The fundamental mismatch between hierarchical anthropocentric ideologies and cultures that embrace conscious collaborative niche construction beyond the human can not be over-emphasised. The former is best understood as a form of cultural disease and the latter is best understood as the natural flow of life that encapsulates 4+ billion years of Gaia’s wisdom.
Homo symbolicus is the result of co-evolutionary processes (within groups and between groups) within the context of a species in which the capacity for symbolic culture was emerging.
Humans applied their indigenous understanding of co-evolutionary processes within an ecological context, consciously engaging in co-evolution with plants and later animals. What modern anthropocentric humans fail to see is the extent to which “selective breeding” is a co-evolutionary process, to which the plants and animals are contributing as much as the humans.
The human capacity for culture is the unique human capacity for rapid co-evolution at human scales, at a speed that is several times faster than the speed of genetic evolution.
All novel forms of problem solving in the living world involve co-evolutionary ecological processes – a combination of creativity and collaboration. Co-evolution has been the big evolutionary story of biology all along, long before humans co-evolved the capacity for symbolic culture.
Another example of tool assisted co-evolution and creative collaboration is the co-evolutionary meta modelling / co-design paradigm for filtering, human scale collaboration, multi-level modelling, and omni-directional learning that emerged from S23M’s Cell Platform prototype, which includes support for a formal 4-state Information Quality (IQ) logic (true, false, unknown, not-applicable), allowing humans and machines to document shared understanding and consensus with confidence and precision.
The above presentation provides a conceptual overview. You can listen to a corresponding audio recording for further explanations. Rather than synchronising the slides and the audio, the cognitive friction of manually scrolling through the slides may allow more information to be retained.
It is straight forward to extend Information Quality logic with probabilistic logic and reasoning for all those cases where available model instances (evidence and measurements from the bio-physical-social world) justify the calculation of well informed probabilities. A system like the Cell Platform can serve three complementary purposes:
As a formal visual graphical notation for making explicit, validating, and creatively working with semantic models (human domain expertise)
As a formal software processable notation and API for making human comprehensible semantic models available to machine learning algorithms
As a formal software processable notation and API for storing and retrieving the results from machine learning algorithms
As a formal reasoning system that combines Information Quality logic with empirically sourced probabilities from observations in the bio-physical-social world, which is capable of reasoning about certainty and relevance in a way that is comprehensible for humans
Among other things such a system will be able to take into account the physical limits of predictability of complex adaptive bio-physical-social systems, and can serve as a trustworthy tool in applying the scale-aware precautionary principle in relation to specific goals and limits of risk tolerance specified by humans.
The visual meta language of evolutionary design encapsulates and formalises timeless principles that can be traced back to the earliest rock paintings and diagrammatic representations, which enabled important knowledge and wisdom to be transmitted reliably in otherwise largely oral human scale cultures over tens of thousands of years.
Homo economicus: Cults based on addictions to power & convenience
The obsession with so-called artificial intelligence is a logical extension of the WEIRD anthropocentric delusion, a version 2.0 of individualistic homo economicus that appears to have shed the shackles of biological limitations
… until one of the long forgotten or emergent unknowns and no-longer-applicable assumptions throws a spanner into the gears of the mechanistic probabilistic house of cards of predictability, replacing one set of apparent certainties with another.
The following interview provides a rare and refreshingly honest perspective on the current capabilities and limitations of so called artificially intelligent systems, and perhaps even more importantly, it underscores the co-evolutionary nature of creativity, by distinguishing the current skill acquisition capabilities of artificially intelligent systems from the ability to creatively blend frames and symbolic metaphors to apply them to entirely new contexts.
Francois Chollet offers a good overview of the formal techniques and the cultural beliefs that are baked into current artificially intelligent systems, and makes many astute observations that I agree with. I won’t repeat them here. Instead, take the time to listen to the excellent level headed interview. In summary, doom-mongering is just as unwarranted as delusional beliefs that artificial superintelligence will ultimately make biological life redundant.
There are several topics on which my perspective differs from or extends Francois Chollet’s assessment in a notable way. For tools to be useful for human societies, artificially intelligent systems need to be specifically designed and constrained as follows:
Integration with symbolic reasoning systems that support Information Quality logic, i.e. agent-context-aware semantics of unknown and not-applicable alongside the semantics of probabilities associated with the semantics of true and false.
From the observed level of neurodiversity among humans, and also from the non-linear visual symbolic representations produced by per-historic humans, we know that linear language has never been the only conscious indexing and thinking tool.
To reduce the unavoidable misunderstandings that go along with an over-reliance on linear language, human comprehensible visual models need to complement linear language as part of the interface with artificially intelligent systems.
Artificially intelligent systems need to be tied to (a) goals of human scale groups, and their results must be recognised as part of the culture of such groups or to (b) purely scientific research goals, the results of which must be shared and made accessible as part of a global knowledge commons.
The consumption of energy and resources needed to construct data centres and artificially intelligent systems needs to be factored into the extent to which building such systems is advisable and potentially useful.
We can learn a lot about intelligent systems from studying living systems not limited to animals with nervous systems – all living systems, from single celled organisms all the way up to ecosystems, have some form of intelligence, i.e. forms of intelligence that are not easily (if at all) comprehensible at human spatial and temporal scales.
I am even more pessimistic or cautious about our ability to understand the phenomenon of consciousness.
On the last two points, I am leaning towards a panpsychic philosophy, based on the observation that the simplest learning system is a feedback loop between two subsystems or components that are capable of storing a single bit of information that may alter their response to further sensory / external input.
It may well be possible to teach future artificially intelligent digital systems that are integrated with multi-level human scale symbolic modelling capabilities and support for Information Quality logic how to creatively blend frames and symbolic metaphors, but this will not be achieved by resource intensive and incredibly wasteful brute-force attempts within the limited frame of probabilistic reasoning. This will involve shifting from the competitive individualistic paradigm of “intelligence” – which mirrors the competitive ideology of homo economicus, to a paradigm of creative collaboration – which mirrors the relational way in which humans think and collectively and creatively make [adaptive] sense of the world at human scales.
We currently live in a world of co-evolved human scale homo symbolicus, with delusional institutions and digital tools that religiously calculate and predict the behaviour of homo economicus. A fitting quote:
In our work we’ve tried to test some of the basic predictions made by the Homo economics model using some simple tools from behavioral economics applied across a diverse swath of human societies. Not only do we find that the Homo economicus predictions fail in every society (24 societies, multiple communities per society), but instructively, we find that it fails in different ways in different societies. Nevertheless, after our paper “In search of Homo economicus” in 2001 in the American Economic Review, we continued to search for him. Eventually, we did find him. He turned out to be a chimpanzee. The canonical predictions of the Homo economicus model have proved remarkably successful in predicting chimpanzee behavior in simple experiments. So, all theoretical work was not wasted, it was just applied to the wrong species.
Homo ecologus: Cultures based on trust & mutual understanding
The big milestones along the way were events in which simpler forms of life entered into complex collaborations, resulting in multi-celled forms of life, and increasingly complex nested ecologies of multi-celled forms of life.
The fundamental logic of life is relational rather than individualistic and competitive. The complexity and diversity of life are the result of 4+ billion years of co-evolution. The research of Camillia Power in combination with the experimental work of Michael Tomassello provides compelling evidence for the co-evolutionary paradigm shift that occurred as part of the evolution of homo sapiens, i.e. homo symbolicus with a capacity for symbolic language and culture. The latter capabilities enabled humans to out-collaborate other primates in terms of adaptiveness and integration into a diversity of ecological niches. Creative and non-hierarchical collaboration allowed humans to transcend the collective limitations of other primates.
On evolutionary time scales all competitive and anthropocentric human empire building attempts are very short-lived and ecological misalignments that quickly get corrected by the timeless wisdom of 4+ billion years of co-evolution. The current human cultural disease that maximises human busyness and stress, has triggered co-evolutionary processes within Gaia. These processes are kicking in incredibly rapidly, clamping down on the myopic mono-species frame of evolution.
Digital automation has made the human world increasingly busy and event oriented, and less and less flow oriented. Neither we nor our machines understand any of the super-human scale systems we have created to the level needed to avoid existential risks from materialising.
Outsourcing all thinking and thinking tools to machines is a stupid idea. Automated agents can only become increasingly useful assistants if we can relate to them at human scale – if we can easily communicate our motivations and values, and if they then assist us with actions that reflect our motivations and values.
Just like pocket calculators are useful cognitive tools, as long as we don’t lose sight of the hard limits of predictability, more advanced human scale assistants can provide us with calculated results much faster and more reliably than we can ourselves. The wise use of this capacity lies not in generating further busyness and yet another arms race in yet another attempt of outsmarting Gaia and each other, but in freeing up time for reconnecting with our ecological context at comprehensible scales.
“A small country has fewer people. Though there are machines that can work ten to a hundred times faster than man, they are not needed. The people take death seriously and do not travel far. Though they have boats and carriages, no one uses them. Though they have armor and weapons, no one displays them. Men return to the knotting of rope in place of writing. Their food is plain and good, their clothes fine but simple, their homes secure; They are happy in their ways. Though they live within sight of their neighbors, And crowing cocks and barking dogs are heard across the way, Yet they leave each other in peace while they grow old and die.”
Translated by Jane English, 1972, Chapter 80
Beyond that, advanced human scale assistants will be able to explain their reasoning process in a language that we can understand – but only if we do not unlearn how to think critically and creatively. We must not let naive biases from the information age (big data as the new oil / competitive advantage, fear of “intelligent” machines etc.) blind us and prevent us from seizing the cosmolocal collaborative advantages offered by the digital knowledge age.
Mutual trust is a biophilic ecological phenomenon of emergent local predictability that is not limited to humans. In a dynamic ecological context, enduring relationships of mutual trust constitute the ingredients of a life affirming ecology of care that is integrated into the regenerative cyclical flow of life.
Healing starts with rediscovering our faith in humanity. The sacred cycle of life includes the joy of birth, the art of living well, and the process of dying in good company, and thereby giving back nutrients to the living planet. We heal by following our heart. We reduce cognitive dissonance by being human – by sobering up, by rejecting the life denying mono-cult, by seeing the beauty in all living beings.
In summary, to adapt to the co-evolutionary processes within Gaia that are already in progress, instead of perpetuating the momentum of machine assisted and fossil fuelled busyness as a “solution”, we are well advised to step off the busyness accelerator, and realign human culture with our biological evolutionary heritage:
Limit the scope of our attention to comprehensible human scale
Optimise for mutual trust and mutual aid rather than for profit for external financial investors, adopt compassionate cooperative social operating models
Openly acknowledge and embrace unknowns to catalyse omni-directional learning
Openly acknowledge considerations that are not-applicable within our human scale ecological contexts
Celebrate the wonder of life, acknowledge the relevance of the bigger bio-regional and planetary context via our understanding of the natural sciences and in abstract spiritual terms, and avoid becoming overwhelmed by anthropocentric hubris
Use modern technology for cosmolocal omni-directional learning at human scale, and engage in cosmolocal collaborative niche construction
Recognise and provide assistance to those who are predisposed to addictions to social power and convenience, without tolerating any establishment of social power gradients
It is not an accident that permaculture principles are spreading like wildfire at a grassroots level. This is a healthy cultural immune response from sober homo symbolicus. In the misguided mono-species dominator model of cultural evolution, culture “is handed down” from god-like authorities.
Gaia is facing a metacrisis. But humanity is primarily facing a crisis of institutions and collective imagination. Many of us would be unable to recognise a healthy human scale cultural organism if we encountered one. This should scare us all.
“One who seeks knowledge learns something new every day. One who seeks the Tao unlearns something new every day. Less and less remains until you arrive at non-action. When you arrive at non-action, nothing will be left undone. Mastery of the world is achieved by letting things take their natural course. You can not master the world by changing the natural way.”
Laozi, Translated by John H. McDonald, Chapter 48
Perhaps the scariest part of all for modern humans is the thought that we may have to give up all ambitions of attempting to actively shape the world beyond the scope of our local human scale.
Plotting graphs of anthropocentric economic “externalities” and their effects in terms of temperature anomalies and energy imbalances speaks louder than many thousand words.
Human-induced greenhouse gas emissions
Observed temperature anomalies and energy imbalances
Temperature anomalies in 1950: no clear trend to observe
Temperature anomalies in 1975: no clear trend to observe yet
Temperature anomalies in 2000: a clear increase compared to 25 years earlier
Temperature anomalies in 2024: a continuation of the established trend
Collapse and Ecocide as religious failure
It is time to acknowledge the sanctity of all living beings, including Gaia, and to commit to nurturing life.
“Being very easy to comprehend, These teachings are simple to practice. Yet, few are they who will release ego sufficiently to achieve understanding, let alone the ability to practice.
These teachings have their source in nature, Their master is the Tao. Not comprehending this, People find great difficulty in understanding the Sage. So, with few people really understanding him, He is most highly valued.
Thus the Sage, Tho’ presenting a poor appearance, to the world, Yet carries the riches of nature embedded in his core.”
Laozi, Translated by Alan B. Taplow, 1982, Chapter 70
The parties on the deck of the Titanic must continue until the last minute. This is how civilisations die. The analysis of modern elections by Hans Georg Moeller, goes some way to explain the paradigmatic cultural inertia that has culminated in the predicament we are now facing. Hans Georg Moeller is a German philosopher who has spent much of his career studying Chinese philosophy in Macau. In his analysis he draws on the works of 20th century French and German media theorists and sociologists.
To better understand the direction of the paradigmatic inertia of neoliberalism it is worthwhile reading Umberto Eco’s essay ‘Ur-Fascism’ (1995) in its entirety, which is based on first hand experience of fascism in Italy.
In spite of this fuzziness, I think it is possible to outline a list of features that are typical of what I would like to call Ur-Fascism, or Eternal Fascism. These features cannot be organized into a system; many of them contradict each other, and are also typical of other kinds of despotism or fanaticism. But it is enough that one of them be present to allow fascism to coagulate around it.
The above observation poses a challenge to all super-human scale groups, because some of the 14 features described in the essay are an inevitable consequence of super-human scale civilisation building attempts.
For Ur-Fascism there is no struggle for life but, rather, life is lived for struggle. Thus pacifism is trafficking with the enemy. It is bad because life is permanent warfare.
This feature has been part of homo economicus since the beginning of the colonial era, and it has been perpetuated ever since. It is evident in the language of war that dominates US politics: the war against communism, the war on drugs, the war on terror, the war against [the other party], etc. The cult of homo economicus, in its neoliberal incarnation, has fascist characteristics. Fascism arrived many years ago, and the cancer has had time to grow.
The biosphere is suffering severely from the cultural cancer of homo economicus. Ecological overshoot is the direct result of the misguided religious belief in the god of the invisible hand.
The modern Military Industrial Complex weaves together big corporations and big government agencies into a highly resilient form of power. Elite power is not centralised in any single person, but is distributed across multiple corporations and institutions. Yanis Varoufakis talks about technofeudalism. Sheldon Wolin described this form of totalising power as inverted totalitarianism. The US is already the world champion in the reliance on guard labour. Full blown fascism is simply a matter of cranking up the violence dial of well established institutions of guard labour.
To people who feel deprived of a clear social identity, Ur-Fascism says that their only privilege is the most common one, to be born in the same country. This is the origin of nationalism. Besides, the only ones who can provide an identity to the nation are its enemies. Thus at the root of the Ur-Fascist psychology there is the obsession with a plot,
In my experience growing numbers of people, on all continents, are wary of nationalism. Today, nationalism is strongest in the Anglosphere, in what I refer to as the ruins of the British Empire, which includes the American Empire. It is present in Aotearoa too, but thanks to the explicit commitment to an anti-nuclear stance across all parties, in a somewhat weakened form.
Ur-Fascism is based upon a selective populism, a qualitative populism, one might say. In a democracy, the citizens have individual rights, but the citizens in their entirety have a political impact only from a quantitative point of view – one follows the decisions of the majority. For Ur-Fascism, however, individuals as individuals have no rights, and the People is conceived as a quality, a monolithic entity expressing the Common Will. Since no large quantity of human beings can have a common will, the Leader pretends to be their interpreter. Having lost their power of delegation, citizens do not act; they are only called on to play the role of the People. Thus the People is only a theatrical fiction.
This observation is consistent with Hans Georg Moeller’s critique of the spectacle of elections in the neoliberal era, and the implied lack of continuous deliberative dialogue to nurture mutual understanding.
This new culture had to be syncretistic. Syncretism is not only, as the dictionary says, “the combination of different forms of belief or practice”; such a combination must tolerate contradictions. Each of the original messages contains a sliver of wisdom, and whenever they seem to say different or incompatible things it is only because all are alluding, allegorically, to the same primeval truth. As a consequence, there can be no advancement of learning. Truth has been already spelled out once and for all, and we can only keep interpreting its obscure message.
Giving up the fascist obsession with social control at super-human scales entails shifting from the tiny frame of the Overton window of homo economicus towards an expanding sphere of discourse around ecologies of care beyond the human via a practice of deliberative [de-powered] dialogues in Open Space, at human scales.
“The Taoist has no opinions He simply listens, and acts He treats those who are good as worthy He treats those who aren’t good as worthy, too And so he finds their goodness He gives those who are honorable his trust He gives those who are dishonorable his trust, too And so he gains their trust.”
Laozi, Translated by Ted Wrigley, Chapter 49
Healthy cultural organisms emerge from a process of collaborative niche construction, and not via the not-so-invisible hand of powered-up unfettered capital interests:
Consistent use of the language we use matters, giving us shared frames and metaphors, shared understanding, and the ability to articulate shared values.
Acknowledging human emotional and cognitive limitations matters , as it gives us a visceral understanding of human scale.
Education in thinking tools rather than dogma matters, giving us access to timeless Daoist wisdom, indigenous wisdom, and neurodivergent wisdom.
Genuine appreciation of diversity matters, as it encourages us to engage in collaborative niche construction.
“Tao creates all things, Virtue nurtures them. Matter gives them forms, and Environment allows them to succeed. Thus all things honour Tao and value Virtue. Tao being honoured and Virtue being valued, They always occurred naturally without being dictated by anyone.
Thus:
Tao creates all things. Virtue nurtures them: They grow and develop; Bear fruits and mature; and Are cared for and protected. To create, but not to possess; To care for, but not to control; To lead, but not to subjugate. This is called the profound virtue.”
Laozi, Translated by Cheng, Chapter 51
Otherwise the door is open for fascism to grow and dominate. Together with my friends and colleagues I have been working on these topics for many years.
