For humans it is not possible to reason about the Anthropocene entirely without human bias. The best we can do is to consciously use language that broadens our perspective to include all living agents within the biosphere.
Burning fossil fuels
The catastrophic bush fires in Australia offer a good illustration of how people collaborate when confronted with the kinds of disasters that global heating will increasingly inflict on our societies. On the one hand, from Love and respect shine though in a time of crisis (5 January 2020) :
The fires leave terrible destruction in their wake, but they also leave deeper human bonds…
You might imagine that, at a time like this, people would become selfish, trying to protect their own place; worried about how their own sheds and homes and stock will emerge.
I’ve seen little evidence of that. Instead, every moment seems to be spent worried about someone else.
When it comes to political clumsiness, the Prime Minister’s Hawaiian holiday was hard to top. But the Liberal Party advertisement released late yesterday, as dozens of communities faced horror bushfire conditions, came close.
The ad shows Scott Morrison in the field, taking charge (angry locals refusing to shake his hand are nowhere to be seen). Firefighters battle the flames with abundant support from Defence Force personnel and aerial assets. The Federal Government’s contributions are proudly listed in on-screen text. Uplifting background music instils confidence that this is a man with a plan.
There will no doubt be debate as to whether this is indeed a party political advertisement capitalising on the disaster, or simply an effort to disseminate information.
But when it walks like a duck and quacks like a duck …
The contrast between the mutual support that emerges within local communities and the behaviour of the most powerful person in the country is not surprising, but representative of a phenomenon that has been described as “elite panic”. From Disarm the lifeboats (4 January 2020) :
Disaster experts can predict how most people will react: Most will try to work together to save the most people possible. As Erik Auf Der Heide, a leading disaster expert with the Centers for Disease Control and Prevention, has written, “antisocial behaviors are uncommon in typical disaster situations.” I’ve observed this myself, in natural disasters in places as different as Haiti and Staten Island, for almost all people.
But there is a notable exception. The richest people on the ship are the least likely to cooperate. There is a formal term for this, based on a 2008 paper by the sociologists Caron Chess and Lee Clarke. It’s called “elite panic.” As Rebecca Solnit has written, “Elites tend to believe in a venal, selfish, and essentially monstrous version of human nature.” And as such, they believe that only “their power keeps the rest of us in line.” If the ship—or human society—is disrupted, they think, “our seething violence will rise to the surface.”
People are waking up to the fact that faith in leaders is what is likely to lead to the end of our species and countless other species. Translated from this article:
A society based on cunning, on people who deceive others
The “business” is hidden for the majority of people, but it is business of companies that have grown at an unprecedented speed. So you end up with a problem: you have a society based on cunning, on people who deceive others. With such a model of society, we should not be surprised at having become unable to solve the real problems. We are now disconnected from reality.
We do not deal properly with the issue of climate change. We do not deal properly with the issues of peace, war, immigration, food resources, water resources, public health, and all these important issues. We became incompetent because society as a whole began to focus on how to deceive and trick people.
– Jaron Lanier, VR technology pioneer, 2019
In the emerging social environment of disillusioned communities and citizens, you can neither buy trust nor investments that deliver a “return on capital”. Those who attempt it actually undermine their credibility and tie themselves to a sinking ship.
Oil was the engine of growth in the twentieth century, then for a little while, data was considered to be the new oil, and now, as the “externalities” of 100 years of oil based economics manifest in personal experiences, we can conclude that oil is the new data.
Burning capital
We are already much closer to a world without capital than capitalists would like us to believe. In many ways such a new world is much more desirable for most of us than the delusional world of infinite “growth” that we are still being sold.
In fact, investment capital has become a negative signal:
The more capital someone has, the less trustworthy they are.
A venture that depends on external investors is less trustworthy than a venture that does not depend on external investors.
Patents and other forms of proprietary intellectual property are increasingly recognised as tools for growing capital, which reduces the trustworthiness of all ventures that rely on proprietary intellectual property for generating profits for investors (see Telsa‘s attempt to remain credible).
People increasingly recognise philanthropy as attempts by capitalists to distract from the externalities caused by their investment activities and to artificially enhance their reputations, and indirectly to enhance the value of their investments.
The way forward will increasingly involve:
Negative interest rates, to provide capitalists with (a) a less-toxic tool for disposing of capital, (b) time to re-learn how to develop trust based relationships, and (c) integrate into new emerging social structures that operate on zero capital. Negative interest rates are already a reality today, and they will become more and more common.
The resulting web of interdependencies can simply be thought of as the web of life rather than “civilisation 2.0”. We must not again make the anthropocentric mistake of putting humans at the centre of the universe.
Related initiatives
The Aut Collab community welcomes all individuals and groups who fully appreciate the value of neurodiversity. Aut Collab acts as a hub for mutual support and encourages neurodivergent individuals to connect and establish inclusive non-hierarchical organisations. Over the last two decades it has become clear that autistic cognitive lenses are an essential element in all human societies, especially in the context of innovation and in terms of reducing spurious complexity in human culture. It is time to liberate autism from the pathology paradigm. Autistic people are often noted for their their honesty, their naivety, and their inability to be exploitative. The lack of self-promotional ability is typically at odds with cultural expectations.
The P2P Foundationis a non-profit organization and global network dedicated to advocacy and research of commons-oriented peer to peer (P2P) dynamics in society. P2P is an abbreviation of “peer to peer”, sometimes also described as “person to person” or “people to people”. P2P is a process or dynamic that can be found in many communities and movements self-organising around the co-creation of culture and knowledge. Well known general examples include the free/open source software movement; free culture; open hardware; and open access in education and science.
The Post Growth Instituteis an international organisation accelerating the world’s shift to a society that thrives within ecological limits. ‘Post-growth’ is a worldview that sees society operating better without the demand of constant economic growth. It proposes that widespread economic justice, social well-being and ecological regeneration are only possible when money inherently circulates through our economy. In all its forms, the dominant economic system – capitalism – is committed to economic growth. Ongoing economic growth threatens our survival as a species. Transitioning to a post-growth economy represents our best option in response to the threat of social and ecological collapse.
The Degrowth web portal is a learning resource on degrowth as a social movement and as a theory. By ‘degrowth’, we understand a form of society and economy which aims at the well-being of all and sustains the natural basis of life. To achieve degrowth, we need a fundamental transformation of our lives and an extensive cultural change. The current economic and social paradigm is ‘faster, higher, further’. It is built on and stimulates competition between all humans. This causes acceleration, stress and exclusion.You can find answers to the question “What is degrowth?”, search for audio, video and text materials in our library, learn about the current projects and the past and next international Conferences on Degrowth, or get involved in many different ways.
Globally, governments are still in the early stages of exploring a transition to new non-fossil fuel economies. Currently the global economy including agriculture, and horticulture are heavily dependent on fossil fuels, and there is a very high risk that political compromise will delay the end of outmoded practices. The integral role that fossil fuels play in the current global economy cannot be overstated, and any significant reduction in their role will result in a total remodelling of economic indicators. What is more, the close correlation of economic growth, and the implicit assumptions relating to positive GDP data, are seriously problematic when seeking to mitigate anthropogenic climate change and environmental degradation.
Given the urgency to reduce greenhouse gas emissions to limit self-reinforcing climate feedback loops, even a 2 or 3 year delay before embarking on a path of drastic emissions reductions may lead the climate into a territory where any attempts to limit the average temperature rise to 2°C, or less, become futile.
In order to mitigate the risk that humanity will not move fast enough to avoid social and environmental crises, we must prepare ourselves by concentrating on our ability to adapt, which in turn is dependent on our ability to explore a broad range of potential climate change scenarios and a broad range of possible mitigation pathways.
From a scientific perspective, based on the data available and the observable trends, actions to de-carbonise the economy which are framed with a 2050 deadline are inadequate. Firstly, the time frame is not aggressive enough to prevent potentially catastrophic levels of warming, and secondly, given the complexity of the climate there is also an urgent need for actions based on the precautionary principle.
Scientific uncertainty is not a justification for government to take a light regulatory approach when voters and their entire ecosystem face such existential moral hazard. In the same way that no one would allow their children to board an airplane if the risk of a deadly crash would be 10% (or even 0.1%), we should not have blind confidence in our collective ability to de-carbonise the global economy in time to prevent severe climate changes.
Adaptation actions must consider scenarios of at least 4-6°C of warming by 2100 and the likely consequences of such levels of warming in terms of threats such as:
sea level rise, ocean acidification, and the salination of freshwater aquifers,
impact on agriculture and food production,
the spread of diseases, and the human and animal health risk of temperature increases,
increases in extreme / catastrophic weather events,
limits to the ability of local communities to cope with these consequences.
Preparing for adaptation to severe climate change must seriously consider the risk of social collapse at local, regional, national, and even transnational levels. In a global economy, when a major climate-induced social collapse occurs, we can not assume smooth continued operation of local or global economic and financial systems. Furthermore any de-carbonisation initiatives that depend on concepts such as financialised emission trading schemes may turn out to be ineffective.
These risks underscore the need for a climate change modelling tool chain that assists domain experts from various disciplines, as well as policy designers, to systematically and with relative ease explore, and communicate a broad range of options to reduce the risk and to contain the impact.
