongly influenced by your name or by your month of birth; and that even the probability of developing a cancer, maybe cutting a brilliant career, is mainly due to simple bad luck.
… On the randomness of the distribution of rewards when the logic of capital is applied
In particular, the most successful individual, with Cmax = 2560, has a talent T = 0:61, only slightly greater than the mean value mT = 0:6, while the most talented one (Tmax = 0:89) has a capital/success lower than 1 unit (C = 0:625). As we will see more in detail in the next subsection, such a result is not a special case, but it is rather the rule for this kind of system: the maximum success never coincides with the maximum talent, and vice-versa. Moreover, such a misalignment between success and talent is disproportionate and highly nonlinear. In fact, the average capital of all people with talent T > T is C 20: in other words, the capital/success of the most successful individual, who is moderately gifted, is 128 times greater than the average capital/success of people who are more talented than him. We can conclude that, if there is not an exceptional talent behind the enormous success of some people, another factor is probably at work. Our simulation clearly shows that such a factor is just pure luck.
Meanwhile, while society is stuck in a broken system, what is the best way of allocating R&D funding?
… The European Research Council has recently given to the biochemist Ohid Yaqub a 1:7 million US dollars grant to quantify the role of serendipity in science. Yaqub found that it is possible to classify serendipity into four basic types and that there may be important factors affecting its occurrence. His conclusions seem to agree with the believing that the commonly adopted – apparently meritocratic – strategies, which pursuit excellence and drive out diversity, seem destined to be loosing and inefficient. The reason is that they cut out a priori researches that initially appear less promising but that, thanks also to serendipity, could be extremely innovative a posteriori.
… if the goal is to reward the most talented persons (thus increasing their final level of success), it is much more convenient to distribute periodically (even small) equal amounts of capital to all individuals rather than to give a greater capital only to a small percentage of them, selected through their level of success – already reached – at the moment of the distribution. On one hand, the histogram shows that the “egalitarian” criterion, which assigns 1 unit of capital every 5 years to all the individuals is the most efficient way to distributed funds,
… The model shows the importance, very frequently underestimated, of lucky events in determining the level of individual success. Since rewards and resources are usually given to those that have already reached a high level of success, mistakenly considered as a measure of competence/talent, this result is even a more harmful disincentive, causing a lack of opportunities for the most talented ones. Our results are a warning against the risks of what we call the “naive meritocracy” which, underestimating the role of randomness among the determinants of success, often fail to give honors and rewards to the most competent people.
Robert Reich does a good job of highlighting the systemic dysfunction, but I cringe when I hear the undercurrent of the American Dream of “getting ahead” by working hard and the related myth that capitalism can be fixed by appropriate levels of regulation and democratic oversight. It seems no one dares to tell the truth to US audiences.
Critical social scientists regularly point out that the entire discipline of psychology is best understood as the study of human behaviour in WEIRD (Western Educated Industrialised Rich Democratic) cultures. Its identical twin is the discipline of marketing. The cultural bias is extreme. Here is just one example of the flaky foundations and of the bias. I have started to extend WEIRD to WEIRDT : Western Educated Industrialised Rich Democratic Theatre. Everything in this theatre is about perception – there is no substance or connection to the physical and ecological context outside the theatre.
But the world outside the theatre still exists. This commentary from Noam Chomsky and the timeless quotes from David Hume apply. The notion of governance as perception management and of politics as a theatre of opinions is what I try to highlight in this article on the CIIC blog. Noam Chomsky is correct in pointing out that in the super-human scale democratic theatre the power lies with the governed once the veil of secrecy is blown away. This is extremely important to realise in our society of ubiquitous surveillance and security agencies from state actors. As Noam Chomsky points out, security agencies are designed to secure the interests of the theatre and not the interests of the population. Anyone who still believes that any security agency or secret service is doing a useful job for any society has been conned by the theatre.
Transparency is the ultimate disinfectant in the digital era. But as long as the population believes in the myth of the necessity for state secrets and corporate secrets – which by definition are secrets with super-human scale / scope, the power of transparency will remain dormant. All super-human scale secrets are instruments of systematic abuse. The sooner this is widely understood the sooner the theatre can be confined to the dustbin of history. My dad worked in the diplomatic service, and even though I was one or more levels removed from the content, the ridiculous and delusional self-importance of the diplomats and their ignorance of physical reality was obvious to a 10-year old. As Douglas Rushkoff observes, “Operation Mind Fuck was too successful, but there is a way to bring back a little bit of hope into what we are doing.”
Beliefs in money, debt, institutions, and systems are better thought of as behavioural patterns (habits) than as beliefs that people are genuinely comfortable with. Even most actors within the theatre are suffering from severe cognitive dissonance. Habits that don’t serve us well are usually referred to as addictions. The challenge for the people stuck in the theatre within corporations and other super-human scale institutions lies in overcoming addiction and story withdrawal symptoms.
When the majority of people start to understand that all our super-human scale organisations are part of the theatre transparency can be deployed as a disinfectant for social diseases.
Human scale
The operating models of Buurtzorg and other non-hierarchical and distributed collaborative organisations like S23M are concrete examples of understandable and relatable human scale organisations.
The fact that human scale social operating systems can be constructed on top of corrupt infrastructure is a powerful message. In particular autistic people are increasingly asking me about S23M’s transparent operating model, and I am more than happy to assist them in setting up neurodiventures that provide them with some level of protection from the toxic and delusional theatre around them. By focusing on the human scale outside the theatre we can reconnect with the physical and ecological niche that supports our human needs.
