Over the last few years the talk about search engine optimisation has given way to hype about semantic search.

context matters
The challenge with semantics is always context. Any useful form of semantic search would have to consider the context of a given search request. At a minimum the following context variables are relevant: industry, organisation, product line, scientific discipline, project, and geography. When this context is known, a semantic search engine can realistically tackle the following use cases:
- Looking up the natural language names or idioms that are in use to refer to a specific concept
- Looking for domain knowledge; i.e. looking for all concepts that are related to a given concept
- Investigating how a word or idiom is used in other industries, organisations, products, research projects, geographies; i.e. investigating the variability of a concept across industries, organisations, products, research projects, and geographies
- Looking up all the instances where a concept is used in Web content
- Investigating how established a specific word or idiom is in the scientific community, to distinguish between established terminology and fashionable marketing jargon
- Looking up the formal names that are used in database definitions, program code, and database content to refer to a specific concept
- Looking up all the instances where a concept is used in database definitions, program code, and database content
These use cases relate to the day-to-day work of many knowledge workers. The following presentation illustrates the challenges of semantic search and it contains examples that illustrate how semantic search based on concepts differs from search based on words.

Do you know what I mean?
The current semantic Web is largely blind to the context parameters of industry, organisation, product line, scientific discipline, and project. Google, Microsoft, and other developers of search engines consider a fixed set of filter categories such as geography, time of publication, application, etc. and apply a more or less secret sauce to deduce further context from a user’s preferences and browsing history. This approach is fundamentally flawed:
- Each search engine relies on an idiosyncratic interpretation of user preferences and browsing history to deduce the values of further context variables, and the user is only given limited tools for influencing the interpretation, for example via articulating “likes” and “dislikes”
- Search engines rely on idiosyncratic algorithms for translating filters, and “likes” and “dislikes” into search engine semantics
- Search engines are unaware of the specific intent of the user at a given point in time, and without more dynamic and explicit mechanisms for a user to articulate intent, relying on a small set of filter categories, user’s preferences, and browsing history is a poor choice