At the moment, the way we respond and adapt to climate change impacts is not well coordinated or communicated. Many of the risks, impacts and actions to adapt are dealt with across a number of different legislative and regulatory regimes.
There are gaps in our information. We have some knowledge about the physical impact of sea-level rise on our coastlines and communities but we currently don’t know much about the impact that rising seas and temperatures will have on economic and ecological systems. We also do not know what the impact of ongoing extreme weather events would be on production in the primary sector. Together these impacts could seriously disrupt current geographical, geological and meteorological advantages enjoyed by certain economic sectors.
We do not fully understand the ecological interdependencies related to the acidification of the oceans and the potential collapse of the complex food chain dependent on phytoplankton, and the oxygenation of the seas and atmosphere. We do not know if we are approaching a tipping point in ocean temperatures brought about CO2 absorption and rising acidification. We do not fully understand the water cycle and how the eutrophication of oceans and the salination of waterways interact with freshwater aquifers, impacting water resources and land-based food capacity.
There is more work to do to understand the possible impacts on our health, biodiversity and culture beyond the traditional timescales projected by economists, statisticians and politicians. A new transdisciplinary approach to climate change mitigation is needed to take precautions against the worst impacts that could affect all aspects of human societies, both locally and globally.
Exploring climate change mitigation and adaptation
Economic assumptions are never neutral and this is especially true of GDP and growth expectations that can hide equity costs within pricing markets on 10, 50, and 100 year timescales. The assumptions made in any economic models must also be explicit about equity issues and the level of commitment to achieve specific equity targets.
An evidence-based approach must be based on known patterns of physical resource flows and resource demands, and on explicit assumptions about changes to these patterns due to the need for climate change mitigation, and will, therefore, promote well informed political debate.
Climate change mitigation and adaptation is a complex transdisciplinary challenge. Any potentially useful modelling tool chain must be able to take into account the following constraints and limitations:
The reality of human cognitive limits, including the limits of quantitative methods, the limits of qualitative methods, and the limits of language.
The influence of ideologies and cultural norms on human behaviour, in combination with cultural inertia.
Changes of government and potentially significant changes in climate change related policies every few years.
The growing likelihood of extreme weather events of new levels of severity and the effects on agricultural production, economic infrastructure, and human lives.
The potential failure to limit local and global temperature increase to 1.5ºC or 2ºC even within the next 20 years.
The potential breakdown of established economic ideology due to local and global climate disasters within the next 20 years.
The need to rapidly reduce the ecological and energy footprint of human civilisation, and the level of incompatibility of reduced resource consumption with the established economic ideology.
The human potential, creativity, and resilience that can be unlocked by trusted collaboration at human scale.
The potential need to replace established financial economic paradigm with a viable resource and waste based alternative on short notice, and the ability to iterate on economic paradigm in order to adapt to rapid climate change and to deal with acute ecological disasters.
A modelling and simulation tool chain that does not consider the above constraints and possibilities will be of very limited use for the exploration of climate change mitigation and adaptation pathways, and will not be able to assist policy designers and implementers.
The S23M team envisages a modelling framework and a tool chain design that assists modellers, policy designers, policy implementers, the public, and industry representatives from all economic sectors to incrementally learn from each other about the unfolding reality of climate change, the changing social and economic support needs of local communities, and the need to invest in new types of economic infrastructure that are of strategic importance for our collective ability to adapt to climate change.
Uncertainties around climate and social norms
Just as the world wars wreaked havoc on society and the environment, the climate crisis creates a similar disjuncture with the past. The future of human societies is going to be dominated by two broad trends that are already visible now.
Increasing numbers of climate related increasingly severe weather events (severe rainfalls and flooding, cyclones and coastal erosion, heat waves, droughts, etc.), and downstream effects on agricultural production and ecosystem functions. The inherent level of uncertainty around the rate at which global temperatures will continue to rise and the rates at which national economies will be able to rapidly reduce green house gas emissions leads to a corresponding level of uncertainty around the frequency and magnitude of future severe weather events.
Increasingly levels of climate change related anxiety in the population, which may rise to the surface following severe weather events or disasters, leading to rapid shifts in social norms (financial economic growth is no longer the main or only target of economic policy, etc.). Further changes in social norms are inevitable, but the timing is impossible to predict – leading to significant uncertainty about future climate change mitigation related goals and legislation.
This means that classical financial economic modelling techniques and metrics such as GDP are no longer useful for assessing the impact of climate change and for assessing the cost of climate change mitigation actions. Whilst we can’t predict the future, we do know that the future will not be a continuation of historic economic trends, and it may also not be influenceable in any adequate way via classical economic tools such as interest rates, tax rates (carbon tax, etc.) and market mechanisms (emissions trading schemes, etc.).
Instead, going forward, national and local governments are well advised to rely on the development of agent based models using the resources, events, and agents (REA) paradigm to combine:
available physical climate models,
available scientific data about local bioregions and microclimates,
available data on historic and current regional economic activities categorised by sectors and industries, measured in physical quantities of resources (kg) and goods (quantities of specific categories of goods),
with the tacit knowledge of subject matter experts and local practitioners in relevant disciplines.
REA models of resource flows and economic activity can be developed and validated incrementally by groups of subject matter experts, both at the macro level as well as at the regional (meso) level, and they can serve as a formal foundation for agent based simulations of economic activities in combination with a range of very different climate change and climate change mitigation scenarios.
This approach allows modellers to run simulations that take a precautionary approach in relation to the uncertainties around severe weather events and around shifts in social norms outlined above. The REA data resulting from the simulations can be translated from physical metrics into local monetary metrics based on the different assumptions about social norms and economic rules that underpin the various simulation runs.
The resulting portfolio of possible climate change mitigation scenarios, including formal representations of all the assumptions about future social norms and economic rules, provide policy designers with a tool box for educating politicians and the public about the available options and associated investments in specific climate change mitigation and adaptation activities.
A growing number of researchers and practitioners are working on resource based accounting methods, and some are already working on the development of regenerative economic ecosystems at a bioregional level that are specifically designed for resilience against climate change.
An economic ideology independent reasoning framework
Preparation for potentially severe climate change and economic disruption is only possible with the help of economic and ecological modelling and simulation tools that don’t make implicit (hard-coded) assumptions about the way economic systems work. In this context financial economic modelling techniques are at best inadequate if not useless.
Over a period of 30 years and longer significant shifts in economic ideology are inevitable in order to adapt effectively to changes in climate, to the effects of increasingly extreme weather events, and to related social challenges.
Governments need suitable multi-dimensional economic and ecological modelling tools for reasoning about human collaboration and resource flows at various levels of scale that can be configured on demand, to reflect emergent economic and ecological practices that may differ radically from current “best practice”.
The MODA + MODE human lens provides thirteen categories that are invariant across cultures, space, and time – it provides an economic ideology independent reasoning framework for transdisciplinary collaboration. The human lens allows us to make sense of the world and the natural environment from a human perspective, to evolve our value systems, and to structure and adapt human endeavours accordingly.
The human lens is a meta language that can be used to design multi-paradigm and multi-dimensional modelling and simulation tools for resource flows between economic agents as well as resource flows between ecological systems and economic systems.
The human lens is comprised of:
The system lens, to support the formalisation and visual representation of knowledge and resource flows in complex socio-technological systems based the three categories of resources, events, and agents (the REA paradigm, an accounting model developed by E.W. McCarthy in 1982 for representing activities in economic ecosystems). The system lens can be applied at all levels of organisational scale, resulting in fractal representations that reflect the available level of tacit knowledge about the modelled systems.
The semantic lens, to support the formalisation and visual representation of values and economic motivations of the agents identified in the systems lens. The semantic lens provides a configuration framework for articulating ethical, cultural, and economic value systems as well as a reasoning framework for evaluating socio-technological system design scenarios and research objectives with the help of the five categories of social, designed, symbolic, organic, and critical.
The logistic lens, to support the formalisation and visual representation of value creating activities and heuristics within socio-technological systems. The logistic lens provides five categories for describing value creating activities: grow (referring to the production of food and energy), make (referring to the design, engineering, and construction of systems), sustain (referring to the maintenance of production and system quality attributes), move (referring to the transportation of resources and flows of information and knowledge), and play (referring to creative experimentation and other social activities). The logistic lens can be used to model and understand feedback loops across levels of scale (from individuals, to teams, organisations, and economic ecosystems) and between agents (companies, regulatory bodies, local communities, research institutions, educational institutions, citizens, and governance institutions). The categories of the logistic lens assist in the identification of suitable quantitative metrics for evaluating performance against the value system articulated via a configuration of the semantic lens.
All 13 human lens concepts reflect foundational aspects of human cognition and the human capacity for symbolic thought within an ecological context, and are found in all cultures under various labels.
The human lens concepts are recognisable in all historic human cultures, and they will continue to be relevant in another 1,000 years – this is what is meant by “independent of economic ideology”. This is important because language is always a contentious topic in a transdisciplinary context, since each discipline uses a different language. The human lens can be used to model all aspects of the relationships between economic agents and all aspects of collaboration within economic agents.