The book project I am working on won’t provide all the answers – that is impossible – but it can equip small groups of people with:
critical thinking tools and a language framework that encourages creativity and that assists learning and discovery,
as well as an ethical framework that promotes collaboration and knowledge sharing instead of competition.
As part of the project it is necessary to provide an unvarnished account of human history to date. The table of content provides an indication of scope and framing:
Human origins
Human scale patterns
The human lens
Learning
Super-human scale patterns
Loose end : Loss of control
Work-around : Automated labour
Industrial society
Loose end : Exponential growth
Work-around : Computing
Information society
Loose end : Loss of tacit knowledge
Work-around : Busyness
Liquidation society
Loose end : Loss of semantics
Thought experiment : Knowledge society
Addressing the loose ends
Human scale patterns, second edition
Transitioning to human scale
Conclusion
Tools for creating learning organisations
If individual learning seems difficult at times, organisational learning seems elusive or impossible most of the time. In my experience the following tools allow knowledge to flourish at human scale – in the open creative spaces between disciplines and organisational silos:
The SECI knowledge creation spiral is a useful conceptual tool for understanding and improving learning and knowledge flows within organisations. The four SECI activity categories (socialisation, externalisation, combination, internalisation) can be used to describe learning at all levels of organisational scale.
MODA+MODE is a conceptual framework for creating learning organisations that extends the concepts of continuous improvement and the SECI spiral into the realm of knowledge intensive industries, transdisciplinary research and development, and socio-technological innovation. MODA+MODE uses the SECI knowledge creation spiral to release the handbrake on tacit knowledge and creativity by focusing on:
sharing and validating knowledge,
making knowledge explicit and accessible to humans and software tools,
combining shared knowledge in creative ways,
transdisciplinary research and development across organisational boundaries.
Open SpaceTechnology is a very simple and highly scalable technique for powering a continuous SECI knowledge creation spiral that breaks through the barriers of organisational boundaries, established silos and management structures.
The human lens provides thirteen categories that are invariant across cultures, space, and time – it provides a visual language and reasoning framework for transdisciplinary collaboration. The human lens allows us to make sense of the world and the natural environment from a human perspective, to evolve our value systems, and to structure and optimise human economic endeavours.
The human lens is comprised of:
The system lens, to support the formalisation and visual representation of knowledge and resource flows in complex socio-technological systems based the three categories of resources, events, and agents (the REA paradigm, an accounting model developed by E.W. McCarthy in 1982 for representing activities in economic ecosystems). The system lens can be applied at all levels of organisational scale, resulting in fractal representations that reflect the available level of tacit knowledge about the modelled systems.
The semantic lens, to support the formalisation and visual representation of values and economic motivations of the agents identified in the systems lens. The semantic lens provides a configuration framework for articulating economic, ethical, and cultural value systems as well as a reasoning framework for evaluating socio-technological system design scenarios and research objectives with the help of the five categories of social, designed, symbolic, organic, and critical.
The logistic lens, to support the formalisation and visual representation of value creating activities and heuristics within socio-technological systems. The logistic lens provides five categories for describing value creating activities: grow (referring to the production of food and energy), make (referring to the design, engineering, and construction of systems), sustain (referring to the maintenance of production and system quality attributes), move (referring to the transportation of resources and flows of information and knowledge), and play (referring to creative experimentation and other social activities). The logistic lens can be used to model and understand feedback loops across levels of scale (from individuals, to teams, organisations, and economic ecosystems) and between economic agents (companies, regulatory bodies, local communities, research institutions, educational institutions, citizens, and governance institutions). The categories of the logistic lens assist in the identification of suitable quantitative metrics for evaluating performance against the value system articulated via a configuration of the semantic lens.
The 26 MODA+MODE backbone principles provide a baseline set of thinking tools to avoid getting entrapped in a single paradigm. Thinking tools are the mental image schemas, frames, and reasoning tools, and also the behavioural patterns that help us to validate knowledge, ask new questions, and form and explore new ideas – the hugely diverse set of tools that different people tap into as part of the creative process. The backbone principles have been sourced from a range of sciences and engineering disciplines, including suitable mathematical foundations.
The 8 prosocial core design principles developed by Elinor Ostrom, Michael Cox and David Sloan Wilson guide the application of evolutionary science to coordinate action, avoid disruptive behaviours among group members, and cultivate appropriate relationships with other groups in a multi-group ecosystem. The pro social design principles provide a good starting point for implementing concrete policies and systems that are specifically adapted to the needs of neurodiverse groups of people and collaboration in transdisciplinary research and development environments.
At the moment too many organisations and people are either completely paralysed by fear or are running around like headless chickens as part of busyness as usual. Last weekend I found this great clip from Jonathan Pie in my Twitter feed. You can laugh and cry at the same time.
Have you ever wondered why “storytelling” is such a trendy topic? If this question bothers you and makes you uncomfortable, your perspective on human affairs and your cognitive lens is rather unusual.
Once upon a time, in the 1970s, model building gained popularity and nearly caught up with the older art of storytelling. But half a century later the popularity of model building is back to what it was in the 1960s, and according to the data analysis by Google Ngram “storytelling” has reached new heights, the word being used twice as often as the word “agile”.
The “art of storytelling” and “agile software” are strong contenders for being the catchphrase of the current millennium. Is is not surprising that the latter term was not in circulation in the 20th century, but it is perhaps somewhat surprising that the “art of storytelling” was pretty much non-existent before the 20th century.