We need commitment, we need community. We need to create spaces of trust. But for that, there’s tremendous work that we need to be doing. But I don’t think that any of that work will be possible, should we not have that commitment–that commitment that no matter how challenging and tremendously difficult it will be to reckon with these narratives and to dismantle these narratives. Because seeing the horror in the eye of all these narratives that we live by comes with tremendous understanding. It will leave us very fragile, very vulnerable, and most, of course, are not willing to do that, because we don’t feel safe. But if we are able to stand the heat and create these spaces, if we commit to do this kind of work for the benefit of the planet, then we may be able to learn that we can fly.
The god of the invisible hand is a collective learning disability. The notion of technological innovation in the neoliberal era, to use Andre Spicer’s terminology, is a form of “sanctified bullshit”.
“If I possess even the smallest bits of wisdom, I would walk the great way, and my only fear would be in straying from this great road. The great way is wide and the going is easy, but how people seem to prefer the side paths. When the offices of government, the palaces and temples are richly adorned, and lavishly outfitted, when the ministers are concerned chiefly with pomp and display; the fields will be dusty and overgrown with rank weeds, and the granaries of the land will be bare. The gentry wear elaborate richly embroidered clothes, eat and drink in excess with their sharp swords at their sides, these are surely the robber barons. This is not in keeping with the Way.”
Laozi, Translated by John Dicus, 2002, Chapter 53
It is time to tune into the diversity of life around us, rather than to continue taking away from life more than we need at human scale.
Healing from cultural cancer
It is only once we have rediscovered a reasonable understanding of the notion of human scale potential and limitations that we can begin to make sense of the metacrisis within our local contexts and then to act accordingly, nurturing the emergence of healthy human scale cultural organisms.
“What is well planted cannot be uprooted. What is well embraced cannot slip away. The descendants will carry on the ancestral sacrifice from generation to generation.
Cultivate Virtue in your own person, and it will be genuine. Cultivate it in the family, and it will be more than sufficient. Cultivate it in the village, and it will last long. Cultivate it in the state, and it will flourish abundantly. Cultivate it in the world, and it will become universal.
Hence, a person must be perceived as person; a family as family; a village as village; a state as state; the world as world. How do I know about the world? It is through this.”
Laozi, Translated by Tien Cong Tran, Chapter 54
“The Tao may appear to be idealistic, but if you can put it into practice, you realize its greatness. There are three traits which are required.
1. Compassion. 2. Patience. 3. Humility.
Compassionate and you can face things the way they are Thus you can forgive yourself of any mistake. Patient and you remain unmoved until the right opportunity arises. Humble and you overcome self-importance, thus the ego. In following the Tao, these are your three most valuable treasures.”
Laozi, Translated by David Bullen, Chapter 67
The above documentary consists of interviews with leading climate researchers, mainly from the Potsdam Institute for Climate Impact Research. It features many well made graphical explanations that complement the explanatory narrative.
The graphics are helpful to get an intuitive understanding of the different time scales and of the rates of temperature changes that planetary systems have (not) experienced in the past. The documentary represents the official scientific consensus, i.e. it represents a “conservative” picture of where we are currently at in terms of crossing tipping points that trigger positive self-reinforcing feedback loops.
Many climate scientists who specialise in a specific domain and specific tipping points, say the Greenland ice sheet, the West Antarctic ice sheet, or the Amazon Rain Forest, believe that some tipping points have already been crossed. One way to think about the uncertainty is that the observed data from all our scientific instruments tells us that we on the cusp of the point where the climate slowly and irreversibly slides into a state that no human and no other mammal has ever experienced.
Gaia is having a fever that is fighting anthropocentric cultural cancer. We are well advised to listen to Gaia, to observe what is happening to the animals and the other living beings in the biosphere. By the time the rats start leaving the ship, the political parties on the Titanic have become irrelevant. Life continues, in accordance with the boundaries dictated by Gaia, and not according to the delusional logic of growth based economics.
Irrespective of exactly where the climate system is at, the cultural paradigmatic inertia of established institutions is such that it has become nearly impossible to prevent one or more tipping points from being crossed within the next 25 years.
Cultural paradigmatic inertia is a social problem, a domain that climate scientists are not well equipped to assess. But simply from lived experience, many climate scientists are extremely worried about the observed paradigmatic inertia.
Plotting the rise in CO2 and temperatures over the course of the industrial era, we can see that the rates at which CO2 and temperature are rising are accelerating. This is an ominous sign that tipping points may be reached or breached.
The effects in terms of the power of extreme weather events are exponential. This is what we are now seeing and experiencing with record breaking floods, storms, temperatures, and droughts all over the planet. New records are set every year. The destructive effects and the casualties caused by extreme weather events are going up correspondingly.
The trend of exponentially more powerful and more frequent extreme weather events will continue as long as humans are adding further greenhouse gasses to the atmosphere. This is something that politicians and government departments are ill equipped to comprehend and appreciate. Acknowledging this reality would have massive impacts on the priorities for climate adaptation policies and related investment decisions.
What we are increasingly observing is that human built infrastructure is being overwhelmed by record breaking extreme events, and that politicians and governments are in reactive mode. “Rebuilding” infrastructure in the same places and to similar specifications as in the past is going to become more and more a game of building sand castles in the tidal zone. It is becoming more and more expensive and resource intensive, and eventually it will become futile.
Socially and ecologically responsible policies now would need to be policies of coordinated retreat from obvious zones of increasing dangers, and assisted migration towards zones that are geographically less exposed to the forces of powerful extreme weather events. Such policies can only come into being if the notion of “growth based economics” is abandoned. At this point in time neither the politicians nor the majority of voters are prepared to take this step of “breaking” the growth based economic paradigm.
In the rear view mirror of history the refusal to abandon growth based economics will be viewed as a form of collective insanity.
Therefore anyone who understands the current state of the climate system is well advised to independently assess the situation, and to plan and act accordingly – and not to wait for government departments to offer trustworthy advice and guidance. Established institutions consistently underestimate the risks and the full downstream effects of extreme weather events.
The path towards sobriety
“She who follows the way of the Tao will draw the world to her steps. She can go without fear of being injured, because she has found peace and tranquility in her heart.
Where there is music and good food, people will stop to enjoy it. But words spoken of the Tao seem to them boring and stale.
When looked at, there is nothing for them to see. When listened for, there is nothing for them to hear. Yet if they put it to use, it would never be exhausted.”
Laozi, Translated by J. H. McDonald, 1996, Chapter 35
Acknowledging all our fears, facing the pain, and turning fears into courage:
Fully letting go of the WEIRD delusion of the self – exiting the cult of the self. This includes letting go of all the internalised ableism that permeates WEIRD social norms, and weaning ourselves off all of the addictions that stand in the way of committing to sacred relationships.
Fully letting go of the WEIRD delusion of technological progress – exiting the cult of busyness. This includes incrementally weaning ourselves off all the conveniences afforded by the availability of fossil fuels.
“The Tao never acts with force, yet there is nothing that it can not do.
If rulers could follow the way of the Tao, then all of creation would willingly follow their example. If selfish desires were to arise after their transformation, I would erase them with the power of the Uncarved Block.
By the power of the Uncarved Block, future generations would lose their selfish desires. By losing their selfish desires, the world would naturally settle into peace.”
– Translated by John H. McDonald, 1996, Chapter 37
Most importantly, we must acknowledge that we can not regain sobriety alone, in self-isolation, and we can only relearn to be fully human at a scale that is compatible with our biological cognitive and emotional limits, neither at smaller scales, nor at larger scales.
Healthy cultural organisms do not consist of:
Isolated individuals
Atomised nuclear families
Incomprehensibly complex groups and institutions
In fact, the relational nature of the big cycle of life is obscured as long as long as we attempt to define cultural organisms as groups of people or even groups of living beings beyond the human.
The human capacity for language would not have given us any adaptive ecological advantage if it did not primarily serve the purpose of improving our ability to understand, trust, and rely on each other, and thereby to enable us to engage in collaborative niche construction at human scale – such that every human in a cultural organism to some extent contributes unique capabilities and lived experiences to the cultural organism.
“The source is a mother. Nature is her child. To know the mother, know the children. They – you – will always return to her. They – you – will persist in death. Stop your chattering, close your eyes and find the still moment that is the center and the end of life. Find truth even, or especially, in what is smallest. Let the light bathe your body. Live.”
Laozi, Translated by Crispin Starwell, Chapter 52
All of this is compatible with what we know about the innate collaborative inclinations of human babies to assist other humans who seem to be struggling – including strangers who are not familiar care givers. It also points to an innate predisposition towards highly egalitarian cultures, which counteracts the latent capacity for establishing dominance hierarchies that we share with other primates. There is a substantial body of anthropological evidence for this claim, which stands in obvious opposition to the dominant modern economic doctrine.
“The movement of Tao in the course of time is to return to Simplicity; The working of Tao is so subtle that is ostensible effect may not be immediately noticeable. Myriad things and creatures on Earth were originated from something; This something describable by us was launched ultimately from nothing which is beyond our description.”
Laws and social norms in industrialised societies have been shaped by the metaphor of society as a factory and the metaphor of people as machines more than most people realise. In the emerging technoverse, biological life is perceived as becoming irrelevant. The many ways in which atomised nuclear families depend on abstract institutions is considered normal, and all those who depend on assistance from others in unusual ways are pathologised. Social power can be understood as the privilege of not needing to learn. As we live through the current human predicament we are well advised to understand capitalism as a collective learning disability that actively contributes to human and non-human suffering. A holistic social justice approach rather than a mechanistic rule based approach to collaboration between groups is at the core of the neurodiversity, disability, and indigenous rights movements.
The preoccupation with technology and the exploitation of fossil fuels to expand industrial production accelerated following WWII, fuelling an illusion of infinite growth on a finite planet (Meadows et al. 1972). Anthropocentric confidence in technology and growth seems to have peaked in the 1980s, when neoliberalism was installed around the world as the future engine of wealth and prosperity.
Under the hood, the neoliberal engine was powered by the availability of computers and software, and by the economic logic of Moore’s Law (1965). The entanglement of digital communication technologies and neoliberal economics can be understood by examining the evolution of the dominant and most profitable use cases for digital automation.
Initially, the automation of logistics afforded by computers, software, and robotics allowed the production of material goods to be increased without the need for additional workers. By the 1990s however, many wealthy Western countries had reached a level of material affluence, automation, and offshoring that made it difficult to generate further profits from industrial automation. Instead, the invention of networked computing and the Web opened up new opportunities for economic growth in the abstract, non-physical digital realm, which was sold to investors and entrepreneurs as a virtually unlimited territory that awaited to be conquered – powered by the magic of Moore’s Law and neoliberal ideology (Palmer 2006).
Economic activity and the focus of automation thus shifted into domains that were one or more levels removed from the physical realm, i.e. into various forms of financial speculation, including the development of complex derivatives and entangled bundles of financial products. This increased the leverage of capital and the velocity of financial transactions, culminating in high frequency trading, speculative asset bubbles, and in the Global Financial Crisis of 2008.
Laws and social norms in industrialised societies have been shaped by the metaphor of society as a factory and the metaphor of people as machines more than most people realise. Humans are referred to as human ‘resources’, and human lives are assessed in terms of ‘net worth’ and ‘purchasing power’ (Hedges 2021). As these metaphors have expanded into the digital realm, they have not only warped our relationship with the natural world and our conception of humanity. They have also led to technocratic cults, in which corporations have taken on the role of sacred places of worship, and in which CEOs are the high priests, praising the divine qualities of artificially intelligent technologies (Rushkoff 2023). In the emerging technoverse, biological life is perceived as becoming irrelevant. When society is a factory, the only things that count in are things that can be measured (Deming 1982, 1984).
It is no coincidence that Taylorism, so-called scientific management, was conceived in the wake of the invention of the steam engine and machine assisted manufacturing, to complement the the laws of physics that governed the mechanics and the productivity of the machines on the factory floor.
Formalising the discipline of economics with mathematical tools allowed the scientific approach to managing humans to be extended to the scale of nation states – another conceptual building block for organising human activities in industrialised societies. There are a number of parallels between the impact of the development of economic theories on human society and the social impact of the development of the Internet.
Neither the Internet nor economics draw directly on an evidence based understanding of physics, biology, and human behaviour. Both the Internet and economic theories are best understood as prescriptive rather than as observational tools, as language systems that are based on specific European and North American cultural conventions that are assumed as ‘sensible’ (common sense) or ‘obvious’ (self-evident). With these language systems in place we can measure data flows and economic performance, but only in terms of the scope and the preconceived categories afforded by the formal protocols and languages (Rees 2023), (Alkhatib 2021), (Bowles 2016).
The introduction of a formal economic language system and the introduction of formal protocols for digital communication have shaped human culture around the social ideologies espoused by early industrialists and early information technology entrepreneurs. Over course of the last two centuries governments have become increasingly dependent on economists and information technology entrepreneurs in order to understand and engage with society, and also to understand what what technological options are on the horizon, to the extent that corporations directly advise heads of states (Pennington 2023). In this process anything that lies beyond the scope of what is deemed relevant or acceptable is discounted as non-essential or unproductive.
In the multiple bottom line approaches that have become popular in the context of the United Nation’s Sustainable Development Goals, the conveniently simplistic thinking becomes evident when metrics from the natural world are translated into monetary metrics, as if a monetary number can adequately represent the loss of biodiversity and the destruction of entire ecosystems in the name of economic progress.
Astute observers have been lamenting the chasm between digital hype and the way that technology manifests in our lives for decades (Nelson 1999). Based on what we have seen so far, we have to conclude that the design of digital services, when conducted within the bowels of transnational corporations, with millions and in some cases billions of users, without giving these users the ability to shape the design, is a form of corporate social engineering, whether intentional or not.
Social consequences of neoliberal ideology
The institutions and accepted cultural practices of the modern globalised world that consistently prioritise free flow of capital are traumatising the entire planet. The polycrisis, which is the modern human predicament that we are all living through, can be illustrated with three short cultural narratives:
‘Prayer for the Earth: An Indigenous Response to These Times’ (Rushworth 2024).
The effects of the one-dimensional logic of global capital, illustrated by looking at the overall cultural and ecological impact on the small island nation of Nauru (Çenet 2023)
The effects of the arbitrary anthropocentric cut-off points (Bettin 2024) of the bell curve in the social realm, illustrated by looking at the overall cultural and ecological impact on a small island nation such as Tuvalu (Malie, G. et al. 2023).
These narratives illustrate the cognitive and emotional blindspots that are baked into ‘normality’.
The life destroying impact of the modern human obsession with measuring, and then reducing the dimensionality of all problem spaces to the one-dimensional metric of financial capital can hardly be overestimated. The classic novel Flatland (Abbott 1884) comes to mind. Flatland illustrates the confusions and the loss of meaning created by reducing four dimensional spacetime to two spatial dimensions and the dimension of time, i.e. a reduction of a four dimensional problem space to three dimensions.
The semantic chemical building blocks of the biological world we inhabit contain thousands of dimensions. If we add emergent phenomena at larger levels of scale, we live in a world of millions and billions of semantic dimensions. We all have our own unique way of making sense of the world, from the perspective of the relational ecology of care that surrounds us.
And yet, we live in a world where human social affairs, across all levels of scale, are dominated by a one-dimensional metric. Some still recognise that there is biological life beyond finance, but our minds have been warped by extensive exposure to a one-dimensional metric.
The Anglosphere is leading the world in legal engineering and perception management.
A social systems theory for the digital era
The pioneering work on a universal social systems theory by Niklas Luhmann (JSTOR 2021) in the 1970s through to the 1990s provides a deep and insightful analysis of the effect that the emergence of modern one-to-many communication technologies, i.e. mass media, has had on the evolution of social systems. Many of Luhmann’s insights have only gained relevance in our era of ubiquitous many-to-many communication technologies, i.e. digital social media, which are controlled by global technology corporations.
Luhmann’s perspective and working method were informed by his background as a legal scholar. His work relied heavily on his idiosyncratic ‘Zettelkasten’ note-taking method, over the course of thirty years resulting in a set of drawers with over 90,000 index cards for his research. A digitised archive of all his index cards is available online in the Niklas Luhmann Archiv (University of Bielefeld 2024).
In Niklas Luhmann’s theory of social systems, culture is analysed and constructed at a population level scale that transcends human cognitive and emotional limits, in the form of explicit communication between abstract social subsystems, such as the media system, the legal system, the family system, the economic system, etc.
The illusion of technocratic control
Attempting to explain cultural evolution of socially powered-up super-human scale societies from a top-down, outside-in perspective is appealing from the perspective of the established institutional landscape. The top-down approach prioritises the perspective of so-called authorities over the perspectives of the thousands and millions of local and cosmolocal (Niaros et al. 2020) communities that shape lived experiences at human scale.
On the surface, mass media and digital social media seem to expose billions of humans to billions of perspectives. Upon closer examination this assumption turns out to be an oversimplification that obscures important systemic social power differentials. A small number of mass media organisations and social media celebrities have audiences that measure in the millions and billions, but at the receiving end of all acts of communication, all humans are constrained by cognitive and emotional limits, and by the physical limit of days that are constrained to 24 hours. By design, mass media and social media algorithms guarantee that a very small number of perspectives benefit from being thousands or millions of times more visible than others (Metzler et al. 2023).
Digitally connected humans are exposed to continuous communication overload, including the sensory overload generated by digital technologies. Niklas Luhmann’s theory is well suited for understanding the effects of the small number of perspectives that are amplified by digital algorithms. It is less well suited for understanding the bottom-up development of social movements that involve billions and trillions of communication acts at human scale.
With the help of machine learning algorithms, the latter factor of cultural evolution can be analysed to some extent, but in the current legal landscape, data usage rights and access limitations effectively only makes this capability available to the dominant players in the institutional landscape. The questions of interest for these players are by definition limited to the comfortable sphere of discourse that is framed by the world view of powered-up authorities. In fact, any analytical results that may threaten dominant cultural narratives are likely to be fed into the re-configuration of social medial algorithms, in ways that dampen inconvenient perspectives and that reinforce dominant cultural narratives.
By design, thoughtful critical narratives are highly unlikely to reach the wider public within non-judgemental framings and containers. Instead, the operators of social media platforms benefit greatly from simplistic attention grabbing narratives of all colours, thereby allowing established authorities to promote their perspectives as the ‘voice of reason’, consistently in favour of perpetuating the social power structure of the capitalist institutional landscape (Fischer 2009).