Furthermore the fractal characteristic of the human lens allows the representation of groups of collaborating economic agents and the representation of abstract relationships between such groups.
The grow category in the logistic lens can be used to instantiate specific subcategories in the land use sector for forestry, horticulture, dairy farming etc. Additionally the base categories of the logistic lens provide a framework for the transport (move, referring to the transportation of resources and flows of information and knowledge), electricity (grow, referring to the production of food and energy), and industry sectors (make, referring to the design, engineering, and construction of systems). The base categories in the logistic lens are designed to encourage zero waste system designs, the sustain category (referring to the maintenance of production and system quality attributes) can be used to instantiate models that focus on maintenance, repair, and decomposition for reuse of economic resources and that explicitly indicate, and as needed, quantify, residual waste streams. Finally the play category (referring to creative experimentation and other social activities) can be used to instantiate models that focus on important cultural practices, on the education sector and on research and innovation).
A distinguishing feature of the MODA + MODE meta paradigm is that it allows for consistent formalisation of discipline specific paradigms and local domain specific languages, such that domain experts are able to continue to use their preferred paradigms and terminologies.
Agent based economic and ecological models can be created and populated with available data and assumptions (scenarios) about economic sectors and ecological practices at various levels of scale in time and space, and these models can then be used to:
Visualise qualitative and quantitative economic dependencies and resource flows, including but not limited to links from sectoral models to thoroughly understand the interactions between the energy and land use sectors.
Run agent based simulations of activities in the economic and ecological spheres to explore different scenarios and their implications.
Generate corresponding multi-dimensional economic and ecological accounting tools that can be used to coordinate human economic activities.
All the categories and semantic links between categories and instances in the example model above are easily made available for processing by software tools. The example shows concrete resources (orange), events and activities (blue), as well as agents (green) and their motivations (red).
The semantic lens allows us to create explicit models of different worldviews and paradigms, so that all relevant value systems and cultural differences are not only acknowledged, but become an integral part of the language used to describe economic activities and their purpose.
Visual semantic models can be used to trace motivations back over several levels to specific cultural or individual values. In this way assumptions and worldviews are made explicit, and cultural context can be integrated into economic and logistical models to any desired level of detail. In particular local knowledge and values can be reflected in the configuration of economic models, alongside scientific knowledge about the natural world and the climate, facilitating the co-design of mitigation and adaptation activities in collaboration with local populations.
The human lens in combination with an inclusive consultative and transdisciplinary approach provides results that are traceable to underlying datasets and economic assumptions and that can assist policy designers in answering important questions under a range of different climate change scenarios:
What emissions reductions are technically and economically feasible when factoring in the interactions between sectors and economy-wide constraints?
What are the economic consequences of different levels of emissions reductions, different types of policy interventions, and different scenarios of technological and economic change?
What distributional impact could emissions budgets or emissions policies have on different sectors, regions, generations and socio-economic groups?
What impact will domestic emissions policies have on the ability to meet global emission reduction targets?
What impact will overseas markets and policies have on local emissions, production and trade?
In an increasingly unpredictable world that can easily be disrupted by severe climate related events, a modelling and simulation tool as described above may be essential for preventing or limiting social collapse, allowing local populations to rapidly explore the viability of new sequences of adaptive actions, before jointly agreeing on and committing to specific (and potentially radical) changes in economic and ecological practices.
Modelling and simulation tool chain design
A suitable modelling tool that supports the human lens and representations of both quantitative and qualitative / semantic models can be implemented with the help of category theory (which is the abstract “systems integration language of mathematics”) and with denotational semantics (to map formal models to concrete computational platforms and data storage technologies) .
A basic implementation of the human lens for qualitative modelling is achievable with a Unified Modeling Language (UML) modelling tool and via the configuration of a UML Profile that includes suitable UML stereotype definitions for the thirteen human lens concepts.
An even more basic implementation is afforded by markers and a whiteboard or by pencil and paper, but then of course the models can’t be used to drive automation and agent based simulation tools.
The full potential of the human lens can be harnessed with a tool like S23M’s Open Source Cell Platform that provides an unlimited multi-level instantiation capability and that enforces strict semantics for agent based modelling.
The Cell Platform provides a clean formalisation based on the axioms of category theory that is recursively bootstrapped from the structure of an ordered pair, without any spurious complexity induced by the underlying implementation technology (the Java Virtual Machine – JVM). Additionally the Cell Platform:
Uses denotational semantics (a unique machine readable semantic identity for each concept) to completely separate the concern of naming from the concern of semantic modelling, allowing each agent to introduce preferred labels and symbols.
Enables communication and collaboration between agents based on artefacts (information resources), and events which equates to native support for the REA paradigm.
Provides an API in the language of category theory that exposes the recursive construction of models, and that hence allows extensions, restrictions, and other variations of all concepts.
Allows agents to make selected models discoverable, to make selected models visible to other agents, and to declare semantic equivalences between concepts in different models that are then recognisable by the reasoning engine within the Cell Platform.
Provides support for 4-state information quality logic (true, false, unknown, not applicable) to allow agents to easily process incomplete data and any structures they may find in the models from other agents – without resulting in ambiguous semantics.
Supports logic and reasoning entirely within the abstract language of category theory, since semantic equivalences are defined between semantic identities rather than between human assigned labels.
The S23M team envisages a transdisciplinary modelling and simulation framework for climate change mitigation and adaptation scenarios that allows domain experts from various disciplines to contribute models of sectors of the economy and aspects of ecosystems within their preferred paradigm and in their preferred terminology into a modelling tool chain that includes explicit support for:
Managing and enforcing the limits of applicability of specific models.
Recording all assumptions that are associated with a model or specific scenario in a form that is accessible to software tools.
Reviewing and flagging inconsistencies between the assumptions associated with different models or aspects of the domain of interest.
Formal version and variant management for all models, data sets, and sets of assumptions that are associated with specific climate change mitigation pathways.
Formal traceability between sets of assumptions, and related models and results of agent based simulations.
The human lens meta language, to enable
Specification of suitable qualitative and quantitative goals in suitable metrics, including metrics for the quantification of resource flows and green house gas emissions in physical units, and chemical types/properties.
Modelling cultural norms and expected or potential shifts in cultural norms.
Modelling the economic ideology and expected or potential shifts in economic ideology.
Modelling cross-sector dependencies and resource flows at different levels of scale, including desirable shifts in such dependencies.
Modelling of concrete economic agents that are of strategic economic importance, including the dependencies between these agents – to provide a foundation for performing dynamic agent based simulations under a range of different assumptions.
Semantic integration between different aspect and sector models, including the specification of any required transformations of input and output data structures.
As needed, translating the results of agent based simulations back into traditional financial economic metrics, to assist experimental and iterative development of suitable policies and regulatory frameworks for achieving desired national and regional level outcomes.
The purpose of such a modelling and simulation tool chain is to allow rapid exploration and iterative refinement of different mitigation and adaptation scenarios. Policy makers and the wider population need to see “first hand” (as far as that is possible) that busyness as usual and related measures to “decarbonise” the economy via traditional economic tools within the framework of financial economics are inadequate for dealing with the challenge presented by the climate crisis.
Organisations are best thought of as cultural organisms. Groups of organisations with compatible operating models can be thought of as a cultural species. The human genusis the genus that includes all cultural species. Since the emergence of humans around two million years ago, evolution has produced many different cultural species within the human genus.
It is becoming clear (Dunbar) that only human scale organisations are understandable for individual humans and have the potential to provide psychologically safe and healthy environments for humans. A careful analysis of human history demonstrates that super-human scale organisations are inherently unsafe for individual humans, and that completely atomised societies are inconceivable, as they are apparently incompatible with human social needs.
Viewed from within the context of human evolution, the emergence of “civilised” (super-human scale) societies and the construction of empires is a social cancer that feeds on cultural species and has resulted in the destruction of cultural species and in a severe reduction in the number of healthy cultural species. Based on this understanding we can conclude that the human genus has been declining in adaptive fitness since the dawn of “civilisation” around 10,000 years ago.
The NeurodiVenture operating model is the social DNA of an emergent cultural species that has developed an immune system that enables it to survive and even thrive in three complementary contexts:
within super-human scale societies afflicted by terminal cancer
within social environments that contain a growing number of NeurodiVentures
within social environments that contain other human scale cultural species within the human genus
The minimalistic aspect of the NeurodiVenture operating model supports a huge diversity between cultural organisms and overall equips the NeurodiVenture cultural species with a level of resilience that differs markedly from the brittleness and pathological cultural inertia that characterises super-human scale societies.
The main difference between modern emergent human scale cultural species and prehistoric human scale cultural species lies in the language systems and communication technologies that are being used to coordinate activities and to record and transmit knowledge within cultural organisms, between cultural organisms, and between cultural species.
The main commonality between prehistoric societies and modern human scale cultural species is the critical importance of knowledge for survival, and a cultural appreciation for the value of knowledge and the value of trust based collaboration at eye level both within cultural organisms and between cultural organisms.
The main difference between all human scale cultural species and super-human scale “civilised” societies lies in the devaluation of knowledge and reliance on anonymous transactions and abstract monetary metrics, and in a corresponding devaluation of trust based collaboration at eye level.