Model building is linked to the success of the scientific method. Researchers create, validate, and refine models to improve our level of understanding about various aspects of the world we live in, and to articulate their understanding in formal notations that facilitate independent critical analysis.
What is the usefulness of models that are only understandable for very few humans?
The scientific revolution undoubtedly led to a better understanding of some aspects of the world we live in by enabling humans to create more and more complex technologies. But it also created new levels of ignorance about externalities that went hand in hand with the development of new technologies, fuelled by specific economic beliefs about efficiency and abstractions such as money and markets.
In the early days of the industrial revolution modelling was concerned with understanding and mastering the physical world, resulting in progress in engineering and manufacturing. Over the last century formal model building was found to be useful in more and more disciplines, across all the natural sciences, and increasingly as well in medicine and the social sciences, especially in economics.
With 20/20 hindsight it becomes clear that there is a significant lag between model building and the identification of externalities that are created by systematically applying models to accelerate the development and roll-out of new technologies.
Humans are biased to thinking they understand more than they actually do, and this effect is further amplified by technologies such as the Internet, which connects us to an exponentially growing pool of information. New knowledge is being produced faster than ever whilst the time available to independently validate each new nugget of “knowledge” is shrinking, and whilst the human ability to learn new knowledge at best remains unchanged – if it is not compromised by information overload.
Those who engage in model building face the challenge of either diving deep into a narrow silo, to ensure and adequate level of understanding of a particular niche domain, or to restrict their activity to an attempt of modelling the dependencies between subdomains, and to coordinating the model building of domain experts across a number of silos. As a result:
Many models are only understandable for their creators and a very small circle of collaborators.
Each model integrator can only be effective at bridging a very limited number of silos.
The assumptions associated with each model are only known understood locally, some of the assumptions remain tacit knowledge, and assumptions may vary significantly between the models produced by different teams.
Many externalities escape early detection, as there is hardly anyone or any technology continuously looking for unexpected results and correlations across deep chains of dependencies between subdomains.
When the translation of new models into new applications and technologies is not adequately constrained by the level to which models can be independently validated and by application of the precautionary principle, potentially catastrophic surprises are inevitable.
Does it make sense to talk about models that are not understandable for any human?
Good models are not only useful, they are also understandable and have explanatory power – at least for a few people. Additionally, from the perspective of a mathematician, many of the most highly valued models also conform to an aesthetic sense of beauty, by surfacing a surprising degree of symmetry, by bringing non-intuitive connections into focus, and simply by their level of compactness.
Scientific model building is a balancing act between simplicity and usefulness. An overly complex model is less easy to understand and therefore less easy to integrate with complementary models, and an over-simplified model may be easy to work with, but may be so limited in its scope of applicability that it becomes useless.
What is not widely recognised beyond the mathematical community is that the so-called models generated by machine learning algorithms / artificial intelligence systems are not human understandable, for the same reasons that the physical representations of knowledge within a human brain are not understandable by humans. Making any sense of knowledge representations in a brain requires not only highly specialised scanning technologies but also non-trivial visualisation technologies – and the resulting pictures only give us a very crude and indirect understanding of what a person experiences and thinks about at any given moment.
Do correlation models without explanatory power qualify as models? There are many useful applications of machine learning, but if the learning does not result in models that are understandable, then the results of machine learning should perhaps be referred to as digital correlation maps to avoid confusion with models that are designed for human consumption. Complex correlation maps can be visualised in ways similar to the results of brain scans, and the level of insights that can be deduced from such visualisations are correspondingly limited.
It is not yet clear how to construct conscious artificial intelligence systems, i.e. systems that can not only establish correlations between data streams, but that are also capable of developing conceptual models of themselves and their environment that can be shared with and can be understood by humans. In particular current machine learning systems are not able to explain how they arrive at specific conclusions.
The limitations of machine learning highlights what is being lost by neglecting model building and by leaving modelling entirely to individual experts working in deep and narrow silos. Model validation and integration has largely been replaced with over-simplified storytelling – the goal has shifted from improving understanding to applying the tools of persuasion.
Bernays’ vision was of a utopian society in which individuals’ dangerous libidinal energies, the psychic and emotional energy associated with instinctual biological drives that Bernays viewed as inherently dangerous given his observation of societies like the Germans under Hitler, could be harnessed and channelled by a corporate elite for economic benefit. Through the use of mass production, big business could fulfil the cravings of what Bernays saw as the inherently irrational and desire-driven masses, simultaneously securing the niche of a mass production economy (even in peacetime), as well as sating what he considered to be dangerous animal urges that threatened to tear society apart if left unquelled.
Bernays touted the idea that the “masses” are driven by factors outside their conscious understanding, and therefore that their minds can and should be manipulated by the capable few. “Intelligent men must realize that propaganda is the modern instrument by which they can fight for productive ends and help to bring order out of chaos.”
The conscious and intelligent manipulation of the organized habits and opinions of the masses is an important element in democratic society. Those who manipulate this unseen mechanism of society constitute an invisible government which is the true ruling power of our country. …In almost every act of our daily lives, whether in the sphere of politics or business, in our social conduct or our ethical thinking, we are dominated by the relatively small number of persons…who understand the mental processes and social patterns of the masses. It is they who pull the wires which control the public mind.
Propaganda was portrayed as the only alternative to chaos.
The purpose of storytelling is the propagation of beliefs and emotions.