Beyond the illusion of control
Regardless – or rather due to – the way in which social medial algorithms evolve and the ways in which mass media are tied to dominant cultural narratives, peer-to-peer (P2P) communication at human scale is being used by billions of people, including encrypted and anonymous forms of communication. This somewhat less publicly visible infrastructure, which is increasingly de-centralised, diverse, and distributed, is the substrate in which social movements increasingly operate.
Human scale P2P collaboration ‘Together we know everything, together we have everything’ (P2P Foundation contributors 2023) is what remains after subtracting all the communications between mass media organisations, social media celebrities, big governments, and corporations. In contrast to the pre-Internet era, such collaboration has become cosmolocal, and is catalysing intersectional solidarity and global sharing of lived experiences on the margins of societies, and across social movements.
The diversity and the many millions of cosmolocal collaborations do not neatly fit into any finite comprehensible number of categories, and thus they escape analysis within Luhmann’s framework.
In Luhmann’s theory the focus is on communication between abstract systems, each of which may include many social agents, e.g. institutions and people. In this theory semantic integration between systems occurs in the explicit communication between systems.
This is a pragmatic approach to collective sensemaking in a powered-up social world of super-human scale systems in which one-to-many communications play a substantial, if not the dominant role, in maintaining cultural inertia. Relevant metrics include opinion polls, votes, and economic transactions. Typical outputs include persuasive communication, laws, and social norms. Key tools include mass media and social media.
Luhmann assumes culture is encoded in explicit communication between systems of social agents (Strauch 1989). In this context social agents can be individuals or institutions at any level of scale.
The public digital realm is entirely socially constructed in terms of explicit communication and explicit encoding of many rules. Therefore it lends itself to analysis with the help of Luhmann’s systems theory of society.
Strengths
Analysis of socially constructed large scale systems involving millions of people.
Awareness of human cognitive limitations.
Awareness that anthropocentric control is an illusion.
Awareness that all large scale human decisions are likely to cause harm, often out of immediate sight of the decision makers.
Staying clear of moralising and recognising the dangers of moralising.
Weaknesses
Lack of acknowledgement of the role of collaborative niche construction within the evolution of all living ecosystems.
Lack of awareness of the limits of human scale, the diverse possibilities and dynamism that open up at human scale, and how corporate and state controlled large scale digital systems exclude all these possibilities, and, with the help of protocols and algorithms, cultivate public perceptions of both paradigmatic inertia and insignificant yet somehow dangerous irritants.
Lack of awareness of the innate collaborative tendencies of humans.
Naive belief that socially powered-up systems such as markets can channel self-interest into collective benefits.
Due to a focus on second order cybernetics, limited focus on the feedback loops between socially constructed super-human scale systems and biological and ecological systems, including the extent of ecological externalities, which already became apparent with the Limits to Growth, a weakness that could be rectified by considering higher order cybernetics (Yolles 2021), and with the help of the recursive formalism of higher order category theory (nLab 2024).
The Australian human scale permaculture pioneer David Holmgren (2023) would likely see similar limitations in Luhmann’s theory. The diversity and the many millions of cosmolocal collaborations today do not neatly fit into any finite comprehensible number of categories, and thus they escape analysis within Luhmann’s framework. Collaborations amongst permaculture practitioners are a good example.
Reflections with the vision of hindsight
Forty years ago we had less scientific evidence regarding all the factors that we can identify as weaknesses in Luhmann’s theory with the vision of hindsight. But already in the late 1990s, during Luhmann’s lifetime, educated people had access to plenty of indicators and warning signs, that all along indigenous people intuitively understood many of the flaws in our powered-up and hypernormative society.
Collective cognitive dissonance in WEIRD societies (Henrich 2021) has been rising, yet has been kept out of the public discourse, precisely because of the way the modern media system functions in entirely socially constructed super-human scale systems, exactly as described by Luhmann. This is how WEIRD became truly WEIRD Theatre, i.e. WEIRDT (Bettin 2023c), and how hypernormative social norms and laws dehumanised, pathologised, and criminalised growing segments of the population, to an extent that has started to visibly erode the social license of established institutions and the associated paradigmatic inertia from the bottom up.
Like Marx, Luhmann is an excellent analyst. Unlike Marx he avoids speculating about the future. To avoid gambling with the future of humanity and to avoid unleashing even greater harm on the planetary ecosystem (Michaux 2023), we can build on the strengths of Luhmann’s insights as well as on what we now recognise as weaknesses in his theory.
From what is known about Luhmann and his lifetime project of conceptualising the social world (Moeller 2021), (Schmidt 2021), (Morgner 2022), his perseverance, his idiocyncratic sense of humour, and his unique system of working, today many in the Autistic community would likely regard Luhmann as neurodivergent.
Inherent limitations of formalising social systems
The introductory lecture ‘Introduction to Luhmann & Systems Theory’ (Tohme and Gangle 2021) outlines how category theory can be used to formalise Luhmann’s theory.
Systems are human mental abstractions, they live in human minds, and via communication, especially dialogues, they incrementally find their way into other human minds with varying levels of fidelity (Lakoff and Johnson 1981). Luhmann’s theory focuses on the explicit communication between abstract systems, ignoring that these abstractions can only come into social circulation with the help of symbolic language, and that different people may have different mental models of a specific system (Milton 2012).
In the above introductory lecture, the abstract conceptual nature of systems is illustrated in the observation that ‘the system needs the environment, the environment does not need the system.’
The very definition of systems like the the legal system, the media system, the economic system, the family system, etc. will always be fuzzy, and the commonalities tend to be hard to pin down. The legal system is one of the least fuzzy systems, as only laws that are written down and have been enacted count. In contrast, the definition of a system like the media system is much less well defined and less formalised – yes, all communication acts can be identified, but which ones involve agents that are part of ‘the media system’?
Evolutionary design
Evolutionary design (Bettin 2021a) is an approach to sensemaking and adapting sociotechnological systems based on the principles of cultural evolution that can be derived from anthropological observations and from archaeological evidence about human scale societies that predate the emergence of civilisations.
In evolutionary design the notion of intentional design is entangled with the concept of evolution within an ecological context, resulting in a profound shift in underlying assumptions about the ability of human institutions to reliably produce predictable design outcomes, especially at larger scales, at which human cognitive and emotional limits come into play.
Cultural evolution entails not only the evolution of collaborative relationships and supporting tools within a group, but also the evolution of collaborative relationships between groups with many cultural commonalities, as well as between groups with few cultural commonalities.
In Evolutionary design the focus is on communication between concrete social agents, specifically on the evolution of shared understanding and knowledge co-creation, recognising that knowledge may pertain to the system or to the environment, and that the internal models that agents maintain act as the semantic integration points between systems. Many of these semantic integrations are not visible as explicit communication but show up in the form of tacit knowledge, i.e. as unobservable and often subconscious processes within each social agent.
This is an approach to collective sensemaking at human scale that aims to maximise shared understanding and long-term collaborations, which in turn depends on the ability to nurture psychological safety and maintain lifetime relationships. Relevant metrics are hard to quantify objectively and include mutual trust, wellbeing, and biodiversity. Typical outputs include tacit and explicit models of shared understanding of the world, not limited to social norms. Key tools include de-powered dialogue (Bettin 2023a), Open Space (Owen 2008), prosocial principles (Ostrom 2015), and design justice principles (Design Justice Network 2018).
The evolutionary design approach builds on experience with the bottom-up Socialisation, Externalisation, Combination, Internalisaton (SECI) model of knowledge co-creation (Nonaka et al. 2008), and on collaboration in Open Space.
The principles that underpin evolutionary design complement the social systems theory by Niklas Luhmann. Whilst the principles of evolutionary design have been distilled from thirty years of personal experiences with cultural evolution in human scale groups and between human scale groups (Bettin 2020), informed by foundational principles for the emergence of nested complex systems (S23M 2023) from a bottom-up, inside-out perspective, Niklas Luhmann starts with a top-down, outside-in perspective.
In contrast to Luhmann’s theory, the multi-level approach of evolutionary design does not assume completely functionally closed systems. Instead of the social system as a whole including a model of itself, evolutionary design recognises that each social agent within a social system is assumed to maintain an internal model of the whole social system and the environment. These internal models are always simplifications, as all agents are understood to have cognitive and sensory limits. In both approaches social agents may be part of one or more systems.
In evolutionary design, culture is experienced and co-created at a human scale that is comprehensible for humans, adapted to human cognitive and emotional limits, in the form of shared understanding, by nurturing trustworthy lifetime relationships.
In complex, socially powered-up empires and modern nation states, i.e. hierarchically structured large scale societies, which are governed by abstract institutions with formal authority to make decisions that affect millions and sometimes even billions of people, both approaches have their place and complement each other.
Mental health is a function of communal health
The modern disciplines of psychology Fechner (1860) and psychiatry Reil (1808) are a product of the European industrial era, focused on helping individuals to cope with the mental burden and cognitive dissonance that is generated by having to function – or pretending to be functioning – as a cog in the industrialised machine. The problems of alienation are as old as industrialisation. Karl Marx is famous for writing extensively about the topic (1844).
After decades of outsourcing and offshoring, many of the so-called rich nations are no longer heavily industrialised in the classical sense of producing material goods. Instead, many people are employed in the so-called service sector, and many of those who have attained higher levels of education, i.e. certified professionals, work in bullshit jobs (Graeber 2018). Those performing such jobs feel that their job is largely meaningless, and in many cases, that it actively contributes to the modern human predicament.
This is the result of an oxymoronic economic system that literally optimises for the appearance of busyness. This is not a joke, and many marginalised people are fully aware of this fact.
The specific challenge that mental health professionals face is a Diagnostic and Statistical Manual American Psychiatric Association (2013) that reflects the cultural bias of Western ‘normality’, in which sanctified bullshit (Spicer 2020) is the informational fuel that runs the so-called economy. Therapists and psychiatrists have the best intentions, and most genuinely want to help people, but whatever assistance they provide, at the latest when their patients are sent back into the economic engine to ‘perform’ in the so-called economy that is liquidating the living planet, they will again suffer from predictable mental health problems.
Surviving on the edges of modern society is an art. The arts and regular immersion in genuinely safe Open Spaces help us imagine and co-create ecologies of care in which care and mutual aid are the primary values. Healthy artistic and Autistic life paths by necessity differ from ‘normality’ (AutCollab 2024).
There is an urgent need to catalyse Autistic collaboration and to co-create healthy Autistic, artistic, and otherwise neurodivergent whānau, i.e. extended chosen families, all over the world. Marginalised people depend on assistance from others in ways that are pathologised in hypernormative WEIRD societies (Bettin 2019). However, the many ways in which atomised nuclear families and individuals depend on abstract institutions in far away places is considered ‘normal’. The endless chains of trauma must be broken.
Collective learning disability induced by social power gradients
The story of infinite economic growth and technological progress portrays a completely delusional and scientifically impossible world (Meadows 1972), (Rees 2023), which not only ignores biophysical limits, but also human cognitive and emotional limits. Nurturing the human capacity to extend trust to each other, and engaging in the big cycle of life as part of an ecology of care beyond the human is the biggest challenge of our times.
Social power can be understood as the privilege of not needing to learn, and taking the liberty of making decisions that affect large populations, in complete ignorance of our own individual human cognitive and emotional limits, which prevent us from fully comprehending the needs and unique circumstances of thousands of diverse communities and millions of people (Bettin 2021b).
Stepping back, looking across all empire building civilisations, the collective learning disability induced by powered-up social relationships can be traced to the following ways of systematically distorting and dismissing lived experiences:
Oversimplification – by reducing complex problem spaces to a much lower (one!) dimensional space. This is the commonality across all pyramidal systems of power – there is one perspective that dominates over all others (Shiva 1996).
Inducing a systemic power differential – by distorting the oversimplified one dimensional metric with the notion of ‘interest’. This is the religion of economics (Graeber 2011).
Watering down the precautionary principle – via cognitive blind spots created by the arbitrary normalising cut-off points of the bell curve in the social realm. Example: entire island nations completely get ignored until they are doomed. Their local existence is deemed ‘insignificant’ in relation to what happens in the so-called ‘real’, i.e. the big ‘normative’ world where all decisions are made. This is the scientism that is blooming in the era of big junk data.
Systematically exploiting the ambiguities of linear narratives – by nominating a convenient ‘authority’ for interpretation. For a current example, we only need to look at the way Julian Assange is treated by the British Crown. Last century the world had Soviet dissidents. This century the United States are producing American dissidents. The Anglosphere is ‘leading’ the world in legal engineering and perception management.
Systematically exploiting cognitive blind spots – created by translations between different languages, again by nominating a convenient ‘authority’ for interpretation. Aotearoa is a poster child for this approach (Network Waitangi Whangarei 2012). This goes hand in hand with implicit assumption that some languages are more ‘primitive’ than others.
A misguided focus on ‘winning’ arguments – rather than engaging in omni-directional learning to better understand each other. This is the bullying that is taught in business schools, i.e. the art of marketing, sales, and corporate power politics. The most honest conversation that I have had on this topic was with a former technology investor who describes business schools as ‘places that train people how to become a bad person’. My own attempts at educating MBA students in the neurodiversity paradigm were also disillusioning and traumatising.
None of this is new. The old Daoist scholars such as Lao Zi and Zhuangzi knew as much from lived experiences with powered-up empires over 2,500 years ago. The elements above are the cultural foundation on top of which it becomes possible to cloak highly coersive and abusive ‘normalisation’ therapies such as Applied Behaviour Analysis (ABA) as evidence based best practice (AutCollab 2021).
Adopting a human scale aware precautionary principle
On the basis of the evidence available to us today, we are well advised to fully acknowledge human limitations, including the limitations of human science and technologies conceived by humans. This entails adopting a scale-aware precautionary principle in all human endeavors:
At small (human) scales, practicing a high level of autonomous communal self-governance and applying a political conception of the precautionary principle: ‘Communal decision making in Open Space, supported by an advice process and mutual trust, should incorporate a margin of safety; activities should be limited below the level at which no adverse effect has been observed or predicted (margin of safety)’.
At large (super-human) scales, respecting the sanctity of the living planet, and applying a strict, science based conception of the precautionary principle: ‘Activities that present an uncertain potential for significant harm should be prohibited unless the proponent of the activity shows that it presents no appreciable risk of harm (prohibitory)’
Together, the two parts of the scale-aware precautionary principle imply that no community, regardless of scale, is entitled to conduct an activity that presents an uncertain potential for significant harm beyond small (human) scales.
To avoid the potential for unlimited harm, the scale-aware overarching precautionary principle tells us that social governance should never be placed in the hands of any powered-up person or institution with super-human scale decision making abilities.
A principle based and scale-aware social justice approach rather than a rule based approach to collaboration between groups is at the core of the evolutionary design approach that has been distilled from a range of sciences and transdisciplinary practices, including from the intersectionality between the neurodiversity, disability, and indigenous rights movements (Walker 2013, 2014), (Bettin 2023b). The evolutionary design approach is compatible with Luhmann’s theory in that the smallest unit of knowledge creation is a dialogue within or between systems.
Rediscovering the beauty of collaboration at human scale
We currently live in traumatising super-human scale societies.
There’s a “pervasive warlike culture” in the U.S. that leads us to approach just about any major issue as if it were “a battle or game in which winning or losing is the main concern,” she wrote. It’s a deeply entrenched cultural tendency that has shaped politics, education, law, and the media. – Kate Yoder, War of words, (2018)
Growing numbers of marginalised people are involved in de-powering and co-creating alternative human scale social systems and communities (Bettin 2023e), whilst at the same time still interacting with super-human scale powered-up institutions out of the necessity to survive (Bettin 2023d).
The evolutionary design approach infuses social construction with:
Lessons from our current understanding of biological ecosystems and organisms.
The scale aware precautionary principle that reflects the timeless patterns of human limitations, which become visible when synthesising the insights from anthropology, archaeology, and history, including the rise and inevitable fall of all powered-up civilisations.
Individual social agents (organisms) are not only participants in a system, within ecological and biological processes they are also complex systems themselves, resulting in a structure of nested systems. For example, a mammal can be understood as a collection of interacting subsystems, i.e. the circulatory system, the nervous system, the mental system (all the mental models of the environment), the digestive system, etc. Each of these subsystem consists of specific agents (organs and cells). Whilst Luhmann’s theory could be used to describe the communication between these systems in abstract terms, evolutionary design is also equipped to describe the communication between specific organs and cells, and allows us to take a holistic approach to human wellbeing at human scale that is compatible with our evolutionary history.
Innovation and cultural change can only be transformative if it substantially redefines social norms and so-called best practice (de Decker 2022), and for this we need appropriate conceptual tools (Bettin 2017), including therapies that help tackle the modern addictions to social power and convenience, to overcome cultural blind spots and expand the sphere of discourse.
Conclusion
Nearly all our current platforms and applications in the digital realm are socially powered-up by the religion of the invisible hand, in contrast to biological ecosystems and organisms. As we live through the current human predicament we are well advised to understand the religion of the invisible hand as a collective learning disability that actively contributes to human and non-human suffering.
All of the above is just a long way of explaining what many indigenous grandmothers have understood about human scale all along, without needing to resort to modern science and modern social theories (Angarova 2023):
Alkhatib A. (2021) ‘To Live in Their Utopia: Why Algorithmic Systems Create Absurd Outcomes. Why Algorithmic Systems Create Absurd Outcomes.’ CHI Conference on Human Factors in Computing Systems (CHI ’21), May 8–13, 2021, Yokohama, Japan. ACM, New York, NY, USA, 14 pages. https://doi.org/10.1145/3411764. 3445740
American Psychiatric Association (2013) Diagnostic and Statistical Manual of Mental Disorders (DSM-5-TR).
Angarova, G. (2023) ‘Understanding Suffering and Knowing Our Place.’ Holding the Fire: Episode 4. Resilience.org. October 2023.
Bettin, J. (2017) ‘Designing filtering, collaboration, thinking, and learning tools for the next 200 years.’ Cultural Evolution Society Conference, Jena, Germany. September 2017. https://s23m.com/ces2017/index.html.
Lakoff, G. and Johnson, M. (1981) Metaphors We Live By. The University of Chicago Press.
Malie, G. et al. (2023) ‘A country being lost to rising sea levels.’ Channel 4 News. December 2023. https://youtu.be/H-ar5drhjzU .
Marx, K. (1844) ‘Ökonomisch-philosophische Manuskripte aus dem Jahre 1844’ (the Paris Manuscripts).