The end of capital
Peter Thiel and Eric Weinstein, the manager of Thiel Capital, are two people who are not afraid to share their thoughts. It is interesting to see how they can spend 3 hours framing their quite astute observations on human society entirely within the box of capitalism and “meritocracy”, and how this frame prevents them from reaching deeper insights about human limitations and human creativity.
Human scale does not exist in Peter Thiel’s world. Instead Peter and Eric attempt to explain everything in terms of individuals, individual merit, organisations, growth, and progress in science and technology (without any attempt to delineate the boundary between science and technology). In the dialogue referenced above they both go to great lengths to complain about the extent to which virtually all organisations have become sociopathic, but they don’t realise how insisting on an individual talent or merit scale and a universal metric (capital) is the perfect breeding ground for the corruption that they complain about. It is as if they complain about all the hierarchical structures that differ from an envisaged ideal and universal “meritocratic” hierarchy that is defined by criteria stipulated by Peter Thiel & Co.
Whilst long, the above dialogue is highly recommended for all those who are still convinced that capital must be part of the furniture of all technologically advanced societies.
The dialogue between Peter Thiel and Eric Weinstein illustrates that some of the most fundamentalist capitalists question whether there has been any substantial technological progress at all over the last 40 years.
I concur with the diagnosis of stagnation in many areas of knowledge, but from my perspective economic growth and capital are counter-productive and dangerously misleading metrics going forward. Capital is a legacy technology that will need to be phased out if humans want to have any chance at avoiding the self-destructive pattern of civilisation building and collapse that has characterised the last 10,000 years.
We need to be clear about the remaining life expectancy of capital as a relevant metric at super-human scale. In the short term human scale employee owned companies and cooperatives can opportunistically work within a capital-driven world, but over the next 30 to 100 years the role of capital will likely be reduced to zero – it’s going to be an obsolete legacy technology just like the telegraph is a legacy technology today.
The interest in human scale employee owned companies is growing globally, as such companies are capable of thriving in a capitalist environment due to their collaborative advantage, but they are also ideally positioned to thrive in other emergent environments that are less toxic for the planet.
Domain-specific metrics that measure physical properties are going to become much more important than abstract metrics at super-human scale. Abstract metrics are only safe (low risk of corruption) for local resource distribution at human scale.
From economics to the web of life
If we want to avoid repeating the mistakes of human “civilisations”, the rules for coordinating at super-human scale will have to allow for and encourage a rich diversity of human scale organisations.
In a human scale social world, apart from the self-imposed constraint of human scale, there is no universally dominant organisational paradigm. In a super-human scale social world that is increasingly toxic for individual mental and physical health, a diversity of human scale paradigms will eventually crowd out the super-human [global/national/mega-city] scale paradigm that dominates today.
The resulting web of interdependencies can simply be thought of as the web of life rather than “civilisation 2.0”. We must not to again make the anthropocentric mistake of putting humans at the centre of the universe.
At human scale cultural evolution operates as follows:
On the relationships between cultural organisms and on the links between cultural species.
Relationships can strengthen or weaken, new relationships can be established, and established relationships can be be discontinued or put on hold. At any point in time the relationship between two cultural organisms can be described in terms of the binary trust based relationships between specific individuals. The duration of relationships can last from months through to many decades and possibly longer.
By individuals who may chose to leave or join a cultural organism, travelling along the link to a related cultural organism of the same cultural species.
From an individual’s perspective such a change in organisational membership is minor. The individual retains their individual competency network, and the change can be described as the emergence of new regular collaboration patterns within the individual’s competency network and the weakening of earlier regular collaboration patterns – it is very much comparable to a change in team membership within a cultural organism. From the perspective of the cultural organism involved the change reflects a desirable change or optimisation in the interaction patterns across the organisational boundary that is well received by most of the individuals involved – a new team is welcoming a new member and another team in the related cultural organism will reconfigure accordingly. The duration of organisational membership may last from months through to many decades or an entire lifetime.
By individuals who may chose to leave or join a cultural organism, travelling along the link to a related cultural organism of a different cultural species.
Again, from an individual’s perspective such a change in organisational membership is relatively minor. The individual retains their individual competency network, and the change can be described as the emergence of new regular collaboration patterns within the individual’s competency network and the weakening of earlier regular collaboration patterns – but in this case the individual will need to integrate into a new culture. Often such a change will be motivated by the neurological disposition and specific talents and interests of the individual, who may have discovered via personal interactions across the organisational boundary that she or he would be more comfortable in the target culture. From the perspective of the cultural organisms involved the change reflects an opportunity for cultural cross pollination across the organisational boundary that may improve the collaboration patterns across the cultural species boundary. The average number of shifts between cultural species will be zero across a typical human life, and the number of shifts will likely be one or more for many neurodivergent individuals, who will feel compelled to search for a cultural environment that is well suited for their particular needs and cognitive lens.
By individuals who may chose to leave or join an unrelated cultural organism of the same cultural species.
This scenario represents a mixture of scenarios 1 and 2 above. The individual will have had to establish a relationship to someone in a different cultural organism, and hence the change represents an emergent relationship between two cultural organisms. The duration of the new relationship may last from months through to many decades or possibly longer.
By individuals who may chose to leave or join an unrelated cultural organism of a different cultural species.
This scenario represents a mixture of scenarios 1 and 3 above. The individual will have had to establish a relationship to someone in a different cultural organism of a different cultural species, and hence the change represents an emergent relationship between two cultural organisms. This scenario may be fairly rare, as it involves establishing a cross-species relationship between cultural organisms that had no prior contact. The resulting relationship may start off very much as an experiment or exploration with outcomes that are difficult to predict. It may result in the individual having found a more accommodating target culture in terms of their neurological disposition, and the link between the two cultural organism may only be short lived.
At human scale individuals enjoy a significant level of agency, with the ability to remain in a given cultural organism as long as they desire, and to move to a different cultural organism when this is aligned with individual neurological dispositions, talents and interests. All atomic changes in relationships and memberships leave an individual’s existing competency network intact and at all times the individual is part of a cultural organism that provides a livelihood for the individual.
Similarly cultural organisms enjoy a significant level of agency at human scale, as all individuals in the organism may create new relationships across the organisational boundary as needed, for example coordinated via a simple advice process and as needed via deliberation in Open Space. Cultural organisms that don’t operate an egalitarian culture will quickly find themselves at a disadvantage, as they are held back by cultural inertia. At some point their members may decide to join more egalitarian cultural organisms.
Agency at super-human scale is an emergent phenomenon that can not be attributed to any specific individual. Living within “civilisation” we are surrounded by super-human scale structures and it is difficult for most people to imagine collaboration at human scale without being embedded in some bigger hierarchical system.
Each human scale cultural organism represents an aggregation of agency that manifests itself in individual relationships and interactions across the organisational boundary. In a non-hierarchical cultural organism there is no single individual that “leads”, instead external representation and decision making of the cultural organism is distributed across all the individual relationships between the cultural organism and other cultural organisms.
Large sets of collaborating cultural organisms (some of which may be given labels for the purpose of communication and reasoning about them) without any hierarchical command and control are unattractive for sociopathic empire builders. The lack of hierarchical structure is a key element of the immune system against organisational cancer.
Visualising human collaboration
Human spoken and written languages are useful, but we need better [non-linear] languages systems for reasoning about collaboration beyond human scale.
The human lens is a meta language that can be used to construct better language systems.
The human lens can be used to model all aspects of the relationships between cultural organisms and all aspects of the relationships within cultural organisms. Furthermore the fractal characteristic of the human lens also allows the representation of groups of collaborating cultural organisms and the representation of abstract relationships between such groups.
When such structural and relational abstractions are agreed between cultural organisms, the result is a formal abstract framework that defines agreed collaboration patterns. Abstract collaboration frameworks can be worked out collaboratively in Open Space, and as needed choices between alternative approaches to specific details can be made via a democratic process involving all members from all cultural organisms that are involved. The focus of democratic governance at super-human scale completely shifts away from the selection of “leaders” to the selection of suitable collaboration frameworks for ecosystems of collaborating cultural organisms.
Below is a high level overview of valuable resource flows represented with the help of the logistic lens within the human lens.
The represented abstract categories can be refined as needed in corresponding models of concrete instances of resources and agents.
In a simplistic capitalistic world such complex multi-dimensional collaborations patterns tend to be linearised into legal agreements that are dominated by a simplistic one-dimensional metric – capital.
We can use the same visual notation as above to create models of dysfunctional feedback loops (or negative “externalities” in the language of economics).
In a networked digital world agreed collaboration patterns can be formalised with the human lens, making use of physical metrics to quantify flows of resources and energy, without any need to resort to abstract metrics. The technologies for resource based accounting exist today.
Below is an example of a high level commonality and variability analysis of the agriculture sector represented using the categories of resources, events, and agents (the REA paradigm).
The visualised categories are the commonalities that characterise the sector. Corresponding representations of concrete instances of these categories with the help of the logistic lens and connections between these instances lead to models of value producing processes and activities that can be refined to any desirable level of detail.
Where we stand today
The only thing that stands in the way of phasing out the legacy technology of capital is cultural inertia and the ongoing indoctrination in outdated economic ideology delivered by our education systems.