What is the usefulness of stories if they do nothing to improve our level of understanding of the world we live in?
Sure, if stories help to increase the number of shared beliefs within a group, then the people involved may understand more about the motivations and behaviours of the others within the group. But at the same time, in the absence of building improved models about the non-social world, the behaviour of the group easily drifts into more and more abstract realms of social games, making the group increasingly blind to the effects of their behaviours on outsiders and on the non-social world.
Stories are appealing and hold persuasive potential because of their role in cultural transmission is the result of gene-culture co-evolution in tandem with the human capability for symbolic thought and spoken language. In human culture stories are involved in two functions:
Transmission of beliefs that are useful for the members of a group. Shared beliefs are the catalyst for improved collaboration.
Deception in order to protect or gain social status within a group or between groups. In the framework of contemporary competitive economic ideology deception is often referred to as marketing.
Storytelling thus is a key element of cultural evolution. Unfortunately cultural evolution fuelled by storytelling is a terribly slow form of learning for societies, even though storytelling is an impressively fast way for transmitting beliefs to other individuals. Not entirely surprisingly some studies find the prevalence of psychopathic traits in the upper echelons of the corporate world to be between 3% and 21%, much higher than the 1% prevalence in the general population.
Storytelling with the intent of deception enables individuals to reap short-term benefits for themselves to the longer-term detriment of society
The extent to which deceptive storytelling is tolerated is influenced by cultural norms, by the effectiveness of institutions and technologies entrusted with the enforcement of cultural norms, and the level of social inequality within a society. The work of the disciples of Edward Berneys ensured that deceptive storytelling has become a highly respected and valued skill.
However, simply focusing on minimising deception is no fix for all the weaknesses of storytelling. When a society with highly effective norm enforcement insists on rules and behavioural patterns that create environmental or social externalities, some of which may be invisible from within the cultural framework, deception can become a vital tool for those who suffer as a result of the externalities.
Furthermore, even in the absence of intentional deception, the maintenance, transmission, and uncritical adoption of beliefs via storytelling can easily become problematic if beliefs held in relation to the physical and living world are simply wrong. For example some people and cultures continue to hold scientifically untenable beliefs about the causes of specific diseases.
All political and economic ideologies rely on storytelling
Human societies are complex adaptive systems that can’t be described by any simple model. More precisely, it is not possible to develop long-range and detailed predictive models for social and economic behaviour. However, in a similar way that extensive sensor networks and modern computing technology allows the development of useful short-range weather forecasts, it is possible to use social and economic data to look for externalities and attempts of corruption.
Nothing stands in the way of monitoring the results of significant social and economic changes with a level of diligence that is comparable to the diligence expected from researchers when conducting scientific experiments in the medical field. Of course the pharmaceutical industry also has a reputation for colourful storytelling, and the healthcare sector is not spared from ethical corruption and the tools of marketing. But at least the healthcare sector is heavily regulated, academic research is an integral part of the sector, and independent validation of results is part of the certification process for all new products and treatments.
One has to wonder why economic and social policies are not subject to a comparable level of independent oversight. The model of governance in modern democracies typically includes a separation of power between legislature, executive, and judiciary, but the question is whether effective separation of power can be maintained over decades and centuries.
Human societies and social structures are far from static. Concepts such as the nation state are only a couple of hundred years old and the lifespan of economic bubbles and the structures created by within such bubbles is measured in years rather than centuries. And yet, many people and institutions are incapable of considering possible economic or social arrangements that lie outside consumerism and the cultural norms that currently dominate within a particular nation state. Cultural inertia is beneficial for societies whenever the environment in which they are embedded is highly stable, but it becomes problematic when the environment is undergoing rapid change.
Historically a rapidly changing environment used to be associated with local wars or local natural disasters such as extended periods of draughts or earthquakes. The industrial revolution has significantly shifted the main triggers of rapid change:
Improvements in technology, hygiene and medicine have facilitated significant population growth and ushered in a new geological era – the anthropocene, human activity is changing the physical environment faster than ever before
Machine powered technology has enabled wars of unprecedented scale, speed, and levels of destructiveness
The paradigm of growth based economics fuelled by interest bearing debt and aggressive marketing dominates on all continents in most societies, and facilitates global economic bubbles
Carbon emissions and other physical externalities of modern economic activity have no physical boundaries
Given this context it is extremely tempting for professional politicians within government and corporations to subscribe to the elitist logic of Edward Bernays and to exploit storytelling for local or personal gains. An alien observer of human societies would probably be amazed that some humans (and large organisations) are given a platform for virtually unlimited storytelling at a scale that affects billions and hundreds of millions people, and that delusional and misleading stories are let lose on the population of a species that is the local champion of cultural transmission on this planet.
Within growth based economics the effectiveness of marketing can never be good enough. Desperate corporations are hoping machine learning algorithms can take storytelling to yet another level. High frequency trading is one example of “successful” automated marketing, where algorithms try to trick each other into believing stories that are beyond human comprehension.
End of story?
If we continue to believe that the world is shaped exclusively by human delusions, then the human story may come to a fairly unspectacular end rather soon. It also won’t help us if we focus on building technologies that provide even more powerful delusions.
If there is anything that has led to significant improvements in human well-being and life expectancy in the last thousand years it would undoubtedly have to be model building and the scientific method. The power tools of systematic experimentation and modelling facilitated much of what we call progress but they also facilitated dangerous social games at a planetary scale.