Meadows, D. (1972) The Limits to growth; a report for the Club of Rome’s project on the predicament of mankind. A Potomac Associates book.
Metzler, H. et al. (2023) ‘Social Drivers and Algorithmic Mechanisms on Digital Media.’ Perspectives on Psychological Science OnlineFirst. July 2023. https://doi.org/10.1177/17456916231185057 .
Milton, D. (2012) ‘On the Ontological Status of Autism: The ‘Double Empathy Problem.’.’ Disability & Society 27, 6 (2012): 883–887. https://doi.org/10.1080/09687599.2012.710008.
Moeller H. G. (2021) ‘Luhmann & Cybernetic Identities.’ Undisciplined. January 2021. https://youtu.be/j5SaBSFApwc .
Network Waitangi Whangarei (2012) Ngāpuhi Speaks. He Wakaputanga o te Rangatiratanga o Nu Tireni and Te Tiriti o Waitangi, Independent Report, Ngāpuhi Nui Tonu Claim.
Niaros V. et al. (2020) ‘Cosmolocalism: Understanding the Transitional Dynamics Towards Post-Capitalism.’ tripleC Communication Capitalism & Critique Open Access Journal for a Global Sustainable Information Society. September 2020. DOI: 10.31269/triplec.v18i2.1188 .
Rees, W.E. (2023) ‘The Human Ecology of Overshoot: Why a Major ‘Population Correction’ Is Inevitable.’ World 2023, 4, 509–527. https:// doi.org/10.3390/world4030032.
Reil, J. C. (1808) Beyträge zur Beförderung einer Kurmethode auf psychischem Wege. Halle : Curt.
Rushworth, S. (2024) ‘Prayer for the Earth: An Indigenous Response to These Times.’ The Poetry of Predicament. March 2024. https://youtu.be/anVEGa43xvM .
Spicer, A. (2020) ‘Playing the Bullshit Game: How Empty and Misleading Communication Takes Over Organizations.’ Organization Theory, Volume 1: 1–26. https://doi.org/10.1177/2631787720929704 .
The preoccupation with growth and technology accelerated following WWII, fuelling the illusion of infinite growth on a finite planet. The rise and fall in the belief in technological progress can be illustrated with data from Google Books Ngram Viewer.
I have been observing these trends since the mid 1980s, when anthropocentric confidence in technology and growth seems to have peaked, and when neoliberalism was “installed” around the world as the future engine of wealth and prosperity. Under the hood, the neoliberal engine was powered by the availability of computers and software, and by the economic logic of Moore’s Law. Looking back over the last 30 years, the entanglement of the evolution of digital technologies and neoliberal economics can be summarised as follows:
Software product design conducted in isolation, without giving customers and marginalised groups the ability to shape the design, is a form of social engineering, whether intentional or not. All users of the Internet are familiar with the social externalities.
Our laws and social norms have been shaped by the metaphor of society as a factory and on the metaphor of people as machines. These metaphors have not only warped our relationship with the natural world and our conception of humanity. They have led to techno-cults in which technology corporations have taken on the role of sacred places of worship, and CEOs are the high priests, praising the divine qualities of artificially intelligent technologies. In the emerging technoverse, biological life is perceived as becoming irrelevant.
When society is a factory, the only things that count in are things that can be measured. It is no coincidence that scientific management (Taylorism) was conceived in the wake of the invention of the steam engine and machine assisted manufacturing, to complement the the laws of physics that governed the mechanics and the productivity of the machines on the factory floor.
The discipline of economics allowed the scientific approach to managing humans to be extended to the scale of nation states – another conceptual building block for organising human activities in industrialised societies. There are a number of parallels between the impact of the development of economic theories on human society and the social impact of the development of the Internet. Neither the Internet nor economics draw directly on an evidence based understanding of physics, biology, and human behaviour. Both the Internet and economic theories are best understood as prescriptive rather than as observational tools – as language systems that are based on specific European/North American cultural conventions that are assumed as “sensible” (common sense) or “obvious” (self-evident). With these language systems in place you can measure data flows and economic performance, but only in terms of the scope and the preconceived categories afforded by the formal protocols and languages.
The introduction of a formal economic language system and the introduction of formal protocols for digital communication have shaped human culture around the social ideologies espoused by early industrialists and early information technology entrepreneurs. Over course of the last two centuries governments have become increasingly dependent on economists and information technology entrepreneurs in order to understand and engage with society, and also to understand what what technological options are on the horizon. In this process anything that lies beyond the scope of what is deemed relevant or acceptable is discounted as non-essential or unproductive. In multiple bottom line approaches the conveniently simplistic thinking becomes evident when metrics from the natural world are translated into monetary metrics – as if a monetary number can adequately represent the loss of biodiversity and the destruction of entire ecosystems in the name of economic “progress”.
A couple of months ago Douglas Rushkoff publicly connected similar concerns from his perspective. He starts off with his usual story of the NZ bunkers of the tech billionaires, and then does a great job of painting the bigger picture in accessible terms, concluding with an appeal to reconnect technology and abstract metrics to the beautiful diversity of the living world and to the limits of human scale.
I would add that the cult of busyness has not only infected billionaires, but has been force fed to a broader class of professionals who find themselves trapped as employees and investors in super human scale corporate and government bureaucracies. Some of these people have become as addicted to the drug of social power as the billionaires. Their decisions, some of which affect many millions of people, need to be understood as decisions made by power drunk addicts.
Nate Hagens recently facilitated an an excellent panel discussion on natural resource accounting, exposing the extent of wishful thinking and denial of material constraints in the cult of busyness. The barrier to the urgently needed transition to degrowth is ideological inertia, an artefact of WEIRD psychology. The sooner the life destroying cancer of economic growth collapses under its own weight, the less the overall level of suffering. Locally, my friend Deirdre Kent illustrates the effects of the invisible hand in the context of “emissions trading”, and points to the conceptual tools and metrics needed for coordinating economic activity on a path of degrowth.
The longer the established power structures prevail, the greater the overall amount of suffering. From here on onwards, it’s materially downhill across all potential scenarios. The open question is how far down we’ll take the entire planet. The current monocultural and energy intensive way of life has no future. The kinds of technology that humans will be able to maintain and operate sustainably over the next 100 or 200 years, will be much simpler and less energy intensive – much more economising. Manual human labour and in-depth understanding of local ecosystems will be back in demand, and will be appreciated. We can start with that today.
Whilst all paths into the future involve a radical decrease in material consumption, how the transition will be experienced is very much a question of cultural evolution and adjustments in expectations. No matter how various local cultures evolve, the unavoidable suffering will be greater the longer the inertia of established institutions prevails, as it only deepens the level of destruction of the biosphere and the remaining human habitat. Pedal to the metal, running on the neoliberal engine for another decade, as far as that is even possible, will lead to delayed but ultimately greater suffering.
Joseph Tainter’s timeless conclusion (1988) about collapse from his analysis of collapsed civilisations applies and provides useful guidance:
The notion that collapse is uniformly a catastrophe is contradicted, moreover, by the present theory. To the extent that collapse is due to declining marginal returns on investment in complexity, it is an economizing process. It occurs when it becomes necessary to restore the marginal return on organizational investment to a more favorable level. To a population that is receiving little return on the cost of supporting complexity, the loss of that complexity brings economic, and perhaps administrative, gains.What may be a catastrophe to administrators (and later observers) need not be to the bulk of the population (as discussed, for example, by Pfeiffer [1977: 469-71]). It may only be among those members of a society who have neither the opportunity nor the ability to produce primary food resources that the collapse of administrative hierarchies is a clear disaster. Among those less specialized, severing the ties that link local groups to a regional entity is often attractive. Collapse then is not intrinsically a catastrophe. It is a rational, economizing process that may well benefit much of the population.
Meanwhile, there is no shortage of examples of good human scale initiatives on the margins. Our friends from Local Futures have just run an online knowledge sharing workshop with participants from a range of countries: part 1, part 2. As the old system is dying, new systems are being birthed as part of the big cycle of life.
We can learn a lot from the Congolese forest people. Humour is the ultimate weapon. It is time to have a good laugh, and to show power addicted capitalists the immediate exit – without any further returns. At the same time, we can offer education that guides those who feel trapped towards safe exit paths into emergent alternative human scale realities.
Onwards!
Further reading
Meadows, D. et al. 1972. The Limits to Growth. Club of Rome.
Schumacher, E. F. 1973. Small Is Beautiful: Economics as if People Mattered. Harper Perennial.
Tainter, J. A. 1988. Collapse of Complex Societies. Cambridge University Press.
Babiak, P. and Hare, R. 2006. Snakes in suits: When Psychopaths go to Work. Harper Business.
Graeber, D. 2006. “Beyond Power/Knowledge: an exploration of the relation of power, ignorance and stupidity.” London School of Economics. May 2006. http://libcom.org/files/20060525-Graeber.pdf.
Owen, H. 2008. Open Space Technology: A User’s Guide. Berrett-Koehler Publishers.
Tomasello, M. 2009. Why We Cooperate. Boston Review Books.
Weinberger, D. 2012. Too Big To Know: Rethinking Knowledge now that the Facts aren’t the Facts, Experts are Everywhere, and the Smartest Person in the Room is the Room. Basic Books.
Dell, K. et al. 2018. “Economy of Mana.” MAI Journal 7, 1 (2018). University of Auckland Business School. DOI: 10.20507/MAIJournal.2018.7.1.5.
Levine, B. E. 2018. Resisting Illegitimate Authority: A Thinking Person’s Guide to Being an Anti-Authoritarian – Strategies, Tools, and Models. AK Press.
Aldred, J. 2019. Licence to be Bad: How Economics Corrupted Us. Allen Lane.
Bauwens, M. et al. 2019. Peer to Peer : The Commons Manifesto. University of Westminster Press.
Eisler, R. et al. 2019. Nurturing Our Humanity : How Domination and Partnership Shape Our Brains, Lives, and Future. Oxford University Press.
Hickel, J. 2020. Less is More: How Degrowth Will Save the World. William Heinemann.
Saijo, T. et al. 2020. Future Design: Incorporating Preferences of Future Generations for Sustainability. Springer.
Bettin, J. 2021. The Beauty of Collaboration at Human Scale: Timeless Patterns of Human Limitations. S23M.
Townsend, C., Ferraro, J. V., Habecker, H., Flinn, M. V. 2023. ‘Human cooperation and evolutionary transitions in individuality’. Philosophical Transactions of the Royal Society B: Biological Sciences 378(1872). doi.org/10.1098/rstb.2021.0414
10,000 years ago, homo sapiens began farming a grain surplus. This surplus led to the creation of societal and cultural hierarchies which divorced our species from our long relationship with the natural world.
The biggest lie in our culture is the normal language of WEIRD success, finance, legalese, economics and technology.
The current human predicament is a result of the cultural disease of super-human scale powered-up civilisation building endeavours, the origins of which can be traced back to the beginnings of “modern” human history and the social power dynamics resulting from the invention of interest bearing debt around 5,000 years ago.
Maybe now is the time to write a new book: “Debt – The Last 20 Years”. Towards a more honest language to navigate the path ahead:
The following presentation to investors contains some interesting numbers, and along the way, it reveals the short-term thinking of those who are caught up in the cult of busyness.
Skagen is a Norwegian investment fund.
On the one hand, for the general public, given growing concerns about the climate and the environment, politicians and clean tech companies enjoy pointing to Norway as green and clean, as a poster child for the energy transition.
On the other hand, for investors, Norwegian fund management companies advertise the bullet proof investment opportunities in the energy sector – across the board, for further oil and gas exploration, and for mining.
I have not independently verified the numbers, but irrespective of the accuracy of the absolute numbers, even if some numbers are off by a factor of two or more, there is one true message:
The so-called energy transition is a feel-good exercise for the general public, and at the same time, it is [marketed as] a rock solid investment opportunity to investors. Norway is one of the biggest oil and gas exporters as well as a poster child for the dream of “clean” energy, propping up the other great investment opportunity, related to mining, globally – and therefore also again for the Norwegian oil and gas that is needed to meet the energy demand resulting from the anticipated extreme increase in mining activities. A win-win-win scenario, with a double win for Norwegian oil and gas.
The presenter correctly points out that mining won’t be able to scale 50-fold and more, to meet the theoretical demand of an “energy transition”, but given the current cultural inertia, this does not diminish the investment opportunities.
The cultural inertia and the optimism of investors is based on the following assumptions, none of which are mentioned anywhere in this presentation:
Societies will continue to rely on GDP as a measure of progress
The amount of greenhouse gases in the atmosphere is going to rise indefinitely, because oil and gas will be consumed indefinitely,without any disruption to the growth in GDP (so-called “wealth”)
Industrialised countries (the WEIRD ones and China) will continue to rely heavily on the convenience of fossil energypoweredtechnology hyper busy ways of life (the equivalent of several hundred energy slaves per person)
The state of the biosphere and the planetary ecosystem is an irrelevant externality on the road of GDP growth and technological “progress”
Investors are obviously having a good time traveling on the “pedal to the metal” bus: No matter what lies ahead, capitalism is the best religion that has ever been invented.
You don’t need to be a genius to see that over the next 10 to 20 years at least two of the above assumptions will blow up in our face, and of course also in the face of investors. It does not matter which assumptions blow up first, the downstream effects will be massive, putting an end to energy intensive, i.e. to industrialised ways of life. Globally fungible money issued as interest bearing debt won’t survive.
In fact, the sooner the bizarre techno optimistic assumptions start to blow up, the more of the planetary ecosystem will still be around, to assist humans in the forced transition to [very] low energy ways of life and in rediscovering that we are part of nature.
Attempting to apply the scientific method in complex domains and transdisciplinary contexts
Visualising conceptual causal models as an antidote to sloppy reasoning and invalid statistics
Modularising complex domains
Modularisation of complex domains and creative collaboration across a diversity of domain boundaries maximises collective intelligence at human scale.
A practical example
The limits of understandability of linear languages
Unfortunately, so far most software has been written in linear languages, resulting in systems that are nearly as opaque, incomprehensible, and subject to surprising and unknown modes of failure as are state-of-the-art artificially intelligent systems. Over the last 50 years, in the busyness of frantic attempts to digitise and automate the tools of civilisation, we have un-learned the art of de-powered dialogue and the art of modularisation – the signature traits of the human species.
Once we rediscover and appreciate the limits of human scale, we are equipped to replace the busyness of muddling with human dialogue and human comprehensible explanatory models.
Agent based semantic modelling and validation via instantiation is an urgently needed form of grassroots theory building and theory integration (knowledge archaeology) beyond academia. Wherever there is deep human domain knowledge, wherever people still trust each other and are not corrupted by social power dynamics, many experiments in the social sciences and in engineering can be improved and sometimes entirely replaced by semantic / causal modelling and instantiation.
The semantic approach can be understood as a rapid iterative cycle of theory building and experimentation that surfaces and validates structural and causal mental models. It involves validating a theory, i.e. a formal semantic model, against the collective mental models of all available domain experts, resulting in explicit representations of the domain specific nonlinear multivariate mental models that participants use on a daily basis, usually without even being conscious of it. As an added bonus, instantiation catalyses shared understanding amongst all participants.
Side note: The Cell Platform is designed to track the number of times categories are instantiated in the context of a particular model artefact, including the reasons for non-instantiation, i.e. unknown information or category is not-applicable in the context at hand. That’s exactly the meta data that turns a semantic model and a corresponding set of instances into a human scale, i.e. an understandable Bayesian model.
A big part of the journey of de-powering human societies involves taking an honest look at the relevance and quality of the digital data that we have been busy collecting – treating it as “the new oil”.
Linear language – the ultimate learning disability
How did we get caught up in a cult of busyness? Humans are curious creatures, we are easily distracted by shiny new toys. At human scale, in a de-powered social environment, our curiosity is a wonderful adaptive trait that generates cultural diversity. Beyond human scale, especially in powered-up environment, our curiosity degenerates into a maladaptive trait with the potential of causing untold harm.
Humans acquire knowledge or become aware of new information as individuals, and as part of groups of different sizes: households, teams, organisations, communities, societies, and with the help of ubiquitous global communication tools, even collectively as humanity. Creative collaboration in Open Space can help us break through the barriers of established disciplines and management structures, and power a continuous SECI (socialisation, externalisation, combination, internalisation) knowledge creation spiral at human scale.
The tomb stone of powered-up civilisations : Consistently Too Little Too Late
Here is an excellent summary of the human predicament that may come in handy to shorten fruitless conversations with techno optimists and members of other anthropocentric faiths. I only have very few quibbles with the terminology used by Michael Dowd, and I love that he refers to industrialised civilisation as a religious cult, which I fully agree with.
One quibble refers to the use of the word “reality”, as it detracts from the vast diversity of lived human and non-human experiences. Instead I simply refer to the diversity of lived experiences and the commonalities and differences between lived experiences. One of the commonalities of lived experiences amongst sensitive Autistic people is that they tend to reach the doom and post-doom stages of understanding the hubris of anthropocentrism [much] earlier than others, many of whom remain their entire life in a state of cognitive dissonance and denial. Ted Nelson beautifully captured the toxicity of the modern technological human arrow of “progress” back in 1999, which is perhaps my favourite quote from the entire industrial era:
A frying-pan is technology. All human artifacts are technology. But beware of anybody who uses this term. Like “maturity” and “reality” and “progress”, the word “technology” has an agenda for your behavior: usually what is being referred to as “technology” is something that somebody wants you to submit to. “Technology” often implicitly refers to something you are expected to turn over to “the guys who understand it.”
This is actually almost always a political move. Somebody wants you to give certain things to them to design and decide. Perhaps you should, but perhaps not.
This applies especially to “media”. I have always considered designing the media of tomorrow to be an art form (though an art form especially troubled by the politics of standardization). Someone like Prof. Negroponte of MIT, with whom I have long had a good-natured feud, wants to position the design of digital media as “technology. That would make it implicitly beyond the comprehension of citizens or ordinary corporation presidents, therefore to be left to the “technologists”– like you-know-who.
The other quibble I have with the terminology of Michael Dowd is his complete rejection of the word hope, as if the only hope we can have is related to the longevity of industrial civilisation. In the stage that Michael refers to as post-doom, he acknowledges hope for collective action in-the-small in terms of a focus on minimising suffering, being compassionate, de-powering relationships, practicing mutual aid, etc. without using the word hope. He even acknowledges the benefits of gallows humour in terms of catalysing mutual trust and social cohesion, but frames it all under the broad umbrella of “acceptance”, which in my mind only makes sense when qualified to acceptance of civilisational collapse, which is liberating us from a diseased life denying culture.