In the coming decades metrics that measure physical properties (energy use, resource use, waste metrics) are going to become much more important than abstract monetary metrics. We will increasingly discover that abstract metrics (“currencies”) are only safe to use for resource distribution at a local human scale, and that at super-human scale the risk of corruption of abstract metrics simply becomes too large to be acceptable.
To comprehend where we currently stand it is useful to conduct a little thought experiment. What would happen if the global financial system collapses or if all the technology infrastructure underpinning the financial system collapses?
If everybody just continued with all their daily activities as usual as far as possible, irrespective of their ability to be paid or to pay, the following would happen:
In the technologically “less advanced” parts of the world the impact would be minimal. People would continue to go about their lives, collaborate along the lines of trusted relationships, and as required come up with alternative no/low tech accounting systems at human scale.
In the technologically “advanced” parts of the world the impact would be much larger. Many technological systems and complex automated supply chains that assume working connections to banking systems would be disrupted. Above and beyond the inability to purchase physical goods online, people would quickly run out of credit tokens on their phones and on public transport, preventing them from using such services. In general, all technologies that rely on embedded links to banking systems would become disabled, whilst all technologies without such links remain unaffected. People could continue to visit retail shops and pick up goods or deliver supplies – and just as in the technologically less advanced parts of the world people will likely quickly come up with low tech accounting systems at human scale.
The overall result of using alternative low tech local accounting systems would be a much reduced ability to rapidly shift abstract credit tokens around the world.
The main people who would get concerned would be all those who used to be able “to make a living” from speculation, from rent seeking, and from shifting abstract tokens around the world. Those same people will likely not have access to any of the trusted relationships at human scale that are essential for surviving in a non-financialised world. Similarly many of the people who used to have “second and third level” bullshit jobs (all those people in jobs involved in operating the technology that supports the financial system) may discover that they lack useful trusted relationships at human scale.
In a world where many global supply chains for physical goods are disrupted, and where technological failures refocus collaboration on local trusted relationships at human scale, resources and goods would flow at slower rates, and the flows that continue to take place would largely be local, focused on the absolute necessities of life. In some geographies food shortages would quickly become extreme, and the overall reduction in long distance transportation would significantly reduce energy consumption.
Interestingly renewable energy sources and connected electricity distribution networks and connected customers would only be disrupted in locations where they are deeply entangled with banking systems.
The outlined scenarios could very quickly result in civil unrest, especially in the “advanced” parts of the world that are further removed from trust based collaboration at human scale, but this observation can in no way be taken as a “proof” that a world without capital is inconceivable:
Dismissing a world without capital because we personally have never experienced world without global money is simply a case of ignorance and lack of imagination fuelled by fear of the unknown.
In prehistoric times humans survived and increasingly thrived without money for many hundred thousand years. People’s life expectancy may have been shorter than today, but prehistoric humans where highly capable in transmitting complex knowledge over many generations, allowing them to adapt to many different climate zones and to a huge range of different local ecological contexts.
A small number of technologically “backward” societies still share more characteristics with prehistoric cultures than with the WEIRD (Western Educated Industrialised Rich Democratic) cultures that dominate today.
With relatively minor adaptations many of the technologies we use today could be disconnected from the global financial system and could resume operations in a post-capital world. The magnitude of the changes required are in many ways comparable to the magnitude of the changes to remove Y2K limitations from our software systems – not trivial but far from impossible, and perfectly achievable within a few years. As part of this transformation our technologies could be wired up to resource based accounting technologies that track flows of resources and goods purely in terms of physical metrics. The result would be a global logistics infrastructure capable of tracking resource flows without the translating (liquefying) everything into an abstract 1-dimensional metric of capital that instantaneously disappears through conceptual wormholes to facilitate universal fungibility for everything under the sun – everything and everyone is for sale.
Some of the effects outlined above such as a reduction in global resource flows, a refocus on local flows of resources, and a reduction in energy consumption would be highly desirable in terms of reducing greenhouse gas emissions and a rapid transition to a zero carbon economy. A transition towards resource based accounting as outlined above would allow us to re-enable global resource flows under a completely new regime of governance: we would be able to plan and budget in terms of resource needs and we would be able to very easily monitor agreed limits of energy and resource consumption in raw physical units without any distortions.
Considering all of the above, we can conclude that we are already much closer to a world without capital than capitalists would like us to believe. In many ways such a new world is much more desirable for most of us than the delusional world of infinite “growth” that we are still being sold.
The title of this post is the title of a book project I am working on, to provide organisations with a useful sense of direction, giving them the option to snap out of busyness as usual mode when they are ready. Whether this then happens in a timely manner may vary from case to case. It is not something that anyone has much control over.
As the title suggests, the book is about collaboration, about scale, and about humans, about beauty, and about limits. It has been written from my perspective as an autistic anthropologist by birth and a knowledge archaeologist by autodidactic training.
I attempt to address the challenges of ethical value creation in the Anthropocene. There is no shortage of optimistic books that celebrate human achievements and there is also no shortage of pessimistic books that proclaim the end of the human species. In contrast I approach the Anthropocene from the fringe of human society, from the perspective of someone who does not relate to abstract human group identities.
Evolutionary biologist David Sloan Wilson observes that small groups are the organisms within human society – in contrast to individuals, corporations, and nation states. The implications for our “civilisation” are profound. It is time to curate and share the lessons from autistic people, and help others create good company by pumping value from a dying ideological system into an emerging world.
Since the very beginning civilisation has always been more about a myth of progress than about anything that benefits local communities and families. – except perhaps for the benefit of not being killed as easily by a neighbouring horde of more or less civilised people. Once the history of civilisation is understood as series of progress myths, where each civilisation looks towards earlier or competing civilisations with a yardstick that is tailored to prove that its own myths and achievements are clearly superior to anything that came before, it is possible to identify the loose ends and the work-arounds of civilisation that are usually presented as progress.
The result is a historical narrative that makes for slightly less depressing reading than 10,000 years of conflict and wars. Instead, human history can be understood as a series of learning experiences that present us with the option to break out of the tired, old, and increasingly destructive pattern once it has been recognised. Whether our current global civilisation chooses to complete the familiar pattern of growth and collapse in the usual manner is a question that is up to all of us.
Regardless of what route we choose, on this planet no one is in control. The force of life is distributed and decentralised, and it might be a good idea to organise accordingly.
To understand why beauty, human scale, collaboration, and limits are essential for human sanity, we only need to look at the ugly reality of super-human scale institutions that currently surround us.
For concrete examples of making and taking in the global economy look no further than the wheeling and dealing that Vandana Shiva’s examines in her work. She makes astute observations on the role that Microsoft and other global technology companies play in rolling out intensive industrial agriculture to all corners of the planet.
Beyond the tactic of economic arm-twisting global corporations have perfected the art of accounting, shifting 40% of their profits ($600 billion annually) into tax havens with tax rates from 0% to less than 10%. Governments that represent their people rather than corporate interests would legislate against this practice – but they don’t.
Here is an excellent paper by A. Pluchino. A. E. Biondo, and A. Rapisarda on the intelligence of the economic game and the logic of capital, not even considering the effects of psychopathic social gaming. Synopsis:
On random factors that influence “social success”
… there is nowadays an ever greater evidence about the fundamental role of chance, luck or, more in general, random factors, in determining successes or failures in our personal and professional lives. In particular, it has been shown that scientists have the same chance along their career of publishing their biggest hit; that those with earlier surname initials are significantly more likely to receive tenure at top departments; that one’s position in an alphabetically sorted list may be important in determining access to over-subscribed public services; that middle name initials enhance evaluations of intellectual performance; that people with easy-to-pronounce names are judged more positively than those with difficult-to-pronounce names; that individuals with noble-sounding surnames are found to work more often as managers than as employees; that females with masculine monikers are more successful in legal careers; that roughly half of the variance in incomes across persons worldwide is explained only by their country of residence and by the income distribution within that country; that the probability of becoming a CEO is strongly influenced by your name or by your month of birth; and that even the probability of developing a cancer, maybe cutting a brilliant career, is mainly due to simple bad luck.
… On the randomness of the distribution of rewards when the logic of capital is applied
In particular, the most successful individual, with Cmax = 2560, has a talent T = 0:61, only slightly greater than the mean value mT = 0:6, while the most talented one (Tmax = 0:89) has a capital/success lower than 1 unit (C = 0:625). As we will see more in detail in the next subsection, such a result is not a special case, but it is rather the rule for this kind of system: the maximum success never coincides with the maximum talent, and vice-versa. Moreover, such a misalignment between success and talent is disproportionate and highly nonlinear. In fact, the average capital of all people with talent T > T is C 20: in other words, the capital/success of the most successful individual, who is moderately gifted, is 128 times greater than the average capital/success of people who are more talented than him. We can conclude that, if there is not an exceptional talent behind the enormous success of some people, another factor is probably at work. Our simulation clearly shows that such a factor is just pure luck.
Meanwhile, while society is stuck in a broken system, what is the best way of allocating R&D funding?