Just as medical science no longer relies on unsubstantiated stories, the stories that we tell each other in business, government, and academic administration need to be subjected to critical analysis, and the public needs to be made aware of the evidence (or lack thereof) that underpins the claims of politicians and executives in the corporate world, so that experiments are clearly identified, and most importantly, that experiments are carefully monitored and subjected to independent review before being sold as solutions.
In this context lessons can be learned from the fast moving world of digital technology. On the positive side the software development community is acutely aware of the need to conduct experiments, on the negative side, outside a few life critical industries, the lack of rigour when conducting experiments in the development and deployment of new software solutions is embarrassing. In the software development community conducting multiple independent experiments is generally considered a waste of time, and the interests of financial investors determine the kinds of “solutions” that receive funding:
All human artefacts are technology. But beware of anybody who uses this term. Like “maturity” and “reality” and “progress”, the word “technology” has an agenda for your behaviour: usually what is being referred to as “technology” is something that somebody wants you to submit to.
“Technology” often implicitly refers to something you are expected to turn over to “the guys who understand it.” This is actually almost always a political move. Somebody wants you to give certain things to them to design and decide. Perhaps you should, but perhaps not. – Ted Nelson, a pioneer of information technology, philosopher, and sociologist who coined the terms hypertext and hypermedia in 1963.
The software industry is an interesting economic subsystem for observing human social behaviour at large scale. Today this sector is interwoven with virtually all other economic subsystems and even with the most common tools that we use for communicating with each other.
David Graeber has analysed the phenomenon of “bullshit jobs” in detail.
“In the year 1930, John Maynard Keynes predicted that technology would have advanced sufficiently by century’s end that countries like Great Britain or the United States would achieve a 15-hour work week. There’s every reason to believe he was right. In technological terms, we are quite capable of this. And yet it didn’t happen. Instead, technology has been marshalled, if anything, to figure out ways to make us all work more. In order to achieve this, jobs have had to be created that are, effectively, pointless. Huge swathes of people, in Europe and North America in particular, spend their entire working lives performing tasks they secretly believe do not really need to be performed. The moral and spiritual damage that comes from this situation is profound. It is a scar across our collective soul. Yet virtually no one talks about it. …”
Silicon Valley innovation pop-culture?
Students of software engineering and computer science are often attracted by the idea of “innovation” and by the prospect of exciting creative work, contributing to the development of new services and products. The typical reality of software development has very little if anything to do with innovation and much more with building tools that support David Graeber’s “bullshit jobs” and Edward Bernays’ elitist “utopia” of conscious manipulation of the habits and opinions of the masses by a small number of “leaders” suffering from narcissistic personality disorder.
The culture within the software development community is shaped much less by mathematics and scientific knowledge about the physical world than by the psychology of persuasion – and an anaemic conception of innovation based on social popularity and design principles that encourage planned obsolescence. A few years ago Alan Kay, a pioneer of object-oriented programming and windowing graphical user interface design observed:
It used to be the case that people were admonished to “not re-invent the wheel”. We now live in an age that spends a lot of time “reinventing the flat tire!”
The flat tires come from the reinventors often not being in the same league as the original inventors. This is a symptom of a “pop culture” where identity and participation are much more important than progress. … In the US we are now embedded in a pop culture that has progressed far enough to seriously hurt places that hold “developed cultures”. This pervasiveness makes it hard to see anything else, and certainly makes it difficult for those who care what others think to put much value on anything but pop culture norms.
Mainstream software development practices are geared towards dealing with the characteristics of big ball of mud architectures and the reality of the curse of software maintenance.
Do we need a better language for model building?
Making model building accessible to a wider audience may require developing a cognitively simple visual language for articulating resource and information flows in living and economic systems in a format that is not influenced by any particular economic ideology.
Many of the languages of mathematics already make use of visual concept graphs. Digital devices open up the possibility of highly visual languages and user interfaces that enable everyone to create concept graphs that are formal in a mathematical sense, understandable for humans, and easily processable by software tools. The only formal foundations needed implementing such a visual language system are axioms from model theory, category theory, and domain theory.
In terms of usability, a formal software-mediated visual language system that takes into consideration human cognitive limits has the potential to:
Improve the speed and quality of knowledge transfer between human domain experts
Improve the speed and quality of knowledge transfer between human domain experts and software tools
Facilitate innovative approaches to extracting human understandable semantics from informal textual artefacts, in a format that is easily processable by software tools
Facilitate innovative approaches to unsupervised machine learning that deliver results in a format that is compatible with familiar representations used by human domain experts, enabling the construction of knowledge repositories capable of receiving inputs from:
human domain experts
informal textual sources of human knowledge
machine learning systems
All scientists, engineers, and technologists are familiar with a language that is more expressive and less ambiguous than spoken and written language. The language of concept graphs with highly domain and context-specific iconography regularly appears on white boards whenever two or more people from different disciplines engage in collaborative problem solving. Such languages can easily be formalised mathematically and can be used in conjunction with rigorous validation by example / experiments.
Model building and digital correlation maps can go hand in hand
Machine learning need not result in opaque systems that are as difficult to understand as humans, and a formal visual language may represent the biggest breakthrough for improving the understanding between humans since the development of spoken language.
… And storytelling and social transmission need not result in a never ending sequence of psychopathic social games if we get into the habit of explicitly tagging all stories with the available supporting evidence, so that untested ideas and attempts of corruption become easier to identify.