Without trust in our ability to appreciate local life at [small] human scale and the hope that we can minimise suffering, we fail to be part of life.
The planetary reboot sequence
Mosses seem to be a part of the planetary reboot sequence that gets initiated after evolutionary hiccups like the one triggered by industrial civilisation. The next 200 years will reveal whether humans can be part of the reboot sequence. This documentary contains some superb footage and good commentary – if you ignore the last segment about exporting life to Mars.
The open question is how humans will treat each other and our non-human contemporaries on the journey towards being composted and recycled. Experiences may vary depending on the human scale cultures we co-create on the margins.
We live in a time of exponential changes in communication technology. Just a few decades ago humans only needed to learn one or two languages and perhaps the jargon of a particular profession to be equipped for a successful life. Today thousands of new apps (little languages) become available every month, far more than anyone can ever learn to use, appreciate, and trust. More and more people are realising that quantity does not equal quality when it comes to digital technologies.
The disciplines of design and engineering play increasingly important roles in a world where communication between people and all forms of economic activity are by default being mediated via digital technologies.
To understand the full implications of the new technologies that we are churning out every month, is it enough for designers to be familiar with the latest in pop-psychology and for engineers to be familiar with the latest economic fads and monetisation models? What if some important considerations about human limitations and delusions have fallen between the cracks?
Being able to design, build, and use technology does not equate to understanding all the implications.
Maladaptive evolution of corporations
Do technologies make us smarter?
Successful software products that are used by many thousands or millions of customers are best thought of as a domain specific language system that complements human cognitive abilities and that facilitates and mediates collaboration and/or social competition between humans. In a networked world with ubiquitous Internet connectivity and pervasive use of Internet enabled personal devices, software plays a significant role in guiding – or even forcing – human cultural evolution.
Software product design conducted in isolation, without giving customers and marginalised groups the ability to shape the design, is a form of social engineering, whether intentional or not. All users of the Internet are familiar with the social externalities.
The huge opportunities and dangers of mediating human communication and collaboration and/or social competition via software platforms can not be overstated. The language systems that we create with the help of software can either amplify the unique human capacity for compassion and creative collaboration or they can amplify social competition and the brutal power politics that characterise primate dominance hierarchies.
For a number of years Jaron Lanier has been warning that the Internet as it currently evolves might destroy our world [1]. Online social media platforms dictate the possible communication and collaboration patterns, and in doing so typically maximise the “return on investment” for the owners of the platform, in the metrics of success prescribed by the neoliberal cult of busyness. In developed countries, their arrival has corresponded to bizarre political dysfunction, while in the developing world, ethnic rivalries that had been waning have been re-ignited in the most grotesque fashion.
Our laws and social norms have been shaped by the metaphor of society as a factory and on the metaphor of people as machines. These metaphors have not only warped our relationship with the natural world and our conception of humanity. They have led to techno-cults in which technology corporations have taken on the role of sacred places of worship, and CEOs are the high priests, praising the divine qualities of artificially intelligent technologies [2]. In the emerging technoverse, biological life is perceived as becoming irrelevant.
Maladaptive evolution of governments
Can better regulation help?
Some of the most faithful disciples of the techno-cults are found within our government institutions and amongst our politicians. How come?
When society is a factory, the only things that count in are things that can be measured. It is no coincidence that scientific management (Taylorism) was conceived in the wake of the invention of the steam engine and machine assisted manufacturing, to complement the the laws of physics that governed the mechanics and the productivity of the machines on the factory floor.
The discipline of economics allowed the scientific approach to managing humans to be extended to the scale of nation states – another conceptual building block for organising human activities in industrialised societies. There are a number of parallels between the impact of the development of economic theories on human society and the social impact of the development of the Internet. Neither the Internet nor economics draw directly on an evidence based understanding of physics, biology, and human behaviour. Both the Internet and economic theories are best understood as prescriptive rather than as observational tools – as language systems that are based on specific European/North American cultural conventions that are assumed as “sensible” (common sense) or “obvious” (self-evident). With these language systems in place you can measure data flows and economic performance, but only in terms of the scope and the preconceived categories afforded by the formal protocols and languages.
The introduction of a formal economic language system and the introduction of formal protocols for digital communication have shaped human culture around the social ideologies espoused by early industrialists and early information technology entrepreneurs. Over course of the last two centuries governments have become increasingly dependent on economists and information technology entrepreneurs in order to understand and engage with society [3], and also to understand what what technological options are on the horizon. In this process anything that lies beyond the scope of what is deemed relevant or acceptable is discounted as non-essential or unproductive. In multiple bottom line approaches the conveniently simplistic thinking becomes evident when metrics from the natural world are translated into monetary metrics – as if a monetary number can adequately represent the loss of biodiversity and the destruction of entire ecosystems in the name of economic “progress”.
In industrialised societies governments increasingly find themselves in the role of pretending to be “in control”. Technology corporations and management consultants gladly assist governments in the pretend game of “managing the economy”. Since the Cold War empires have increasingly shifted their focus from overt conventional war to economic warfare and psychological warfare.
Corporations and governments have shared interest in managing public perceptions [4] and in supporting each other [5]. Furthermore, the judiciary often lacks transparency. In Aotearoa New Zealand for example, you can complain if you’re unhappy with a judge’s behaviour, but the complaints system is secretive, ineffective and broken [6]. Since the Judicial Conduct Commissioner’s inception in 2005, 3201 complaints have been made, and 95 percent were either dismissed because they were not about a judge’s conduct, or no further action was taken because the commissioner concluded the conduct was not concerning. Just two complaints prompted the commissioner to recommend a panel, but neither panel ever went ahead.
Maladaptive evolution of our participation in the natural world
Can civilisation be saved?
All of the above would be funny if the consequences of the industrialised “way of life” for the living planet would be less profound.
Industrial development has only been possible by exploiting the energy stored in fossil fuels and due to extreme transformation of our environment, leading to severe environmental consequences that humanity is experiencing around the globe: shifting and unpredictable climate, extreme weather events, and biodiversity collapse [7]. Humanity is paying the consequences for so-called technical and technological “progress”. Fossil fuels allow every human alive today to consume as much energy (directly and indirectly via the goods we consume) as if we all had 200 human slaves working for us. In rich industrialised countries the number of “energy slaves” per capita is even greater, between 600 and 1,000.
The extreme levels of energy consumption of the industrialised way of life are largely hidden in our daily lives. Most of the energy is consumed by industrialised production processes, by industrialised agriculture, and by the global supply chains that deliver goods from all over the planet to our door step. We activate this chain of energy consumption via 1-Click® from our mobile phones and web browsers.
Minerals are mined at scale in places far from our major population centres. Industrialised production has been off-shored to China and “less developed” countries with cheap labour, but over the last decade climate related extreme weather events and disasters have started to remind us of the many externalities that are not accounted for in our economic models.
It is more important than ever to understand that no techno-cult will ever be capable of replacing our 1.6 trillion fossil fuel energy slaves with 1.6 trillion “renewable” energy slaves. Within the short span of 200 years we have released most of the carbon from several hundred million years worth of biological growth, irreversibly changing the atmosphere and the oceans for many thousand years to come.
There is no silver bullet. The envisaged goal of industrial scale transition away from fossil fuels into non-fossil fuel systems is a much larger task than current thinking allows for. To achieve this objective, among other things, an unprecedented demand for minerals would be required [8]. Most minerals required for the renewable energy transition have not been mined in bulk quantities before. Beyond the inevitable ecological damage, the amount of energy required to mine these minerals may well turn out to be prohibitive [9] once we run out of fossil fuels or commit to leaving fossil fuels in the ground.
So-called “green” technologies such as biofuel have a negative energy return on investment and are simply part of the feel-good green campaigns of some of our governments. The familiar fossil fuel companies are increasingly re-branding themselves as energy transition companies, but of course driven by the profit motive. The last thing any of these corporations wants to see is a significant drop and a consistent downward trend in overall global energy consumption. Green industrialised growth is an oxymoron. The only growth that can ever be green is biological growth of plants.
Beyond raw energy consumption the industrialised human resource footprint on the planet has accelerated the rate of extinctions to more than 1,000 times of the historical background rate [10]. Amphibians have estimated extinction rates up to 45,000 times their natural speed. Most of these extinctions are unrecorded, so we do not even know what species we are losing.
We have replaced biodiversity with vast monocultures of industrialised agriculture and horticulture that can only be maintained with significant inputs of fertiliser, which in turn is produced via fossil fuel intensive industrialised processes. Croplands and grazing lands cover more than one third of the Earth´s land surface [11]. Furthermore, intensified land-management systems often result in high levels of land degradation, including soil erosion, fertility loss, excessive ground and surface water extraction, salinization, and eutrophication of aquatic systems.
Maladaptive evolution of our participation in society
Should civilisation be saved?
The level of disillusion with busyness as usual is growing, and not only in rich industrialised countries. 80% of employees are disengaged at work. Many people feel stuck in bullshit jobs. It is getting harder for the techno-cults to get employees excited about “disrupting the market” with “the next big thing”.
The climate crisis provided a welcome busyness opportunity for corporations to present themselves wrapped in clean and green feel-good credentials. Bright Green Lies [12] is a timely book to remind people that a green energy “transition” is not going to prevent biodiversity collapse and is not even going to prevent catastrophic levels of temperature increases and ocean acidification due to the massive amounts of carbon that we have already released.
The collective intelligence of industrialised civilisation can be summed up in five words:
Consistently too little too late
The sooner we unplug from the collective delusion, the fewer people will die or suffer needlessly. A radical reduction in energy and resource consumption can play out over the next two generations, and it can be the most civilised project of mutual aid humans have ever undertaken. Along the way we can learn a lot from indigenous societies.
You may wonder which aspects of Western industrialised knowledge may be worthwhile to retain (and for how long), given that cultural evolution is a dynamic process that unfolds over multiple generations. A few sets of knowledge are good candidates for preserving and cultivating in a global knowledge commons. However, any tools and sets of knowledge that are incompatible with a path of radical energy decent are legacy technologies that are only relevant from a historic perspective – to warn future generations about technological approaches that have lead to existential risks.
Trauma
The power of language
Language systems have been used throughout human cultural evolution to transmit cultural knowledge and understanding. They not only record lived experience, they also shape lived experience. In the absence of written language language systems evolve through daily use, and everyone in a local community contributes to language evolution. Those with particular areas of expertise and skills pass on their knowledge and new levels of understanding to peers and curious children by inventing appropriate symbolic representations and metaphors that are accessible to others.
Language systems are the most powerful cultural tools at our disposal. When the power of language and access to communication is equally distributed throughout society, language evolves in tandem with local needs and reflects the human understanding of the web of relationships within the local ecosystem.
Written language developed and symbolic notations for tracking who owes what to whom emerged when humans invented agriculture and when access to land became increasingly important. Written language allowed social power relationships to be codified and conveyed across space and time. This was the first significant step that allowed some people – those with access to written language, i.e. those who made the rules – to wield power over other people. Written language was the tool that very quickly gave rise to organised religions and to religious texts, some of which are still used to this day.
The language systems of economics and the protocols of the Internet are the main linguistic inventions of the industrialised era and the digital era. Over the last two decades digital data has frequently been described as the new oil. The intent was very obvious – systematic exploration and economic exploitation. In whatever domain data reservoirs were not yet available, social media and systematic gamification of social interactions offered the prospect of creating new valuable data reservoirs on-demand.
From one angle the critique of Jaron Lanier is only skin deep, not questioning the underlying project of civilisation and anthropocentrism. From another angle he drills right into the very foundations of our social operating system. If we can learn anything from the last 200 years, it is that the power of language needs to be distributed equally. The force of life is distributed and decentralised, and it might be a good idea to organise and collaborate accordingly, respecting the limits of human scale.
Those who examine human collective behaviour in terms of energy consumption and ecological impact in terms of biodiversity loss are broadening the sphere of discourse. We can no longer understand and make sense of the dynamics in our rapidly changing environment by attempting to shift the Overton window of industrialised civilisation. The notion of a tiny window is yet another convenient linguistic metaphor that allows corporations to translate incremental shifts in public perception into further profits and consolidated power within the carcass of a dying planet.
The planetary ecosystem is dying a death of a thousand cuts. Humans are simply one of the many externalities on the entrepreneurial exit path that involves liquidation of all biological life.
Collective trauma in 2021
The discipline of psychology is just as much a product of the ideology of industrialised civilisation as the discipline of economics – they are two sides of the same coin. In particular the pseudoscience of behaviourism is still with us today, and is used to justify and perpetuate untold harm.
In a desperate attempt to squash the sphere of discourse, and in the face of unprecedented climate disasters, the neurological makeup of 1 out of 6 people is pathologised, targeting especially those who refuse to participate in the pretend game of “normality”. The trauma caused by industrialised civilisation is ignored, and entire populations are encouraged to believe that getting back to busyness as usual should be our top priority.
What’s happening right now around the world fits both definitions of the word “trauma”: Climate change is a deeply distressing and disturbing experience. It’s also a physical injury. An injury, after more than 30 years of ignored warnings and broken promises, that can now be considered intentional.
Climate change isn’t something that’s just happening to us. It’s being done to us.
Climate change isn’t a natural occurrence that we need to be ‘resilient’ to. It’s a trauma that’s being inflicted on us against our will. It’s exhausting.
…
The consensus is clear: The vast majority of the world’s population now views climate change as an “emergency”, according to nearly two-thirds of the 1.2 million respondents in 50 countries in the largest poll ever taken on climate change, earlier this year. A recent survey of young people found 56% of respondents think that humanity is ‘doomed’. Children around the world are experiencing climate anxiety — something that no generation of humans before us have ever had to deal with.
Yet world leaders are acting at anything but an emergency pace. In fact, rather than “building back better”, 2021 has seen skyrocketing emissions growth around the world as factories, travel, and farms switch back into business as usual mode even as the Covid pandemic continues to rage on. At this growth rate, 2022 will have the highest emissions of any year in human history — a horrifically shocking fact that should provoke outrage on every street of every city in the world.
From a European or American perspective the stereotype of the Japanese salaryman [1] is easily recognised as a product of a social norms that are no longer compatible with universal biological and mental human needs. Perceived normality is a social construct, but from within a given culture it is often impossible to draw a clear line between universal biological and mental human needs and culture specific norms and practices.
Only outsiders and members of marginalised groups are well equipped to identify and articulate unspoken social norms. An understanding of universal biological and mental human needs can only be developed from a transdisciplinary and intersectional perspective, based on a commonality and variability analysis across many cultures and across the entire history of human evolution.
In terms of energy and resource consumption, the social customs in Europe and North America are even further removed from ecological sustainability than the culture in Japan. This insight is nothing new.
Growth economics were clearly identified as unsustainable in the Limits to Growth report [2] in 1973, and the latest data shows we are blissfully tracking along the busyness as usual scenario. Similarly the limitations our social institutions and the limits of digital technologies [3] were well understood in the 1970s. These two examples illustrate the reality and the power of paradigmatic inertia. Humans are the uncontested local champions of cognitive dissonance [4] on this planet.
Paradigmatic inertia is never beneficial. It constitutes an institutional collective learning disability, and it can only broken be broken by events that are beyond the control of the institutions within the system.
At this particular point in time, paradigmatic inertia still fuels our governments and corporations, driving them to strive for towards a seemingly reassuring state of “normality”. From within the established institutional framework it is impossible to understand or predict when the paradigm of normality has been shattered beyond repair.
The paradigmatic inertia that paralyses our industrialised monoculture plays out in terms of Zombie-like levels of cognitive dissonance – what some people during the Soviet era referred to as hypernormality.
In his 2016 documentary “HyperNormalisation” [6] Adam Curtis shows how the concept maps to our era, where critical thinking and individual agency is increasingly replaced by magical thinking, including absurd beliefs in the powers of artificially intelligent systems [7].
Hypernormality can also be understood through the lens of institutionalised and sanctified bullshit. André Spicer’s detailed sociological analysis of bullshit (2020) explains how organisations get completely lost in competitive social games. The key ingredients of the analysis:
The origins of bullshit
During World War I ‘bullshit’ entered informal British, North American and Australasian English speech. The lexicographer Eric Partridge claimed that during World War I, British commanding officers emphasized ‘bull’. This meant paying significant attention to soldiers’ appearances by ensuring they were perfectly dressed and their shoes were shined, even when this focus on appearance hindered the daily tasks of waging war.
Australian and New Zealand troops mocked British officers by calling it ‘bullshit’. Partridge suggests the term became common in military life during World War II. Throughout this period, it was used to refer to excessive regimentalism and attention to appearances. For instance, if soldiers prepared their quarters for inspection by a commanding officer, they engaged in ‘bullshit’. Partridge gives the following example: ‘We’ve got to get this place bullshitted up—the Commanding Officer is coming around tomorrow morning.’ The troops used the term ‘bullshat’ to refer to something which has been polished up for display purposes. For instance, ‘Don’t touch that, it’s just been bullshat!’ ‘Bullshit’ was also closely connected with high-level administration.
For instance, during World War II, New Zealand airmen referred to the air-force headquarters as the ‘bullshit castle’. The term bullshit entered into print during World War II. The first instance of the word recorded by the Oxford English Dictionary is in a dictionary of North American slang published in 1942.
Defining bullshit – and differentiating it from lying
While lying is an attempt to conceal the truth, bullshit is to talk without reference to the truth. ‘It is just this lack of connection to a concern with truth – this indifference to how things really are – that I regard as the essence of bullshit’. Underpinning this is a ‘motive guiding and controlling’ the bullshitter meaning they are ‘unconcerned with how the things about which he speaks truly are’. Recent psychological research considers the targets of bullshit by examining how some people with an ‘uncritical open mind’ are particularly receptive to bullshit. More sociologically oriented research has pointed out that in some social settings ‘bullshit’ is expected, enthusiastically embraced or silently tolerated.
Bullshit is a form of linguistic interaction. It involves characteristic patterns of communication such as evasiveness or not being held to account for one’s claims. Bringing these three aspects together, I define bullshit as empty and misleading communication. A more substantive definition of bullshit is that it consists of evasive and/or persuasive communication involving an indifference to the truth or attempts to pursue the truth which are driven by epistemically maligned intentions.
The bullshitter falls short of lying because they make use of insincere and misleading statements rather than outright falsehoods. Recent psychological work has found that established measures of everyday lying are sufficiently distinct from bullshitting.