… The European Research Council has recently given to the biochemist Ohid Yaqub a 1:7 million US dollars grant to quantify the role of serendipity in science. Yaqub found that it is possible to classify serendipity into four basic types and that there may be important factors affecting its occurrence. His conclusions seem to agree with the believing that the commonly adopted – apparently meritocratic – strategies, which pursuit excellence and drive out diversity, seem destined to be loosing and inefficient. The reason is that they cut out a priori researches that initially appear less promising but that, thanks also to serendipity, could be extremely innovative a posteriori.
… if the goal is to reward the most talented persons (thus increasing their final level of success), it is much more convenient to distribute periodically (even small) equal amounts of capital to all individuals rather than to give a greater capital only to a small percentage of them, selected through their level of success – already reached – at the moment of the distribution. On one hand, the histogram shows that the “egalitarian” criterion, which assigns 1 unit of capital every 5 years to all the individuals is the most efficient way to distributed funds,
… The model shows the importance, very frequently underestimated, of lucky events in determining the level of individual success. Since rewards and resources are usually given to those that have already reached a high level of success, mistakenly considered as a measure of competence/talent, this result is even a more harmful disincentive, causing a lack of opportunities for the most talented ones. Our results are a warning against the risks of what we call the “naive meritocracy” which, underestimating the role of randomness among the determinants of success, often fail to give honors and rewards to the most competent people.
Robert Reich does a good job of highlighting the systemic dysfunction, but I cringe when I hear the undercurrent of the American Dream of “getting ahead” by working hard and the related myth that capitalism can be fixed by appropriate levels of regulation and democratic oversight. It seems no one dares to tell the truth to US audiences.
Critical social scientists regularly point out that the entire discipline of psychology is best understood as the study of human behaviour in WEIRD (Western Educated Industrialised Rich Democratic) cultures. Its identical twin is the discipline of marketing. The cultural bias is extreme. Here is just one example of the flaky foundations and of the bias. I have started to extend WEIRD to WEIRDT : Western Educated Industrialised Rich Democratic Theatre. Everything in this theatre is about perception – there is no substance or connection to the physical and ecological context outside the theatre.
But the world outside the theatre still exists. This commentary from Noam Chomsky and the timeless quotes from David Hume apply. The notion of governance as perception management and of politics as a theatre of opinions is what I try to highlight in this article on the CIIC blog. Noam Chomsky is correct in pointing out that in the super-human scale democratic theatre the power lies with the governed once the veil of secrecy is blown away. This is extremely important to realise in our society of ubiquitous surveillance and security agencies from state actors. As Noam Chomsky points out, security agencies are designed to secure the interests of the theatre and not the interests of the population. Anyone who still believes that any security agency or secret service is doing a useful job for any society has been conned by the theatre.
Transparency is the ultimate disinfectant in the digital era. But as long as the population believes in the myth of the necessity for state secrets and corporate secrets – which by definition are secrets with super-human scale / scope, the power of transparency will remain dormant. All super-human scale secrets are instruments of systematic abuse. The sooner this is widely understood the sooner the theatre can be confined to the dustbin of history. My dad worked in the diplomatic service, and even though I was one or more levels removed from the content, the ridiculous and delusional self-importance of the diplomats and their ignorance of physical reality was obvious to a 10-year old. As Douglas Rushkoff observes, “Operation Mind Fuck was too successful, but there is a way to bring back a little bit of hope into what we are doing.”
Beliefs in money, debt, institutions, and systems are better thought of as behavioural patterns (habits) than as beliefs that people are genuinely comfortable with. Even most actors within the theatre are suffering from severe cognitive dissonance. Habits that don’t serve us well are usually referred to as addictions. The challenge for the people stuck in the theatre within corporations and other super-human scale institutions lies in overcoming addiction and story withdrawal symptoms.
When the majority of people start to understand that all our super-human scale organisations are part of the theatre transparency can be deployed as a disinfectant for social diseases.
Human scale
The operating models of Buurtzorg and other non-hierarchical and distributed collaborative organisations like S23M are concrete examples of understandable and relatable human scale organisations.
The fact that human scale social operating systems can be constructed on top of corrupt infrastructure is a powerful message. In particular autistic people are increasingly asking me about S23M’s transparent operating model, and I am more than happy to assist them in setting up neurodiventures that provide them with some level of protection from the toxic and delusional theatre around them. By focusing on the human scale outside the theatre we can reconnect with the physical and ecological niche that supports our human needs.
The book project I am working on won’t provide all the answers – that is impossible – but it can equip small groups of people with:
critical thinking tools and a language framework that encourages creativity and that assists learning and discovery,
as well as an ethical framework that promotes collaboration and knowledge sharing instead of competition.
As part of the project it is necessary to provide an unvarnished account of human history to date. The table of content provides an indication of scope and framing:
Human origins
Human scale patterns
The human lens
Learning
Super-human scale patterns
Loose end : Loss of control
Work-around : Automated labour
Industrial society
Loose end : Exponential growth
Work-around : Computing
Information society
Loose end : Loss of tacit knowledge
Work-around : Busyness
Liquidation society
Loose end : Loss of semantics
Thought experiment : Knowledge society
Addressing the loose ends
Human scale patterns, second edition
Transitioning to human scale
Conclusion
Tools for creating learning organisations
If individual learning seems difficult at times, organisational learning seems elusive or impossible most of the time. In my experience the following tools allow knowledge to flourish at human scale – in the open creative spaces between disciplines and organisational silos:
The SECI knowledge creation spiral is a useful conceptual tool for understanding and improving learning and knowledge flows within organisations. The four SECI activity categories (socialisation, externalisation, combination, internalisation) can be used to describe learning at all levels of organisational scale.
MODA+MODE is a conceptual framework for creating learning organisations that extends the concepts of continuous improvement and the SECI spiral into the realm of knowledge intensive industries, transdisciplinary research and development, and socio-technological innovation. MODA+MODE uses the SECI knowledge creation spiral to release the handbrake on tacit knowledge and creativity by focusing on:
sharing and validating knowledge,
making knowledge explicit and accessible to humans and software tools,
combining shared knowledge in creative ways,
transdisciplinary research and development across organisational boundaries.
Open SpaceTechnology is a very simple and highly scalable technique for powering a continuous SECI knowledge creation spiral that breaks through the barriers of organisational boundaries, established silos and management structures.
The human lens provides thirteen categories that are invariant across cultures, space, and time – it provides a visual language and reasoning framework for transdisciplinary collaboration. The human lens allows us to make sense of the world and the natural environment from a human perspective, to evolve our value systems, and to structure and optimise human economic endeavours.
The human lens is comprised of:
The system lens, to support the formalisation and visual representation of knowledge and resource flows in complex socio-technological systems based the three categories of resources, events, and agents (the REA paradigm, an accounting model developed by E.W. McCarthy in 1982 for representing activities in economic ecosystems). The system lens can be applied at all levels of organisational scale, resulting in fractal representations that reflect the available level of tacit knowledge about the modelled systems.
The semantic lens, to support the formalisation and visual representation of values and economic motivations of the agents identified in the systems lens. The semantic lens provides a configuration framework for articulating economic, ethical, and cultural value systems as well as a reasoning framework for evaluating socio-technological system design scenarios and research objectives with the help of the five categories of social, designed, symbolic, organic, and critical.
The logistic lens, to support the formalisation and visual representation of value creating activities and heuristics within socio-technological systems. The logistic lens provides five categories for describing value creating activities: grow (referring to the production of food and energy), make (referring to the design, engineering, and construction of systems), sustain (referring to the maintenance of production and system quality attributes), move (referring to the transportation of resources and flows of information and knowledge), and play (referring to creative experimentation and other social activities). The logistic lens can be used to model and understand feedback loops across levels of scale (from individuals, to teams, organisations, and economic ecosystems) and between economic agents (companies, regulatory bodies, local communities, research institutions, educational institutions, citizens, and governance institutions). The categories of the logistic lens assist in the identification of suitable quantitative metrics for evaluating performance against the value system articulated via a configuration of the semantic lens.
The 26 MODA+MODE backbone principles provide a baseline set of thinking tools to avoid getting entrapped in a single paradigm. Thinking tools are the mental image schemas, frames, and reasoning tools, and also the behavioural patterns that help us to validate knowledge, ask new questions, and form and explore new ideas – the hugely diverse set of tools that different people tap into as part of the creative process. The backbone principles have been sourced from a range of sciences and engineering disciplines, including suitable mathematical foundations.
The 8 prosocial core design principles developed by Elinor Ostrom, Michael Cox and David Sloan Wilson guide the application of evolutionary science to coordinate action, avoid disruptive behaviours among group members, and cultivate appropriate relationships with other groups in a multi-group ecosystem. The pro social design principles provide a good starting point for implementing concrete policies and systems that are specifically adapted to the needs of neurodiverse groups of people and collaboration in transdisciplinary research and development environments.
At the moment too many organisations and people are either completely paralysed by fear or are running around like headless chickens as part of busyness as usual. Last weekend I found this great clip from Jonathan Pie in my Twitter feed. You can laugh and cry at the same time.
Have you ever wondered why “storytelling” is such a trendy topic? If this question bothers you and makes you uncomfortable, your perspective on human affairs and your cognitive lens is rather unusual.