Mathematics – the language of explanation and validation
Paul Lockhart describes mathematics as the art of explanation. He is correct. Mathematical proofs are the one type of storytelling that is committed to being entirely open regarding all assumptions and to the systematically exploring all the possible implications of specific sets of assumptions. Foundational mathematical assumptions are usually refereed to as axioms.
Formal proofs are parametrised formal stories (sequences of reasoning steps) that explore the possibilities of entire families of stories and their implications. Mathematical beauty is achieved when a complex family of stories can be described by a small elegant formal statement. Complexity does not melt away accidentally. It is distilled down to the its essence by finding a “natural language” (or “model”) for the problem space represented by a family of formal stories.
A useful model encapsulates all relevant commonalities of the problem space – it provides an explanation that is understandable for anyone who is able to follow the reasoning steps leading to the model.
The more parameters and relationships between parameters come into play, the more difficult it typically is to uncover cognitively simple models that shed new light onto a particular problem space and the underlying assumptions. If a particular set of formal assumptions is found to have a correspondence in the physical or living world, the potential for positive and negative technological innovation can be profound.
Whether the positive or negative potential prevails is determined by the motivations, political moves, and stories told by those who claim credit for innovation.
Any hope of progress beyond stories?
From within a large organisation culture is often perceived as being static or very slow moving locally, and changes in the environment are being perceived as being dynamic and fast moving. This is an illusion. It is easy to lose sight of the bigger picture.
Outside the context of “work” the people within a large organisation are part of many other groups and part of the rapidly evolving “external” context. The larger an organisation, the greater the inertia of the internal organisational culture, and the faster this culture disconnects from the external cultural identities of employees, customers, and suppliers.
The resulting cognitive dissonance manifests itself in terms of low levels of employee engagement, high levels of mental illness, and the increasingly short life expectancy of large corporations. Group identities and concepts such as intelligence and success are cultural constructs that are subject to evolutionary pressure and phase transitions.
Marketing may well become a taboo in the not-too-distant future
Over the next few weeks, to my knowledge, there are at least four dedicated conferences on the topics of redefining intelligence, new economics, and cultural evolution.
Conference on Interdisciplinary Innovation and Collaboration
Melbourne, Australia – 2 September 2017
Auckland, New Zealand – 16 September 2017
These events are part of the quarterly CIIC unconference series, addressing challenges that go beyond the established framework of research in industry, government and academia. The workshops in September will build on the results from earlier workshops to explore the essence of humanity and how to construct organisations that perform a valuable function in the living world.
The historic record of societies and large organisations being aware of the limitations of their culture is highly unimpressive. Redefining intelligence is our chance to break out of self-destructive patterns of behaviour. It is a first step towards a better understanding of the positive and negative human potential within the ecological context of the planet.
More information on CIIC and the theme for the upcoming unconference:
Thanks to Pete Rive and Arthur Shelley at AUT and RMIT for providing CIIC with superb venues!
New Economy Conference
Brisbane, Australia – 1-3 September 2017
Building on the inaugural 2016 conference held in Sydney, the 2017 gathering invites people to come together to share stories of success, address challenges and join the broader movement so we can continue working together to build a ‘new’ economic system. The 2017 New Economy Conference will bring together hundreds of people and organisations to launch powerful new collective strategies for creating positive social and economic change, to achieve long term, liveable economies that fit within the productive capacity of a healthy environment.
More information on NENA and the Building the New Economy conference:
The Cultural Evolution Society supports evolutionary approaches to culture in humans and other animals. The society welcomes all who share this fundamental interest, including in the pursuit of basic research, teaching, or applied work. We are committed to fostering an integrative interdisciplinary community spanning traditional academic boundaries from across the social, psychological, and biological sciences, and including archaeology, computer science, economics, history, linguistics, mathematics, philosophy and religious studies. We also welcome practitioners from applied fields such as medicine and public health, psychiatry, community development, international relations, the agricultural sciences, and the sciences of past and present environmental change.