The purpose of bullshit
The most intuitive explanation for why bullshit exists is the individual bullshitter. Many philosophical accounts assume that particular individuals have questionable motives or moral flaws which predispose them to bullshitting. For instance, Frankfurt points towards questionable motives of bullshitters such as intention to mislead their audience for personal gain. Others point out that bullshitters are driven by Machiavellian motives like deceiving their audience to gain power and resources. More recently, Cassam has argued that bullshitters are plagued by ‘epistemological vices’ such as carelessness, negligence, dogmatism and prejudice. Perhaps the most important of these is ‘epistemic insouciance’. This entails ‘a casual lack of concern about the facts or an indifference to whether their political statements have any basis in reality’. Some have argued that bullshitters suffer from cognitive failures. Finally, a recent study of school children found that bullshitters shared demographic characteristics; they were more likely to be males from better-off socioeconomic background.
Mats Alvesson argued that wider socio-cultural concerns with ‘imagology’ (looks and appearance) has encouraged organizations and individuals to generate clichés and bullshit. In my own book on the topic, I explored how the changing nature of bureaucracy created ideal conditions for bullshit. The rise of ‘neocracies’ which are obsessed with constant change and novelty has led organizations as well as people working within them to produce a large stream of bullshit.
Bullshitting as a culture
Bullshitting is not about hiding a secret from specific people at specific points in time, it is about pursuit of a hidden agenda, often associated with long-term goals. In this context a smooth blend of half-truths, falsehoods, and common sense (culturally endorsed myths) is much more potent than a set of lies.
One of the rare examples of an analysis of bullshitting as a social practice is Joshua Wakeham’s (2017) theoretical account. Drawing on studies of social epistemology, he argues that we gain most of our knowledge second hand. This means that we do not do epistemic due diligence ourselves. We are usually not cognitively equipped to do such due diligence, and even when we are, it is exhausting for us and alienating for others.
Furthermore, in most social settings there is not one obvious correct answer waiting to be found. So instead of relying on common standards of epistemology, we rely upon social cues to sort out which knowledge claims are true and which are false. These include the characteristics of the person speaking, the background knowledge that people draw on, and the interactional dynamics between parties. Often our reliance upon social cues means we systematically relax our epistemic norms to deal with ‘the social pragmatic need to get along’. This makes us ‘accustomed to faking it and going along with social fictions when necessary’.
The cult of busyness
Jackall’s (1986) study of a large American corporation found that bullshitting was systematically expected of middle managers in the company. One informant told Jackall that his job involved ‘characterizing the reality of a situation with any description that is necessary to make that situation more palatable to some group that matters. Everyone knows that it’s bullshit, but it’s accepted. This is the game’. A crucial aspect was not using too much or too little bullshit, and also being able to judge the appropriate moment to bullshit. Competent bullshitters also needed to become competent audience members for performances of bullshit.
When ignorance is noisy, uninformed actors do not simply stay silent about what they don’t know. Rather, they are compelled to speak about an issue of which they have little knowledge or understanding. A recent experimental study found that this compulsion to speak (coupled with a lack of accountability created by a ‘social pass’) was an important factor in explaining bullshitting. For instance, middle managers are often relatively ignorant about the work their subordinates are engaged with, but are under pressure to act as the leader by doing or say something. They fall back upon generic management speak rather than engage with the people they manage in language they find meaningful. A second example is British government ministers who find themselves with a new policy portfolio. Often these politicians have little or no knowledge of the new policy area, but they are under pressure to say and do something. To address this tricky situation, politicians rely on empty and often misleading language.
The cult of leadership and entrepreneurship
Many conceptual entrepreneurs operate in the management ideas industry. This is a sector made up of consultants, gurus, thought leaders, publishers and some academics. The quality of actors operating in this industry tends to be extremely variable. A consequence is that some of the conceptual entrepreneurs seeking to peddle their wares in the management ideas industry are bullshit merchants. There are some sub-sectors of the management ideas industry where bullshit merchants are particularly concentrated. One is the ‘leadership industries’.
This sub-sector includes many consultants, speakers, experts and advisors who create and distribute pseudo-scientific ideas about leadership. A second sub-sector with a significant concentration of bullshit merchants is the ‘entrepreneurship industry’. This is the cluster of mentors, (pseudo-)entrepreneurs and thought leaders who push poorly evidenced, misleading and seductive ideas about entrepreneurship. Often their target is so-called ‘wantrepreneurs’. In some cases, these ideas have been found to encourage vulnerable young people to adopt what are seductive but empty and misleading ideas about entrepreneurial success.
Institutionalisation and sanctification of bullshit
Successful bullshitting enhances the image of bullshitters. This happens when bullshitters are able to more or less convincingly present themselves as more grandiose than they actually are. External audiences are more likely to make positive judgements about them and be more willing to invest resources in them. Organizations often use trendy but misleading names to attract resources (particularly from the uninformed). In recent years, firms have gained a boost in valuation by adopting a name invoking blockchain technology.
As well as enhancing one’s image, bullshitting can also help to enhance self-identity. This is because bullshit can enable bullshitters to conjure a kind of ‘self-confidence trick’. This happens when bullshitters mislead themselves into believing their own bullshit. Self-deception enables individuals to present themselves as much more self-confident than they would otherwise seem if they had to engage in cognitively taxing processes of dual processing (holding in one’s mind both the deceptive statement as well as the truth). The self-confidence which comes from self-deception can aid resource acquisition. For instance, entrepreneurs are encouraged to ignore their objective chances of failure so they can appear self-confident in their search for resources to support their venture.
When bullshit has become part of the formal organization for some time, it can slowly start to seem valuable in and of itself. When this happens, bullshit can be treated as sacred. Sanctification happens when an element of secular life (such as bullshitting) is elevated, a sense of higher meaning is projected into it, and deep existential significance is invested in it.
As long as life is framed as a competitive social game failure is guaranteed – because then the suffering of others is simply another great busyness opportunity [8].
In the rear view mirror, with a bit more historical distance, say from the vantage point of 2050, the commonalities between corporate capitalism (the “Western” model) and state capitalism (the “Chinese” model) may become more apparent, and the differences may be recognised as superficial.
Similarly, the changes following the collapse of the East German regime and the collapse of the Soviet Union in the late 1980s will be recognised as superficial in terms of cultural evolution – as processes of assimilation rather then as an evolutionary step change in social operating models. However, the changes in Eastern Europe do illustrate that assimilative changes are not predictable and are driven from the bottom up rather than from the top down within an established system. Changes from the top down tend to either amount to decorative window dressings or take on the form of violent conflict.
Wake up call
In aggregate, the COVID 19 pandemic, increasingly severe manifestations of the climate crisis, and growing levels of social inequities represent a powerful external force and an opportunity to cut through the façade of hypernormality.
While in earlier decades slower rates of ecological destruction and a lack of tangible climate related disasters have allowed baselines to shift with only few people paying attention, the rate ecological destruction and the frequency of climate related disasters has made it impossible for people to not notice the changes [9].
I think we should all start writing down our personal climate change baselines, stretching back as far as we can. This is what summer (winter) was like when I was a child. This is what it was like ten years ago, or two years ago. A small way to fight the pull of normalization.
A growing number of people from all over the world are waking up to the fact that faith in leaders is what is likely to lead to the end of our species and countless other species. Any tools and sets of knowledge that are incompatible with a path of radical energy decent are likely to rapidly become legacy technologies that are only relevant from a historic perspective – to warn future generations about technological approaches that have lead to existential risks.
“Normal” busyness as usual is slowly killing all of us. The sooner we unplug from the collective delusion, the fewer people will die or suffer needlessly. De-growth (a genuine reduction in unsustainable energy and resource consumption) can play out over generations, and it can be the most civilised project of mutual aid humans have ever undertaken.
Cultural evolution vs cultural revolution
Revolutions can be understood as phase shifts that occur when the level of cognitive dissonance that a population experiences between daily life and the fictions that are perpetuated by rulers and elites can no longer be maintained. In a revolution a large part of the population openly dismisses established institutions as dysfunctional and establishes new institutions based on ideas that often have been “fermenting” within the population for decades. Only some revolutions constitute a genuine shift in the paradigm of governance. The typical result tends to be a new set of institutions, a revised composition of the elites, and a new set of rules for maintaining an oppressive primate dominance hierarchy.
In contrast, the language system of evolutionary design provides us with a collaborative framing and terminology for evolutionary processes that allows bottom-up social movements to participate in the evolution of a living system, and to integrate their knowledge into a living system that includes humans, non-humans, and human designed systems.
Where to from here? We live in a highly dynamic world, and our capability to understand the world we have stumbled into is quite limited. Our destination is beyond human comprehension, but ways of life that are in tune with our biological needs and cognitive limits are always within reach, even when we find ourselves in a self-created life destroying environment. All it takes is a shift in perspective, and corresponding shifts in the aspects of our lives that we value.
In a world of global heating and ecological collapse, the direction of cultural evolution will determine how much suffering human societies will experience over the coming decades, and what kind of world will be available as the starting point for ecological regeneration.
David Graeber had a refreshingly down to earth and entrepreneurial approach to activism, which consisted of embarking on actions that seem appropriate to create a new reality (rather than simply engaging in civil disobedience) – and ignoring the established status-quo as needed to overcome crippling paradigmatic inertia. He conceptualised the revolt of the caring classes [10] and encouraged the activation of bureaucratically suppressed knowledge, i.e. the things that people are not allowed to talk about, into a power that can transform society.
I have a very similar philosophy. Our team at S23M is actively involved in catalysing cultural evolution in the healthcare sector. If you are stuck in a place where busyness as usual is getting in the way of cultural evolution, just follow the money to know where to start building new models from the bottom up. As long as governments operate healthcare like a busyness, from the top down, rather than from the bottom up, based on the needs of local communities, whānau, and patients, healthcare organisations remain paralysed by paradigmatic inertia.
Evolutionary design allows organisations and people to participate in the evolution of a living system and to integrate their knowledge into a living system that includes humans, non-humans, and human designed systems.
Evolutionary design is an approach that is based on the principles of cultural evolution that can be derived from anthropological observations and archaeological evidence about human scale societies that predate the emergence of civilisations. In evolutionary design the moniker of design is replaced by the concept of evolution. Cultural evolution entails not only the evolution of collaborative relationships and supporting tools within a group, but also the evolution of collaborative relationships between groups with many cultural commonalities and also between groups with few cultural commonalities.
This article hints at the huge potential for cultural diversity at human scale in the absence of super-human scale hierarchical systems of command and control. The principles of evolutionary design have been distilled from my experiences with cultural evolution in human scale groups and between human scale groups. Evolutionary design principles are introduced in a tabular form that maps them to related Design Justice Network principles and to contrasting principles that otherwise commonly drive design in industrialised societies.
We have created education factories that focus almost entirely on replication. However, humans have evolved as part of highly diverse ecosystems, i.e. we have evolved to survive and thrive in highly diverse contexts, rather than as part of super human scale monocultures, i.e. nation states, transnational corporations, and physical environments dominated by industrialised agri-monocultures.
Modern industrialised societies neglect the four other evolutionary functions that operate in healthy ecosystems that include humans: understanding of the local ecosystem and the roles of the various species within it, selection of variants that increase diversity and strengthen the ecosystem against external shocks, experimentation with new variants to uncover new possibilities, and sustaining collaborations within and between species that are adapted to the characteristics of the local environment.
In the industrialised neoliberal ideology, cultural evolution is reduced to a dangerously simplistic notion of innovation:
The role of selection is reduced to a simplistic optimisation problem in a single dimension, i.e. growth in the abstract sphere of monetary metrics. In a suitably designed financial system this creates a consistent bias that benefits those who start out with above average financial resources.
The role of experimentation is reduced to the superficial material variability that is easily achievable via mass customisation, and it excludes any variability that might undermine the self-preservation of established institutionalised power structures (national governments and transnational corporations). Amongst other things this is achieved by systematically pushing entrepreneurs down a path of “start-up” models that hand over control to speculators, and by co-opting the most compliant and unscrupulous entrepreneurs into the speculator class.
The role of sustaining collaborative relationships within living ecosystems is reduced to the perpetuation of established institutionalised human power structures.
The role of human understanding of the local ecosystem, and the well-being of marginalised groups and of all the non-human inhabitants are at best secondary concerns.
The fragile economic mono-cultures that emerge from competition are prone to boom and bust cycles – the net effect is a waste of precious time and scarce resources.
The 26 evolutionary design principles in the context of design justice
The evolution of healthy ecosystems, communities, understandable companies, and trusted relationships between all participants is shaped by the limits of human scale (Schumacher. 1973, Norberg-Hodge 1991).
Instead of the traditional framing of a company or organisation as consisting of individuals, framing it as a set of binary relationships between specific people is a useful tool for understanding companies and communities as evolving systems. Egalitarian relationships shift the focus away from dangerous tribalism towards a model where collaboration between groups is as relevant as collaboration within groups.
Evolutionary design takes the widest possible context and potential limits of applicability into account, by focusing on the diversity of locally relevant perspectives across the intended scope, by emphasising minority perspectives, and by acknowledging the counter-productive role of all forms of social power gradients. It provides principles that help guide the scope of universal design, by confirming the scope of design variants needed beyond universal design, co-designing the universal elements and design variants with relevant communities, and by identifying opportunities for reuse between variants.
The intent of evolutionary design in terms of accommodating diversity of needs corresponds to the intent of inclusive design, i.e. “design that considers the full range of human diversity with respect to ability, language, culture, gender, age and other forms of human difference”, including explicit recognition of neurological differences as relevant factors.
The understanding that power gradients stand in the way of transformation is fundamental, and explicitly connects the drivers of evolutionary design to the goals of design justice. Evolutionary design seeks to reestablish local egalitarian social norms similar to the most important norms that characterised the small scale societies that existed before the emergence of formal institutions of concentrated social power and written systems of record keeping, i.e. the matrix of domination.
Evolution at human scale can be described in terms of 26 design principles. The table below maps the principles of evolutionary design to the ten Design Justice Network principles and contrasts them with commonly encountered design objectives in industrialised societies.
Intentional bottom-up cultural innovation at human scale
Fast paced cultural innovation at human scale is the home turf of small software technology companies. The core components in the context of software companies have a one to one correspondence to the core components in biological systems:
human organisations ➜ biological organisms
platforms ➜ bioregions
products ➜ species
services/functions ➜ services/functions
The core activities in biological ecosystems map to software product line design and engineering streams of activities and feedback loops as follows:
The correspondence is no accident. Software companies that combine deep domain specific expertise with the capability to conduct experiments and a commitment to learning about the commonalities and variabilities of user needs, with a particular focus on marginalised and non-obvious users, operate in a quality and productivity league that differs by one or more orders of magnitude from software companies that don’t apply a software product line approach (i.e. evolutionary principles) to their work.
What is the significance of the correspondence? The practical significance of the correspondence is profound, as it provides us with a collaborative framing and terminology for evolutionary processes, including evolution guided by conscious human design and ecological interdependencies and limits, without any reference to the hyper-competitive cultural bias of neoliberalism, or the deeply misguided assumption that competitive markets are the best mechanism for “driving” cultural evolution.
The evolutionary lens allows organisations and people to participate in the evolution of a living system and to integrate their knowledge into a living system that includes humans, non-humans, and human designed systems. Software product line engineering can be understood as a form of collaborative niche construction.
Human guided cultural evolution
No successful software company would ever organise in terms of competing teams to develop the best possible product. Quite the opposite is the case. Software companies that take a product line approach operate dedicated work-streams and teams for each of the four core activities within the evolutionary process:
experimentation with variations in implementation technology choices and operational environments to better meet customer needs,
platform engineering, i.e. deliberate selection of common features that are useful for specific categories/species of customers that use the product line,
product engineering, i.e. replication of best engineering practices in the assembly of concrete products for specific customers,
product line operations, i.e.sustaining the provision of services to customers and processing feedback from customers.
In a product line approach parallel experiments in a collaborative ecosystem replace head-on competition in a disruptive market environment as a major driver of evolution. Instead of being commodified resources and objects of financial speculation, the people and teams involved in product line evolution are part of a larger community of learning and mutual aid (Kropotkin 1902).
Successful software products that are used by many thousands or millions of customers are best thought of as a domain specific language system that complements human cognitive abilities and that facilitates and mediates collaboration and/or social competition between humans.
In a networked world with ubiquitous internet connectivity and pervasive use of Internet enabled personal devices, software plays a significant role in guiding – or even forcing – human cultural evolution. Experienced software companies develop fast paced collaborative feedback loops with customers in order to minimise misunderstandings, and to gain a deeper understanding of the commonalities and the variabilities of customer needs in specific niches and geographies, which in turn is fed into the evolutionary process that shapes the future scope and functionality of the product line.
Software product design conducted in isolation, without giving customers and marginalised groups the ability to shape the design, is a form of social engineering, whether intentional or not. All users of the Internet are familiar with the social externalities. Online social media platforms (Facebook, Twitter, Linkedin, etc.) dictate the possible communication and collaboration patterns, and in doing so typically maximise the “return on investment” for the owners of the platform, in the metrics of success prescribed by the neoliberal paradigm.
The huge opportunities and dangers of mediating human communication and collaboration and/or social competition via software platforms can not be overstated. The language systems that we create with the help of software can either amplify the unique human capacity for compassion and creative collaboration or they can amplify social competition and the brutal power politics that characterise primate dominance hierarchies.
The combination of experimentation and platform engineering replaces direct competition between people and companies with collaborative niche construction as the driving force of cultural evolution. The collaborative approach is much less energy intensive, it nurtures mutual trust within and between companies, and it wastes less time and genuinely scarce resources.
The COVID-19 pandemic is the latest reminder of how dependent our societies have become on software as an extension of the language system we use on a daily basis. The words we type into our devices may look familiar, but the ways in which they are processed, and who gets to see them and interpret them, are increasingly beyond our control. Similarly the words and images we are fed via our screens have been pre-processed, filtered, arranged, and decorated in ways that are largely beyond our control.
There are huge differences between the software platforms at our disposal. Whilst many software platforms encourage toxic competitive social games other software platforms are the most amazing tools for catalysing specific kinds of collaboration. As a software platform co-designer (i.e. language system co-designer) I am acutely aware of how the work of specific organisations and teams can be greatly improved for all participants, by finding ways to:
reduce misunderstandings,
catalyse knowledge flows and essential interactions that nurture trusted relationships and a greater level of shared understanding,
reduce cognitive load, by giving users the tools to automate repeating patterns of coordination tasks according to their individual preferences, and according to dynamically evolving needs.