Once upon a time, in the 1970s, model building gained popularity and nearly caught up with the older art of storytelling. But half a century later the popularity of model building is back to what it was in the 1960s, and according to the data analysis by Google Ngram “storytelling” has reached new heights, the word being used twice as often as the word “agile”.
The “art of storytelling” and “agile software” are strong contenders for being the catchphrase of the current millennium. Is is not surprising that the latter term was not in circulation in the 20th century, but it is perhaps somewhat surprising that the “art of storytelling” was pretty much non-existent before the 20th century.
Model building is linked to the success of the scientific method. Researchers create, validate, and refine models to improve our level of understanding about various aspects of the world we live in, and to articulate their understanding in formal notations that facilitate independent critical analysis.
What is the usefulness of models that are only understandable for very few humans?
The scientific revolution undoubtedly led to a better understanding of some aspects of the world we live in by enabling humans to create more and more complex technologies. But it also created new levels of ignorance about externalities that went hand in hand with the development of new technologies, fuelled by specific economic beliefs about efficiency and abstractions such as money and markets.
In the early days of the industrial revolution modelling was concerned with understanding and mastering the physical world, resulting in progress in engineering and manufacturing. Over the last century formal model building was found to be useful in more and more disciplines, across all the natural sciences, and increasingly as well in medicine and the social sciences, especially in economics.
With 20/20 hindsight it becomes clear that there is a significant lag between model building and the identification of externalities that are created by systematically applying models to accelerate the development and roll-out of new technologies.
Humans are biased to thinking they understand more than they actually do, and this effect is further amplified by technologies such as the Internet, which connects us to an exponentially growing pool of information. New knowledge is being produced faster than ever whilst the time available to independently validate each new nugget of “knowledge” is shrinking, and whilst the human ability to learn new knowledge at best remains unchanged – if it is not compromised by information overload.
Those who engage in model building face the challenge of either diving deep into a narrow silo, to ensure and adequate level of understanding of a particular niche domain, or to restrict their activity to an attempt of modelling the dependencies between subdomains, and to coordinating the model building of domain experts across a number of silos. As a result:
Many models are only understandable for their creators and a very small circle of collaborators.
Each model integrator can only be effective at bridging a very limited number of silos.
The assumptions associated with each model are only known understood locally, some of the assumptions remain tacit knowledge, and assumptions may vary significantly between the models produced by different teams.
Many externalities escape early detection, as there is hardly anyone or any technology continuously looking for unexpected results and correlations across deep chains of dependencies between subdomains.
When the translation of new models into new applications and technologies is not adequately constrained by the level to which models can be independently validated and by application of the precautionary principle, potentially catastrophic surprises are inevitable.
Does it make sense to talk about models that are not understandable for any human?
Good models are not only useful, they are also understandable and have explanatory power – at least for a few people. Additionally, from the perspective of a mathematician, many of the most highly valued models also conform to an aesthetic sense of beauty, by surfacing a surprising degree of symmetry, by bringing non-intuitive connections into focus, and simply by their level of compactness.
Scientific model building is a balancing act between simplicity and usefulness. An overly complex model is less easy to understand and therefore less easy to integrate with complementary models, and an over-simplified model may be easy to work with, but may be so limited in its scope of applicability that it becomes useless.
What is not widely recognised beyond the mathematical community is that the so-called models generated by machine learning algorithms / artificial intelligence systems are not human understandable, for the same reasons that the physical representations of knowledge within a human brain are not understandable by humans. Making any sense of knowledge representations in a brain requires not only highly specialised scanning technologies but also non-trivial visualisation technologies – and the resulting pictures only give us a very crude and indirect understanding of what a person experiences and thinks about at any given moment.
Do correlation models without explanatory power qualify as models? There are many useful applications of machine learning, but if the learning does not result in models that are understandable, then the results of machine learning should perhaps be referred to as digital correlation maps to avoid confusion with models that are designed for human consumption. Complex correlation maps can be visualised in ways similar to the results of brain scans, and the level of insights that can be deduced from such visualisations are correspondingly limited.
It is not yet clear how to construct conscious artificial intelligence systems, i.e. systems that can not only establish correlations between data streams, but that are also capable of developing conceptual models of themselves and their environment that can be shared with and can be understood by humans. In particular current machine learning systems are not able to explain how they arrive at specific conclusions.
The limitations of machine learning highlights what is being lost by neglecting model building and by leaving modelling entirely to individual experts working in deep and narrow silos. Model validation and integration has largely been replaced with over-simplified storytelling – the goal has shifted from improving understanding to applying the tools of persuasion.
Bernays’ vision was of a utopian society in which individuals’ dangerous libidinal energies, the psychic and emotional energy associated with instinctual biological drives that Bernays viewed as inherently dangerous given his observation of societies like the Germans under Hitler, could be harnessed and channelled by a corporate elite for economic benefit. Through the use of mass production, big business could fulfil the cravings of what Bernays saw as the inherently irrational and desire-driven masses, simultaneously securing the niche of a mass production economy (even in peacetime), as well as sating what he considered to be dangerous animal urges that threatened to tear society apart if left unquelled.
Bernays touted the idea that the “masses” are driven by factors outside their conscious understanding, and therefore that their minds can and should be manipulated by the capable few. “Intelligent men must realize that propaganda is the modern instrument by which they can fight for productive ends and help to bring order out of chaos.”
The conscious and intelligent manipulation of the organized habits and opinions of the masses is an important element in democratic society. Those who manipulate this unseen mechanism of society constitute an invisible government which is the true ruling power of our country. …In almost every act of our daily lives, whether in the sphere of politics or business, in our social conduct or our ethical thinking, we are dominated by the relatively small number of persons…who understand the mental processes and social patterns of the masses. It is they who pull the wires which control the public mind.
Propaganda was portrayed as the only alternative to chaos.
The purpose of storytelling is the propagation of beliefs and emotions.
What is the usefulness of stories if they do nothing to improve our level of understanding of the world we live in?
Sure, if stories help to increase the number of shared beliefs within a group, then the people involved may understand more about the motivations and behaviours of the others within the group. But at the same time, in the absence of building improved models about the non-social world, the behaviour of the group easily drifts into more and more abstract realms of social games, making the group increasingly blind to the effects of their behaviours on outsiders and on the non-social world.
Stories are appealing and hold persuasive potential because of their role in cultural transmission is the result of gene-culture co-evolution in tandem with the human capability for symbolic thought and spoken language. In human culture stories are involved in two functions:
Transmission of beliefs that are useful for the members of a group. Shared beliefs are the catalyst for improved collaboration.
Deception in order to protect or gain social status within a group or between groups. In the framework of contemporary competitive economic ideology deception is often referred to as marketing.
Storytelling thus is a key element of cultural evolution. Unfortunately cultural evolution fuelled by storytelling is a terribly slow form of learning for societies, even though storytelling is an impressively fast way for transmitting beliefs to other individuals. Not entirely surprisingly some studies find the prevalence of psychopathic traits in the upper echelons of the corporate world to be between 3% and 21%, much higher than the 1% prevalence in the general population.
Storytelling with the intent of deception enables individuals to reap short-term benefits for themselves to the longer-term detriment of society
The extent to which deceptive storytelling is tolerated is influenced by cultural norms, by the effectiveness of institutions and technologies entrusted with the enforcement of cultural norms, and the level of social inequality within a society. The work of the disciples of Edward Berneys ensured that deceptive storytelling has become a highly respected and valued skill.
However, simply focusing on minimising deception is no fix for all the weaknesses of storytelling. When a society with highly effective norm enforcement insists on rules and behavioural patterns that create environmental or social externalities, some of which may be invisible from within the cultural framework, deception can become a vital tool for those who suffer as a result of the externalities.
Furthermore, even in the absence of intentional deception, the maintenance, transmission, and uncritical adoption of beliefs via storytelling can easily become problematic if beliefs held in relation to the physical and living world are simply wrong. For example some people and cultures continue to hold scientifically untenable beliefs about the causes of specific diseases.
All political and economic ideologies rely on storytelling
Human societies are complex adaptive systems that can’t be described by any simple model. More precisely, it is not possible to develop long-range and detailed predictive models for social and economic behaviour. However, in a similar way that extensive sensor networks and modern computing technology allows the development of useful short-range weather forecasts, it is possible to use social and economic data to look for externalities and attempts of corruption.
Nothing stands in the way of monitoring the results of significant social and economic changes with a level of diligence that is comparable to the diligence expected from researchers when conducting scientific experiments in the medical field. Of course the pharmaceutical industry also has a reputation for colourful storytelling, and the healthcare sector is not spared from ethical corruption and the tools of marketing. But at least the healthcare sector is heavily regulated, academic research is an integral part of the sector, and independent validation of results is part of the certification process for all new products and treatments.
One has to wonder why economic and social policies are not subject to a comparable level of independent oversight. The model of governance in modern democracies typically includes a separation of power between legislature, executive, and judiciary, but the question is whether effective separation of power can be maintained over decades and centuries.
Human societies and social structures are far from static. Concepts such as the nation state are only a couple of hundred years old and the lifespan of economic bubbles and the structures created by within such bubbles is measured in years rather than centuries. And yet, many people and institutions are incapable of considering possible economic or social arrangements that lie outside consumerism and the cultural norms that currently dominate within a particular nation state. Cultural inertia is beneficial for societies whenever the environment in which they are embedded is highly stable, but it becomes problematic when the environment is undergoing rapid change.