The weak foundations of the “semantic Web”, which evolved from a keynote from Tim Berners-Lee in 1994, compound the problem:
“Adding semantics to the Web involves two things: allowing documents which have information in machine readable forms, and allowing links to be created with relationship values.”
Subsequently developed W3C standards are the result of the design by committee with the best intentions.
All organisations that have high hopes for turning big data into gold should pause for a moment, and consider the full implication of “garbage in, garbage out” in their particular context. Ambiguous data is not the only problem. Preconceived notions about semantics are another big problem. Implicit assumptions are easily baked into analytical problem statements, thereby confining the space of potential “insights” gained from data analysis to conclusions that are consistent with preconceived interpretations of so-called metadata.
The root cause of the limitations of state-of-the-art semantic search lies in the following implicit assumptions:
- Text / natural language is the best mechanism for users to articulate intent, i.e. a reliance on words rather than concepts
- The best mechanism to determine context is via a limited set of filter categories, user preferences, and via browsing history
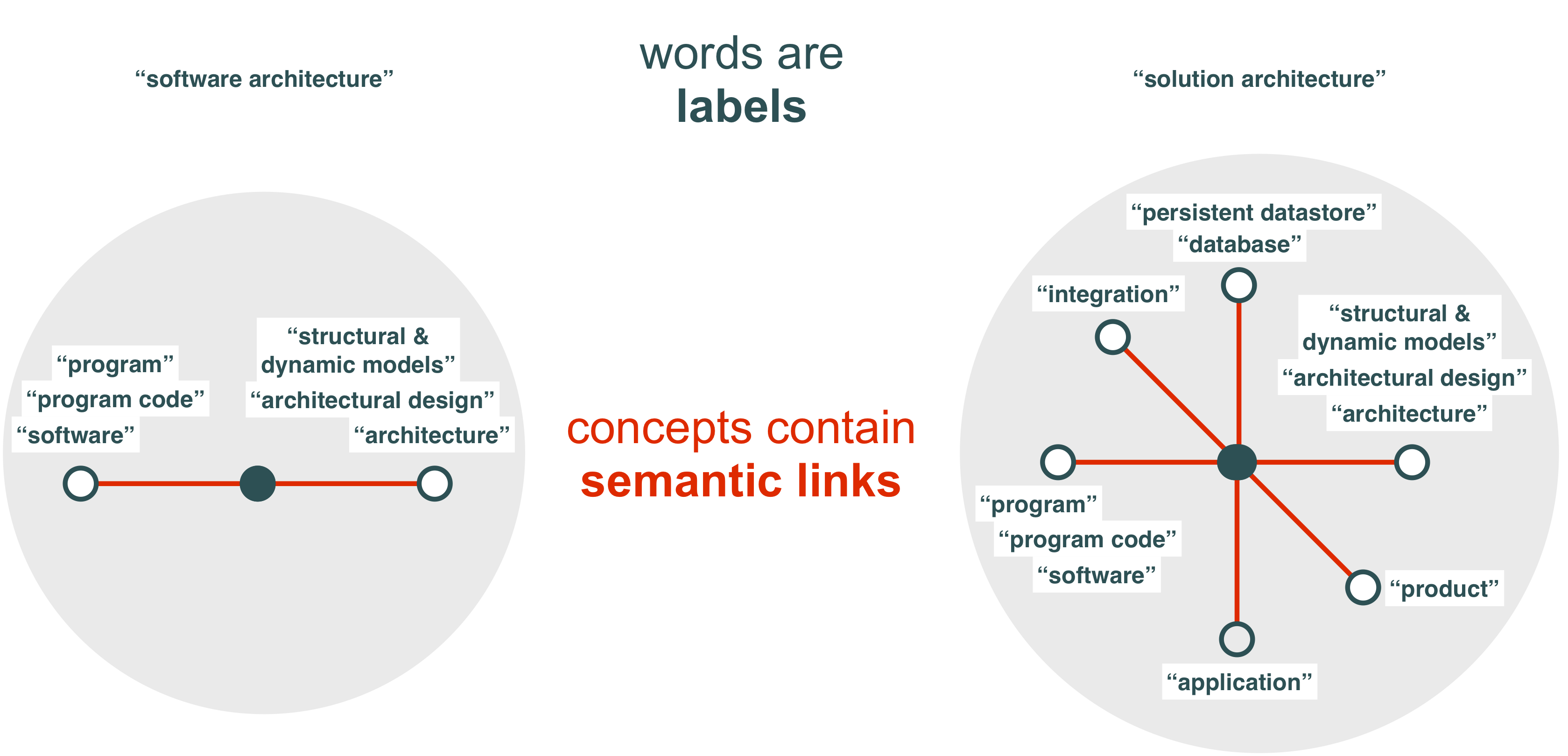
words vs concepts
Semantic search will only improve if and when Web browsers rely on explicit user guidance to translate words into concepts before executing a search request. Furthermore, to reduce search complexity, a formal notion of semantic equivalence is essential.

semantic equivalence
Lastly, the mapping between labels and semantics depends significantly on linguistic scope. For example the meaning of solution architecture in organisation A is typically different from the meaning of solution architecture in organisation B.

linguistic scope
If the glacial speed of innovation in mainstream programming languages and tools is any indication, the main use case of semantic search is going to remain:
User looks for a product with features x, y, and z
The other use cases mentioned above may have to wait for another 10 years.

How to refer a concept ?
For example in french, “mariage” means union between a man and a woman.
But french law decides “mariage” means union between 2 persons.
So the concept “union between a man and a woman” becomes a concept without label (word).
More, the gender theory says a man can be a woman and a woman can be a man.
So the concept “union between a man and a woman” is not correctly described by the sentence “union between a man and a woman”.
So a word or a set of words can’t describe a concept…