There is a fundamental qualitative difference between (a) software platforms that serve the neoliberal paradigm and (b) software platforms that are operated by employee owned companies and that evolve together with the communities and organisations that use the software, to catalyse communally agreed patterns of collaboration, and to automate administrative chores.
Cultural evolution in the context of ecological collapse
Understanding how software platforms evolve is important because of their role as a language system that shapes human interactions in a world of zero marginal cost communications (Rifkin 2013). Cultural evolution of course is a topic that is much bigger than software. In a dynamic world of global heating and ecological collapse, its direction will determine how much suffering human societies will experience over the coming decades, and what kind of world will be available as the starting point for ecological regeneration.
If we leave the evolution of software platforms in the hands of profit maximising corporations, the future is one of extreme paradigmatic inertia – concluding the sixth mass extinction event with the literal liquidation of the planet. If instead we rediscover the language of life at human scale, we have the chance of nurturing the evolution of human scale collaboration platforms that are attuned to the task of ecological regeneration and mutual aid rather than the task of planetary liquidation and competitive social games.
In a world of zero marginal cost communications, capital is no longer a necessary prerequisite for the development of software platforms. The world of software platforms is already a world of shiny (i.e. capitalised) candy wrappers around Open Source software. It is time to discard the wrappers and focus on evolving the substrate for human communication and creative collaboration.
Equipped with an appreciation of the human capacity for collaboration and an understanding of human cognitive limits, a very simple question can guide us towards the future:
Which of the following choices is likely to be less energy intensive?
Option A. Living life to nurture, maintain, and repair trusted relationships at human scale, by implementing prosocial principles (Atkins et al. 2019) and tailoring creative collaboration tools (the principles of evolutionary design) to local needs.
Option B. Living life competing against each other according to culturally defined rules, and having to assume that everyone has an interest in subverting the rules for personal gain.
As Joseph Tainter’s analysis of complex societies (1988) shows, collapse of hierarchical complexity “is not a fall to some primordial chaos, but a return to the normal human condition of lower complexity”. Declining marginal returns on investments in established administrative structures ultimately result in an imperative to establish less energy intensive forms of collaborations that are more inclusive in terms of the diversity of stakeholders involved in shaping the path forward.
Decades of research and empirical evidence demonstrates that behaviourism, i.e. all forms of management based on rewards and or punishment don’t work over the medium and long term. We know that rewards and punishment only superficially and temporarily lead to perceived compliance or higher levels of performance. All forms of coercion and control, irrespective of the level of sugar coating, undermine trust and the human capacity for altruism and mutual aid.
Take a moment to reflect on the way in which abstract institutions, i.e. companies, governments, and other organisations make decisions and how these decisions affect our lives. How much do these institutions understand about the thousands and millions of people and the billions of relationships affected by their decisions? The inevitable conclusion:
The average person is more conscious of their own limits (more intelligent) than most of the institutions that we have created to operate our society.
The sweet spot of good company (human scale) lies somewhere between the collective insanity of large corporations and the individual limits of cognitive ability and experience – limited by our ability to nurture, maintain, and as needed repair trusted relationships.
Basic implications of the limits of human scale for the creation of good company:
Don’t look to large established institutions for advice; all hierarchical models of command and control dampen essential feedback loops, and thereby induce a collective learning disability
Optimise for trusted collaboration and collective intelligence at human scale
To build trusted eye level relationships, extend trust, but do so incrementally, one step at a time
As part of extending trust, share not only information about your strengths but also information about your cognitive limits and vulnerabilities
If you need advice, ask trusted friends and colleagues who know and genuinely understand you
The journey towards a healthier relationship with the ecosystems which we are part of starts with the most powerful tool at our disposal, the introduction and consistent use of new language and new semantics – and we can catalyse cultural evolution in this direction with a shift towards zero capital software platforms, i.e. by leaving behind the shiny candy wrappers, and by prioritising support for mutual aid and ecological regeneration in the foundations of our digital language systems.
You may wonder which aspects of Western industrialised knowledge are worthwhile to retain (and for how long), given that cultural evolution is a dynamic process that unfolds over multiple generations. In a recent talk and subsequent Q&A Rupert Read (2021) offers valuable suggestions for cultural evolution beyond the abstract realm of software platforms.
The following sets of knowledge are good candidates for preserving and cultivating in a global knowledge commons:
Locally successful collaborative social operating models and traditions, which can be documented in detail, including their known scope of applicability and known limitations, and can be made available for partial or complete adoption and refinement by communities in other parts of the world that are facing similar challenges and constraints
Our scientific understanding of the natural world, which complements traditional forms of knowledge about local ecosystems
The diagnostic tools, treatment regimes, and surgical knowledge of Western medicine, which can be made available for integration into holistic approaches to well-being that are adapted to the specific contexts of local cultures and physical environments
The engineering knowledge that underpins our digital computation and communication technologies, which allows us to share, validate, and incrementally refine valuable knowledge globally
The engineering knowledge needed for local generation of electricity from renewable sources, to power essential digital technologies and to compensate for local or temporary limitations of human labour
The emerging de-engineering knowledge needed for creating zero-waste cycles of material resources, to reduce and ultimately eliminate our dependence on the mining of non-renewable resources
Any tools and sets of knowledge that are incompatible with a path of radical energy decent are likely to rapidly become legacy technologies that are only relevant from a historic perspective – to warn future generations about technological approaches that have lead to existential risks.
Conclusion
The lessons about evolutionary design as described in this article have their roots in the world of software and data intensive products, and more fundamentally, in our understanding of egalitarian human scale societies, but the scope of applicability is by no means limited to the world of data and software.
We all thrive when being given the opportunity to work with our most trusted peers. In good company everyone is acutely aware of all the collective intelligence and capability that is available in the form of trusted colleagues, friends, and family.
“Transdisciplinary collaboration hinges on psychological safety, cultural safety, and inclusiveness. These and other human factors determine the inherent social value of a company, the wellbeing of employees, and the quality of care delivered to patients.”
Terry J Hannan, Visiting Faculty Australian Institute of Health Innovation, Macquarie University, International Academy of Health Sciences Informatics
Organisations are only able to deliver valuable services to the extent that they can rely on a network of trusted relationships both within the organisation and the wider community that supports and is supported by them.
References
Atkins P. W. B. et al. 2019. Prosocial: Using Evolutionary Science to Build Productive, Equitable, and Collaborative Groups. Context Press.
Like bees and ants, humans are eusocial animals. Through the lenses of evolutionary biology and cultural evolution, local communities – and especially small groups of 20 to 100 people – are the primary organisms within human society, in contrast to individuals, corporations, and nation states. The implications for our civilisation are profound.
The documentary “Ancient Futures: Learning from Ladakh” (John Page, Chris Breemen, Helena Norberg & Hodge & Eric Walton, 1993) provides an excellent introduction to the local, human scale traditions in Ladakh, and how local communities have been affected by the industrialised notion of “progress”.
The observation that consumer culture as portrayed in advertisements and Western media appeals primarily to insecure teenagers is apt. I am tempted to qualify the observation from my autistic perspective: consumer culture is designed to target neuronormative teenagers, i.e. those for whom fitting in with their peer group comes naturally. If teenage boys were the first adopters of Western values in Ladakh, I wonder whether this may simply reflect that teenage girls had perhaps been given less opportunity to spend time in the city, and had therefore been less exposed to Western influence. From personal experience in multiple Western cultures I would suggest that autistic teenagers, irrespective of gender identity, are less susceptible to the addiction to consumer culture – simply because autistic teenagers don’t see the point of the competitive social games that consumerism depends on.
What I find delightful is the way in which the traditional culture in Ladakh is based entirely on trusted relationships at human scale instead of abstract group identities. The focus on trusted relationships mirrors the way in which autistic people collaborate and develop autistic culture – if given the opportunity. In the traditional culture in Ladakh, where every person is appreciated for their unique strengths and weaknesses, it would seem very unlikely for autistic people to be pathologised. In such a culture, autistic people would likely be appreciated for their ability to focus, their unique knowledge, and their ability to assist with solving unusual problems.
It is also fascinating and terribly sad to see a concrete example of how a Western style education system systematically extinguishes precious knowledge about the local environment and about locally sustainable ways of living within a single generation. I see a direct connection between hypernormative Western education systems and the increasing levels of pathologisation of autists and other neurodivergent people in Western societies. I was lucky at school. I aced most of the academic parts, because I am not dyslexic and because I enjoyed abstract mathematics. But I learned so much more outside school in autodidactic mode, from books and from experimenting with various tools and materials. Neuronormative children who rely much more on social learning readily absorb the cultural diet they are fed, and if that diet is limited to the monoculture of industrialised consumer society, the effects are devastating.
The documentary reminds me a lot about what I saw as a small child in the early 1970s in Nigeria: pollution, slums, crime, and exponential population growth in Lagos, in stark contrast to traditional villages further afield, which were largely self-sufficient and very different from the Western way of life. In Nigeria “economic growth” and “progress” were fuelled by the interests of Big Oil. I also remember the way in which Western adults at the time talked about what they saw as “uneducated” people, and the way in which Western countries delivered “development aid” and “best practices” – establishing large cattle farms, drilling deeper water wells etc. When it all failed, it was much easier to blame the locals than to admit to cultural bias, corporate greed, and lack of appreciation of local knowledge and wisdom.
The follow-up documentary on “The Economics of Happiness” (Helena Norberg-Hodge, Steven Gorelick, and John Page, 2011) from Local Futures on the toxic role of globalisation was made shortly after the Global Financial Crisis, and is still valid today.
This documentary emphasises and illustrates the critical role of communities and trusted relationships at human scale. What makes it stand out is the holistic perspective on how collective well being and livelihoods have been affected by globalisation in the industrial era, and the many concrete examples of the direct effects of globalisation from local perspectives around the planet. In contrast, otherwise very good documentaries often have a narrow focus on a specific industry, or on climate change, or on ecological destruction.
Together I think both documentaries constitute a powerful tool for educating the world about the critical importance and the immense value of life at human scale, and about all the knowledge, wisdom and happiness we are losing by myopically focusing on the industrialised notion of economic growth, with still dominates the global economy.
We must not be fooled by simplistic multiple-bottom line approaches. As Daniel L. Everett points out, human cultures across the board are often remarkably similar in their values, but they tend to differ significantly in the relative ranking of what is perceived as valuable – and these differences in relative priorities lead to very different dynamics.
Only in a W.E.I.R.D. globalised world is money always the bottom line at the bottom of all bottom lines, where return on investment is not measured in trusted and mutually enjoyable relationships, but in purely monetary terms.
The following discussion on decentralising social power (Daniel Christian Wahl and Helena Norberg-Hodge, 21 June 2020) connects the themes of globalisation and (re)localisation to our present situation in 2021.
Both Daniel Christian Wahl and Helena Norberg-Hodge recognise that education and activism needs to occur alongside work within local communities at human scale. To overcome the paradigmatic inertia that paralyses our industrialised monoculture, we need to fully expose the cultural and ideological bias of W.E.I.R.D. hypernormality, including all the unspoken social norms (the W.E.I.R.D. axioms) that are not encoded in any legislation but that are applied unquestioned on a daily basis.
It is quite concerning to see the neoliberal ideological bias perpetuated in New Zealand, even 12 months into a global pandemic. Rising house prices are aggravating severe levels of inequality and are causing some level of debate, but politicians continue to shy away from taking measures that could reverse the trend. In Opotiki in the Bay of Plenty for example, the rental market is drying up, and the traditional local community is incrementally being destroyed by market forces. Healthy communities and human relationships have become externalities in the financialised economic game.
In my book “The beauty of collaboration at human scale” I offer thinking tools that may assist us to unW.E.I.R.D. some of the perverse institutions of Western culture and to develop new institutions that are attuned to human scale. The book highlights the invaluable role that marginalised minorities and neurodivergent people have always played in human cultural evolution, in particular in times of crisis.
For our journey into the future we need appropriate tools for addressing challenges and needs over different time horizons. Below is an overview of regional, local, and online community-oriented work that I am involved in. Please get in touch in case you would like to contribute to any of these communities or if you have questions regarding any of these resources.
Regional peer groups and short-range tools for survival
People talk about a global ecological crisis, a climate crisis, an economic crisis, an institutional crisis, a pandemic, and a mental health crisis. These crises are highly interconnected.
Gaining a comprehensive understanding of human potential and limitations is not possible from within any single discipline. Not only is each discipline focused on specific aspects of human behaviour, but the different disciplines that examine human behaviour rest on mutually contradictory assumptions about human nature.
Understanding the co-creation of values
Economist Mariana Mazzucato points out that the activities that societies consider “productive” or “valuable” are subject to significant shifts over the decades and centuries. She observes that GDP is a hodge-podge that invites lobbying rather than reasoning about value and that the continuously evolving values within society need to become part of economic reasoning for the discipline of economics to remain relevant.
Mariana Mazzucato also explains why we shouldn’t try to go back to “normal” after the pandemic, but should instead rethink how governments can work together with businesses in partnership to solve big problems. She advocates making use of multi-dimensional metrics to track progress towards desirable goals. Trained in contemporary economics, she does however rely on the implicit assumption that markets are essential tools for coordinating human activities at scale.
It requires a transdisciplinary understanding of human collective behaviour to realise that fungibility of abstract metrics (the currencies that are used to coordinate activities within markets) is a major problem, especially as long as individuals have radically different levels of access to fungible currencies.
The mathematics that optimise markets are blind to externalities, and as long as market based incentives are used, people will look for ways to circumnavigate or co-opt any regulatory constraints to invent new competitive games, thereby shifting or obfuscating rather than reducing externalities.
Understanding humans
Michael Tomasello has spent many years working with children and with chimpanzees to understand the evolution of collaborative behaviour, and to explore how human behaviour differs from the behaviour of other primates. From a recent interview on the foundations of human cultural capability:
“When children produce sweets collaboratively they feel they should share them equally… So if you look at all the things you think are most amazing about humans – we’re building skyscrapers, we have social institutions like governments, we have linguistic symbols, we have math symbols, we have all these things – not one of them is the product of a single mind. These are things that were invented collaboratively…”
A range of simple experiments show that in contrast to chimpanzees, human babies and young human children are highly collaborative, which may come as a surprise to many economists.
However, to understand human creativity and collective intelligence beyond the most basic forms of collaboration, we must look beyond the experiments conducted by Michael Tomasello and his colleagues. To appreciate the full range of human collaborative ability we need to consider the influence of individual neurological variability on sensory processing and social motivations. Unfortunately on this topic Michael Tomasello’s understanding of autistic people is limited to literature references and “autism research” conducted under the pathology paradigm.
In this article I dive into the cultural evolutionary pressures that allowed autistic traits to proliferate and persist, and I rely on personal experiences to illustrate (a) why autists collaborate in ways that differ from “normal” expectations and (b) why we are uniquely equipped to act as catalysts and translators between different cultures and groups.
The innate collaborative human tendency demonstrated by Michael Tomasello is also supported by anthropological research.
Samuel Bowles is an economist that has spent his career researching the origins of economic inequality over the last 100,000 years, and he comes to very interesting conclusions that are consistent with my own understanding of human cultural evolution and my observations on the new forms of collaboration and communication that have become possible in a digitally networked world.
Designing complex collaborations and flows
Our future depends on the adoption of new forms of creative collaboration. The kind of mathematics that can assist us in reasoning about dynamically evolving value systems and the coordination of non-trivial circular resource flows involve groups and graphs rather than numerical calculations.
The ecological lens is a modelling language for evolving ecosystems. It connects the human lens and the evolutionary lens via the activity of play and a critical perspective/motivation. The ecological lens catalyses diversity within the living world from an ecological perspective.
The evolutionary lens is a modelling language for collaborative niche construction. It consists of five categories that correspond to core elements of modern evolutionary theory (selection, variation, replication, understanding, and sustaining). The evolutionary lens allows organisations and people to participate in the evolution of a living system and to integrate their knowledge into the living system that includes humans, non-humans, and human designed systems.
The human lens is modelling language for human social behaviour that allows us to understand living systems and to reason about such systems. It consists of thirteen categories that are invariant across cultures, space, and time. The human lens provides a visual language and reasoning framework for transdisciplinary collaboration. The human lens allows us to make sense of the world from a human perspective, to evolve our value systems, and to structure and adapt human endeavours accordingly.
Within the human lens the logistic lens provides five categories for describing value creating activities: grow (referring to the production of food and energy), make (referring to the engineering, and construction of systems), care (referring to the maintenance of production and system quality attributes), move (referring to the transportation of resources and flows of information and knowledge), and play (referring to creative experimentation and other social activities). The logistic lens can be used to model and understand feedback loops across levels of scale (from individuals, to teams, organisations, and economic ecosystems) and between agents (companies, regulatory bodies, local communities, research institutions, educational institutions, citizens, and governance institutions).
From wealth to good health
The categories of the logistic lens assist in the identification of suitable quantitative metrics for evaluating performance against a multi-dimensional value system articulated via a configuration of the semantic lens (the five categories of social, designed, symbolic, organic, and critical).
In the transition from a paradigm of economics based on competition to a to an ecology of care based on collaboration we will incrementally discover valuable metrics of health, well being, and waste flows, and we will become less and less concerned about abstract and potentially misleading metrics of wealth accumulation.
In an ecology of care the focus shifts from speculative investments for profit (where the people actively involved in a venture are viewed as tools towards a profitable “exit”) to investments in the health of ecosystems and people (where the people actively involved in a venture are co-investing in each other, resulting in a network of trusted relationships that connects the venture into an ecosystem of multi-dimensional resource flows between suppliers, customers, and partners).
Our society faces the unprecedented challenge of making a transition towards significantly different values within a single generation. This is the real challenge, rather than finding our way back to a state of “normal” that only ever worked for a very small minority.
From an ecological perspective waste flows are destined to emerge as the most critical flows that need to be tracked and quantified meticulously. It will also make sense to quantify selected biological health metrics, but it may not make much sense to attempt to quantify all aspects of well being.