More information on CES and the related conference:







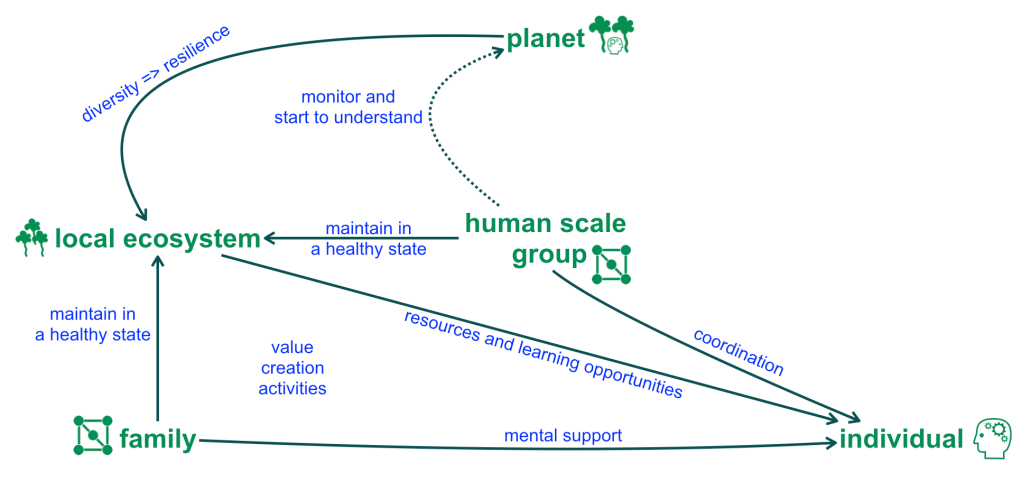
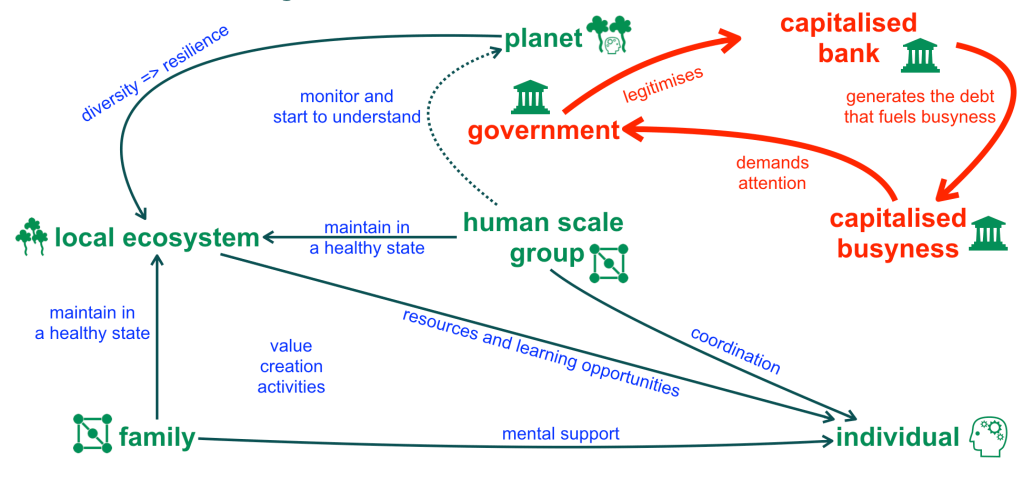

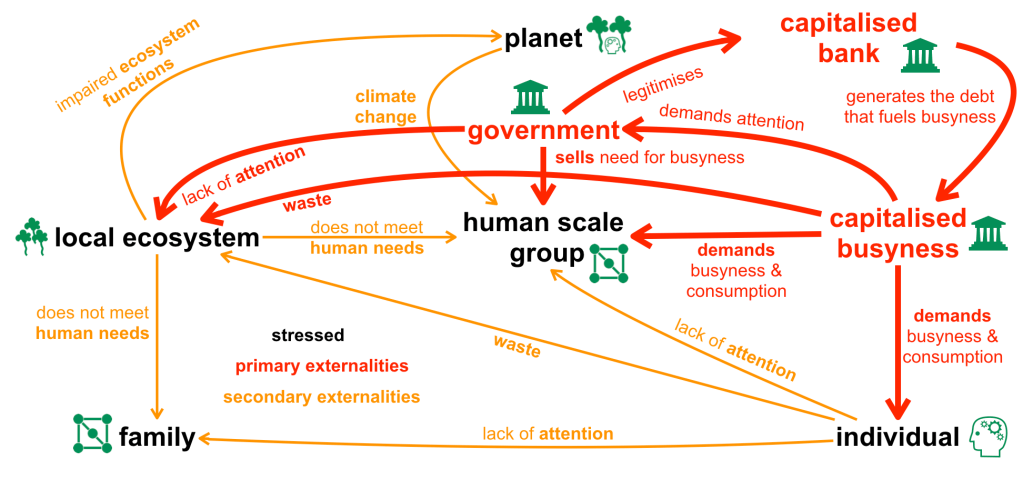
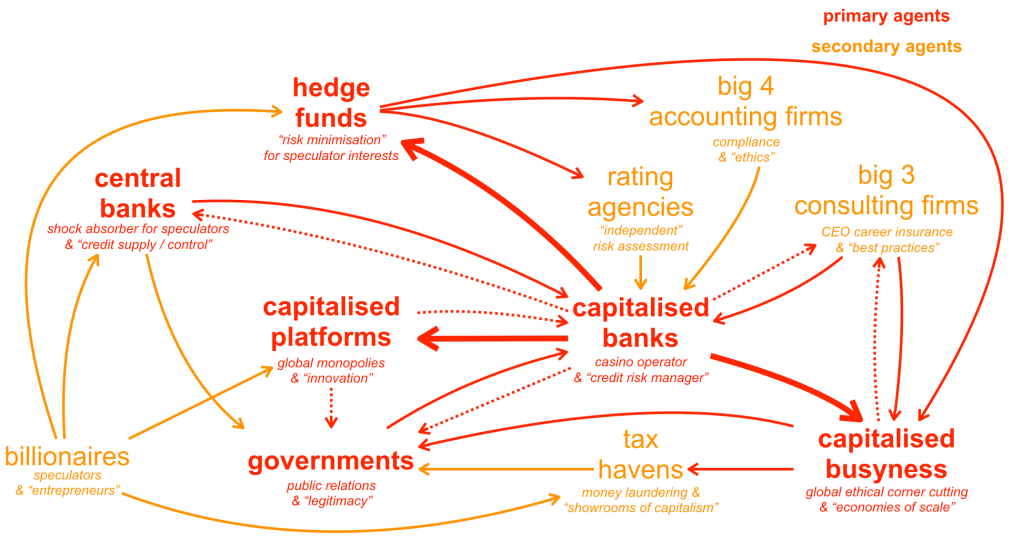

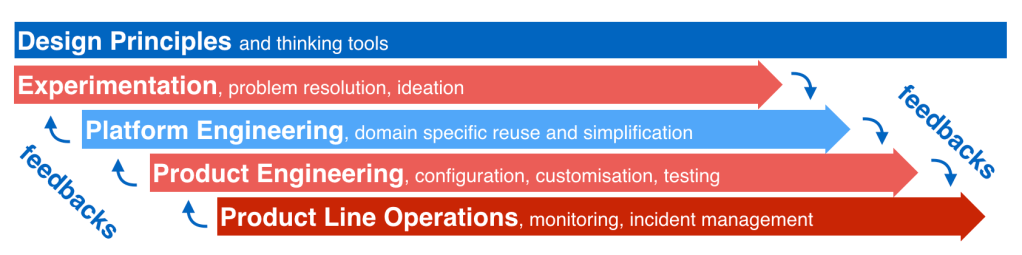




























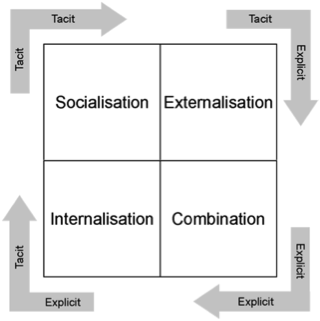






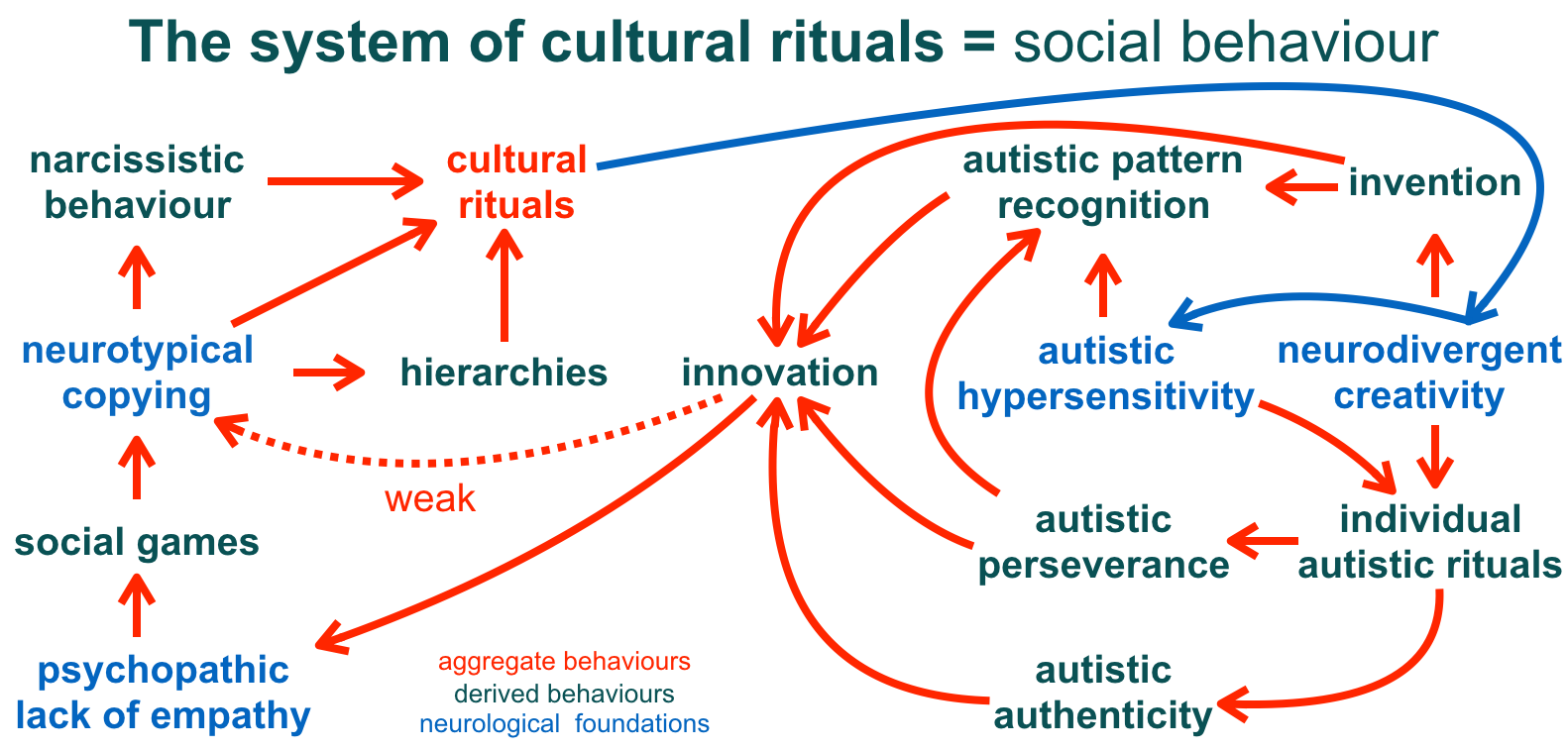

 In all domains where decisions and actions may have significant impact on others and on the environment we live in, adopting a more autistic mindset in relation to human stories may improve human decision making. In the Asch conformity experiment,
In all domains where decisions and actions may have significant impact on others and on the environment we live in, adopting a more autistic mindset in relation to human stories may improve human decision making. In the Asch conformity experiment, 

You must be logged in to post a comment.