Reading list
Beyond the articles and talks referenced in the article, below is a list of related books and background articles:


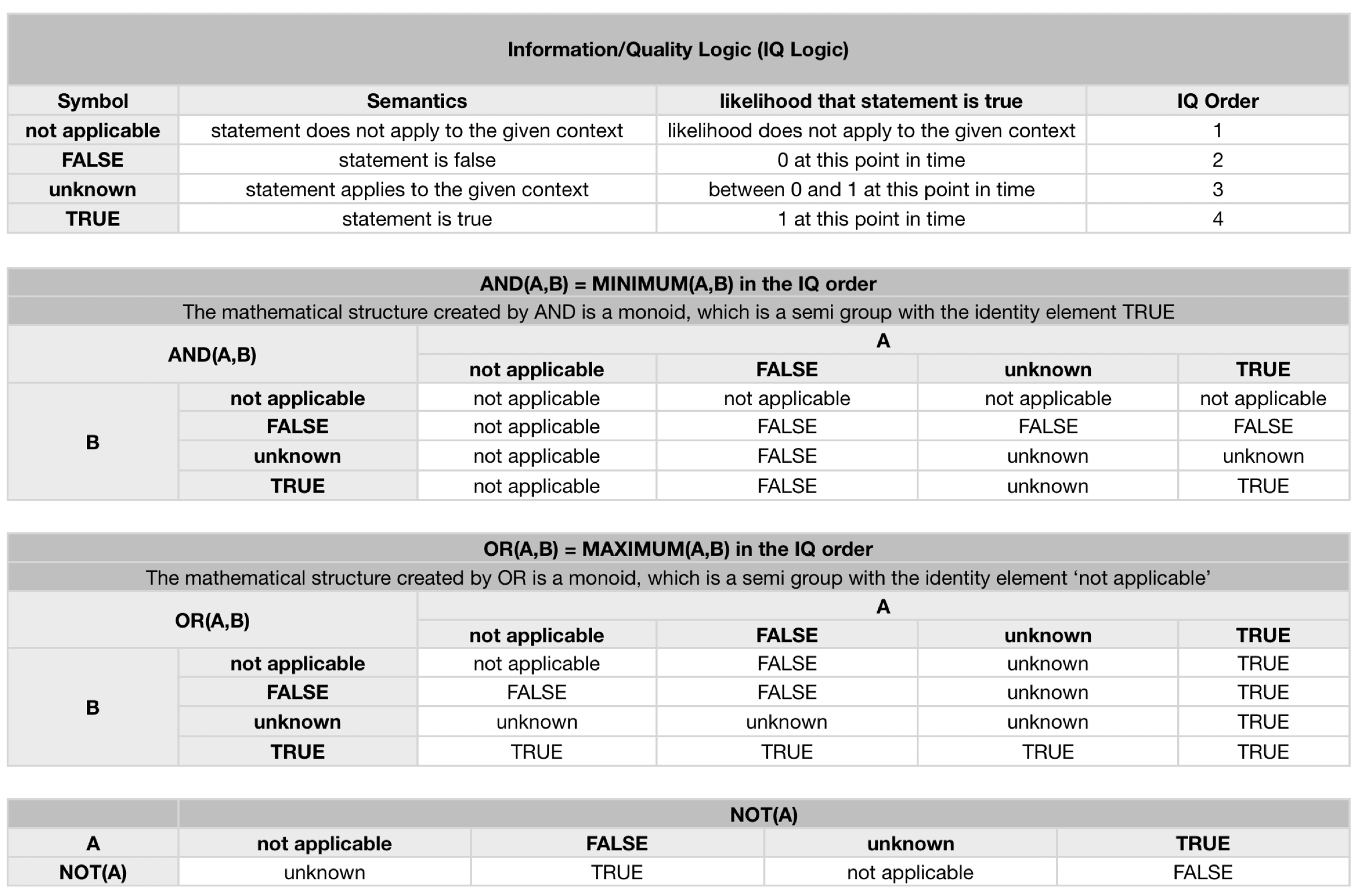







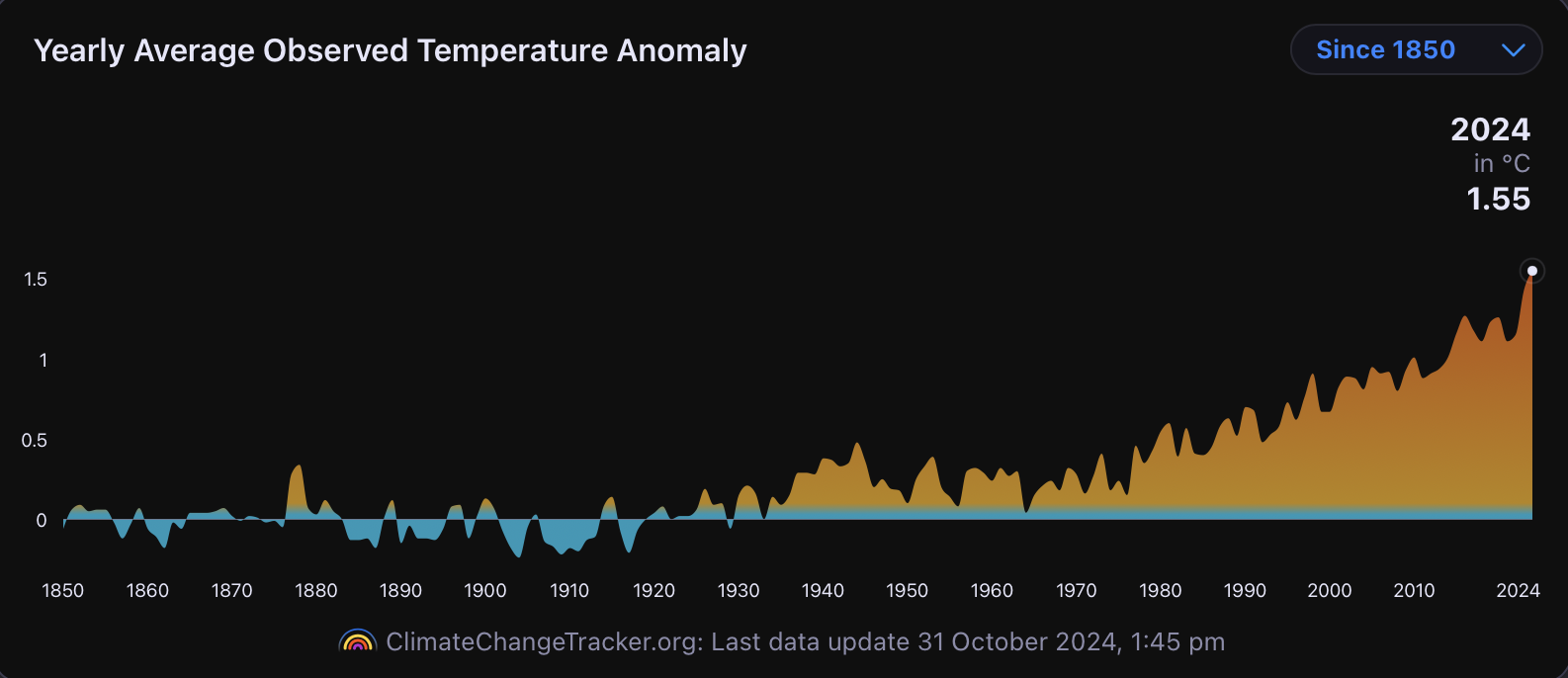
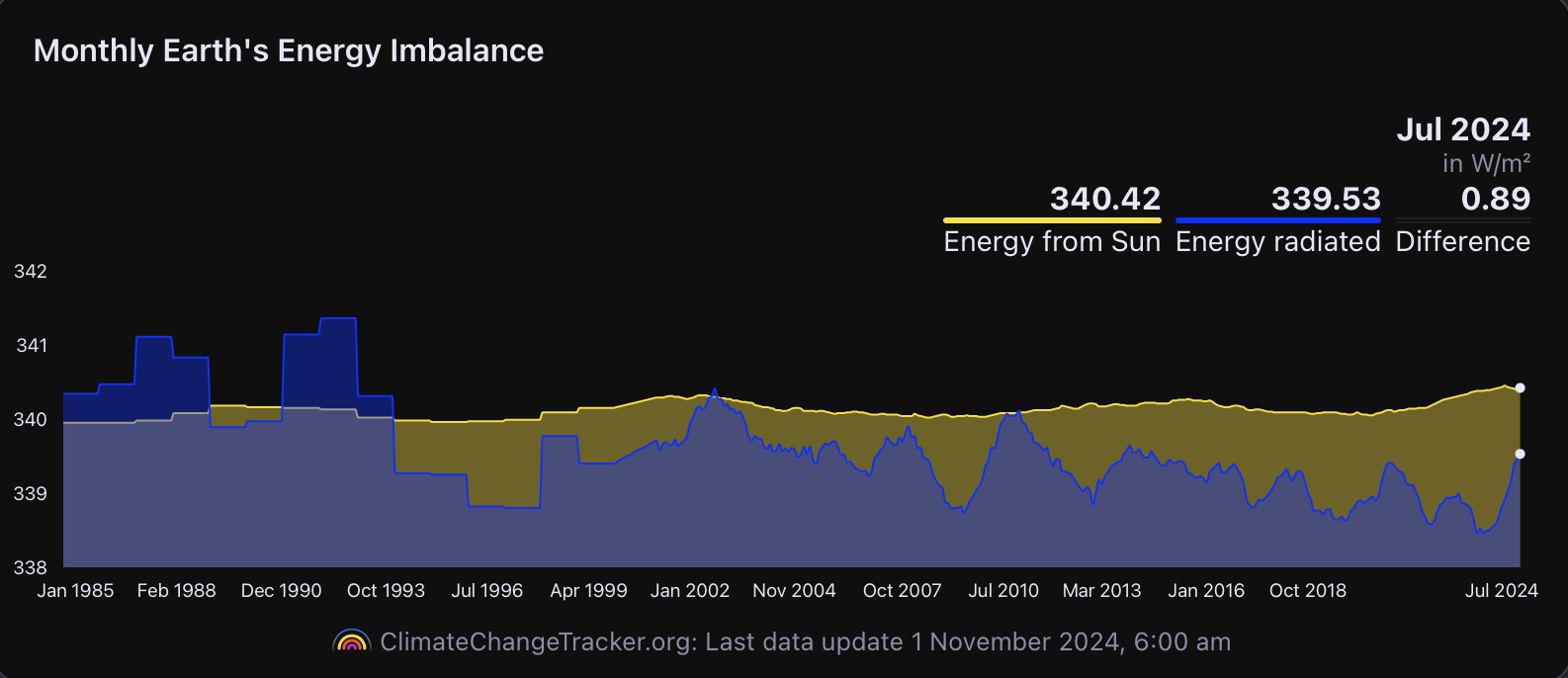








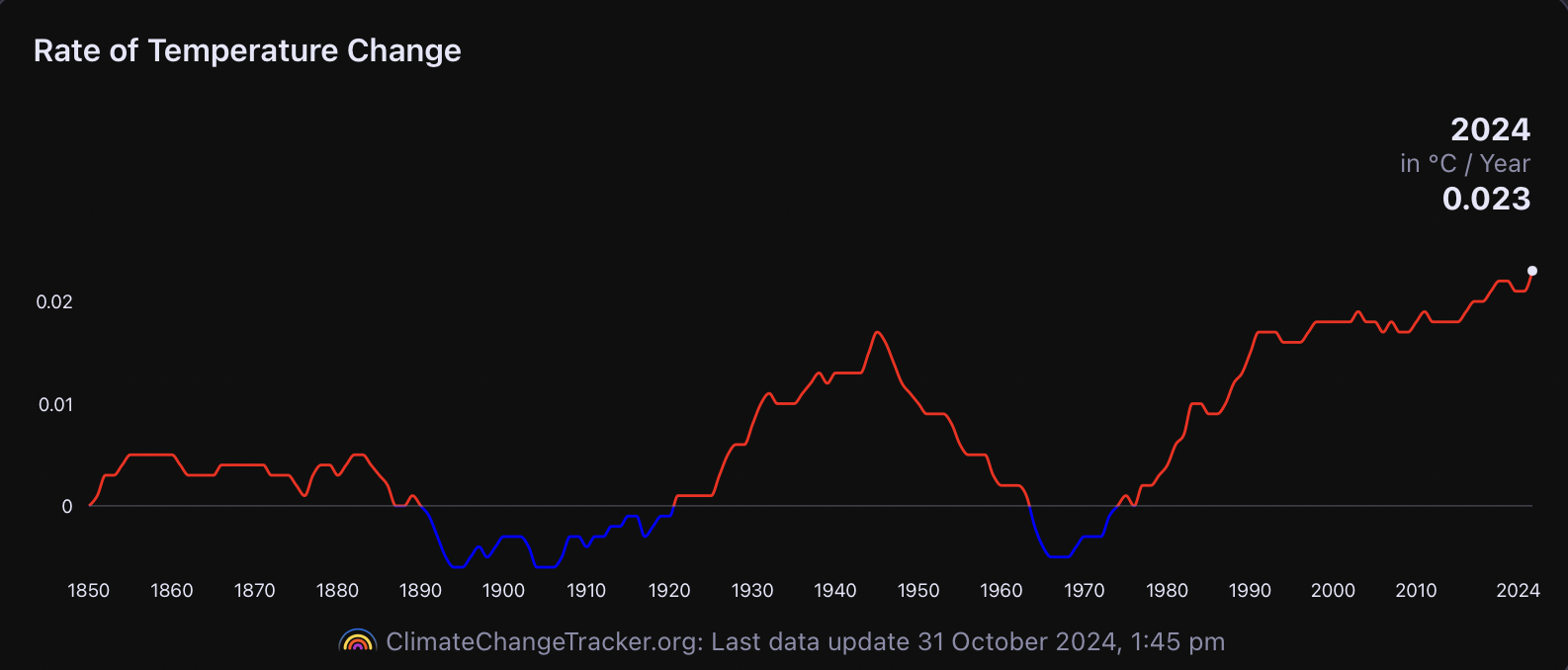






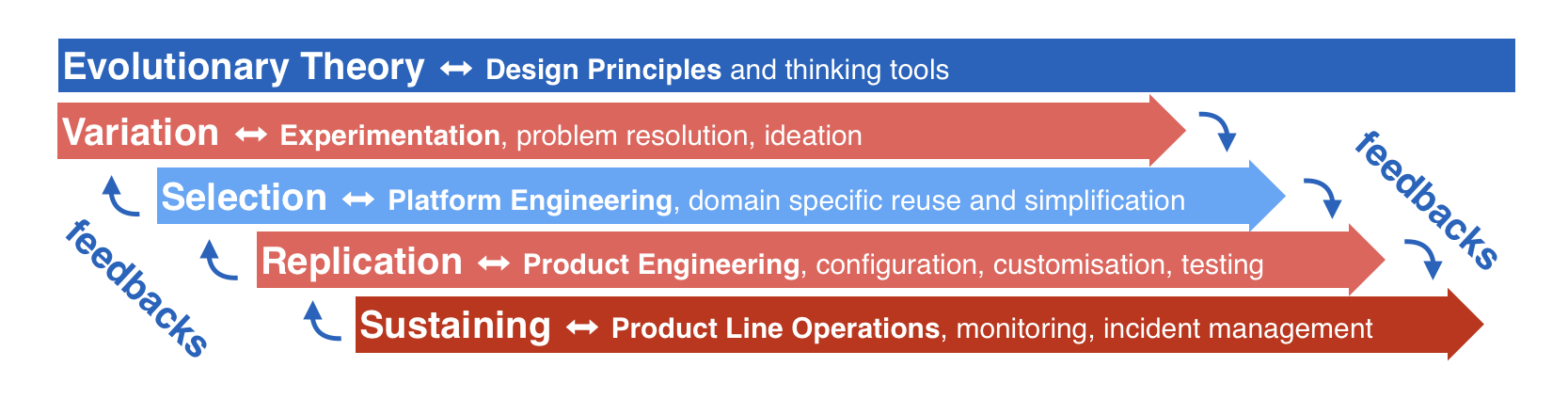




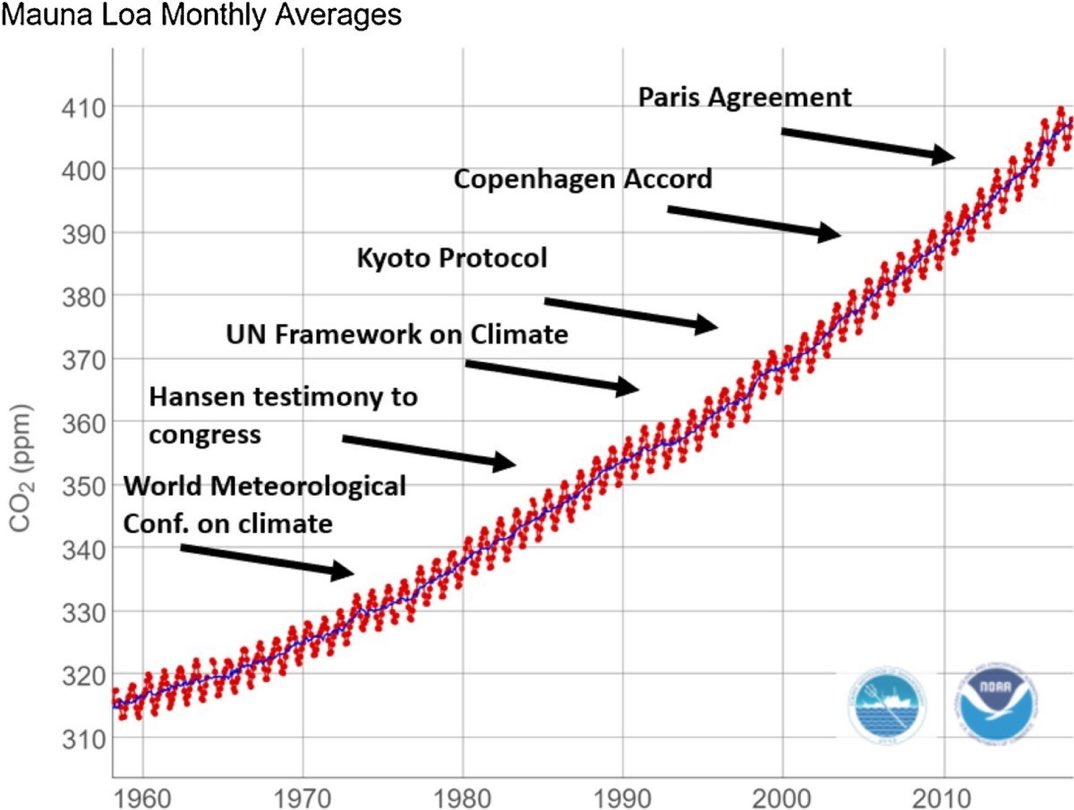




You must be logged in to post a comment.