Historically a rapidly changing environment used to be associated with local wars or local natural disasters such as extended periods of draughts or earthquakes. The industrial revolution has significantly shifted the main triggers of rapid change:
Improvements in technology, hygiene and medicine have facilitated significant population growth and ushered in a new geological era – the anthropocene, human activity is changing the physical environment faster than ever before
Machine powered technology has enabled wars of unprecedented scale, speed, and levels of destructiveness
The paradigm of growth based economics fuelled by interest bearing debt and aggressive marketing dominates on all continents in most societies, and facilitates global economic bubbles
Carbon emissions and other physical externalities of modern economic activity have no physical boundaries
Given this context it is extremely tempting for professional politicians within government and corporations to subscribe to the elitist logic of Edward Bernays and to exploit storytelling for local or personal gains. An alien observer of human societies would probably be amazed that some humans (and large organisations) are given a platform for virtually unlimited storytelling at a scale that affects billions and hundreds of millions people, and that delusional and misleading stories are let lose on the population of a species that is the local champion of cultural transmission on this planet.
Within growth based economics the effectiveness of marketing can never be good enough. Desperate corporations are hoping machine learning algorithms can take storytelling to yet another level. High frequency trading is one example of “successful” automated marketing, where algorithms try to trick each other into believing stories that are beyond human comprehension.
End of story?
If we continue to believe that the world is shaped exclusively by human delusions, then the human story may come to a fairly unspectacular end rather soon. It also won’t help us if we focus on building technologies that provide even more powerful delusions.
If there is anything that has led to significant improvements in human well-being and life expectancy in the last thousand years it would undoubtedly have to be model building and the scientific method. The power tools of systematic experimentation and modelling facilitated much of what we call progress but they also facilitated dangerous social games at a planetary scale.
Just as medical science no longer relies on unsubstantiated stories, the stories that we tell each other in business, government, and academic administration need to be subjected to critical analysis, and the public needs to be made aware of the evidence (or lack thereof) that underpins the claims of politicians and executives in the corporate world, so that experiments are clearly identified, and most importantly, that experiments are carefully monitored and subjected to independent review before being sold as solutions.
In this context lessons can be learned from the fast moving world of digital technology. On the positive side the software development community is acutely aware of the need to conduct experiments, on the negative side, outside a few life critical industries, the lack of rigour when conducting experiments in the development and deployment of new software solutions is embarrassing. In the software development community conducting multiple independent experiments is generally considered a waste of time, and the interests of financial investors determine the kinds of “solutions” that receive funding:
All human artefacts are technology. But beware of anybody who uses this term. Like “maturity” and “reality” and “progress”, the word “technology” has an agenda for your behaviour: usually what is being referred to as “technology” is something that somebody wants you to submit to.
“Technology” often implicitly refers to something you are expected to turn over to “the guys who understand it.” This is actually almost always a political move. Somebody wants you to give certain things to them to design and decide. Perhaps you should, but perhaps not. – Ted Nelson, a pioneer of information technology, philosopher, and sociologist who coined the terms hypertext and hypermedia in 1963.
The software industry is an interesting economic subsystem for observing human social behaviour at large scale. Today this sector is interwoven with virtually all other economic subsystems and even with the most common tools that we use for communicating with each other.
David Graeber has analysed the phenomenon of “bullshit jobs” in detail.
“In the year 1930, John Maynard Keynes predicted that technology would have advanced sufficiently by century’s end that countries like Great Britain or the United States would achieve a 15-hour work week. There’s every reason to believe he was right. In technological terms, we are quite capable of this. And yet it didn’t happen. Instead, technology has been marshalled, if anything, to figure out ways to make us all work more. In order to achieve this, jobs have had to be created that are, effectively, pointless. Huge swathes of people, in Europe and North America in particular, spend their entire working lives performing tasks they secretly believe do not really need to be performed. The moral and spiritual damage that comes from this situation is profound. It is a scar across our collective soul. Yet virtually no one talks about it. …”
Silicon Valley innovation pop-culture?
Students of software engineering and computer science are often attracted by the idea of “innovation” and by the prospect of exciting creative work, contributing to the development of new services and products. The typical reality of software development has very little if anything to do with innovation and much more with building tools that support David Graeber’s “bullshit jobs” and Edward Bernays’ elitist “utopia” of conscious manipulation of the habits and opinions of the masses by a small number of “leaders” suffering from narcissistic personality disorder.
The culture within the software development community is shaped much less by mathematics and scientific knowledge about the physical world than by the psychology of persuasion – and an anaemic conception of innovation based on social popularity and design principles that encourage planned obsolescence. A few years ago Alan Kay, a pioneer of object-oriented programming and windowing graphical user interface design observed:
It used to be the case that people were admonished to “not re-invent the wheel”. We now live in an age that spends a lot of time “reinventing the flat tire!”
The flat tires come from the reinventors often not being in the same league as the original inventors. This is a symptom of a “pop culture” where identity and participation are much more important than progress. … In the US we are now embedded in a pop culture that has progressed far enough to seriously hurt places that hold “developed cultures”. This pervasiveness makes it hard to see anything else, and certainly makes it difficult for those who care what others think to put much value on anything but pop culture norms.
Mainstream software development practices are geared towards dealing with the characteristics of big ball of mud architectures and the reality of the curse of software maintenance.
Do we need a better language for model building?
Making model building accessible to a wider audience may require developing a cognitively simple visual language for articulating resource and information flows in living and economic systems in a format that is not influenced by any particular economic ideology.
Many of the languages of mathematics already make use of visual concept graphs. Digital devices open up the possibility of highly visual languages and user interfaces that enable everyone to create concept graphs that are formal in a mathematical sense, understandable for humans, and easily processable by software tools. The only formal foundations needed implementing such a visual language system are axioms from model theory, category theory, and domain theory.
In terms of usability, a formal software-mediated visual language system that takes into consideration human cognitive limits has the potential to:
Improve the speed and quality of knowledge transfer between human domain experts
Improve the speed and quality of knowledge transfer between human domain experts and software tools
Facilitate innovative approaches to extracting human understandable semantics from informal textual artefacts, in a format that is easily processable by software tools
Facilitate innovative approaches to unsupervised machine learning that deliver results in a format that is compatible with familiar representations used by human domain experts, enabling the construction of knowledge repositories capable of receiving inputs from:
human domain experts
informal textual sources of human knowledge
machine learning systems
All scientists, engineers, and technologists are familiar with a language that is more expressive and less ambiguous than spoken and written language. The language of concept graphs with highly domain and context-specific iconography regularly appears on white boards whenever two or more people from different disciplines engage in collaborative problem solving. Such languages can easily be formalised mathematically and can be used in conjunction with rigorous validation by example / experiments.
Model building and digital correlation maps can go hand in hand
Machine learning need not result in opaque systems that are as difficult to understand as humans, and a formal visual language may represent the biggest breakthrough for improving the understanding between humans since the development of spoken language.
… And storytelling and social transmission need not result in a never ending sequence of psychopathic social games if we get into the habit of explicitly tagging all stories with the available supporting evidence, so that untested ideas and attempts of corruption become easier to identify.
Mathematics – the language of explanation and validation
Paul Lockhart describes mathematics as the art of explanation. He is correct. Mathematical proofs are the one type of storytelling that is committed to being entirely open regarding all assumptions and to the systematically exploring all the possible implications of specific sets of assumptions. Foundational mathematical assumptions are usually refereed to as axioms.
Formal proofs are parametrised formal stories (sequences of reasoning steps) that explore the possibilities of entire families of stories and their implications. Mathematical beauty is achieved when a complex family of stories can be described by a small elegant formal statement. Complexity does not melt away accidentally. It is distilled down to the its essence by finding a “natural language” (or “model”) for the problem space represented by a family of formal stories.
A useful model encapsulates all relevant commonalities of the problem space – it provides an explanation that is understandable for anyone who is able to follow the reasoning steps leading to the model.
The more parameters and relationships between parameters come into play, the more difficult it typically is to uncover cognitively simple models that shed new light onto a particular problem space and the underlying assumptions. If a particular set of formal assumptions is found to have a correspondence in the physical or living world, the potential for positive and negative technological innovation can be profound.
Whether the positive or negative potential prevails is determined by the motivations, political moves, and stories told by those who claim credit for innovation.
Any hope of progress beyond stories?
From within a large organisation culture is often perceived as being static or very slow moving locally, and changes in the environment are being perceived as being dynamic and fast moving. This is an illusion. It is easy to lose sight of the bigger picture.
Outside the context of “work” the people within a large organisation are part of many other groups and part of the rapidly evolving “external” context. The larger an organisation, the greater the inertia of the internal organisational culture, and the faster this culture disconnects from the external cultural identities of employees, customers, and suppliers.
The resulting cognitive dissonance manifests itself in terms of low levels of employee engagement, high levels of mental illness, and the increasingly short life expectancy of large corporations. Group identities and concepts such as intelligence and success are cultural constructs that are subject to evolutionary pressure and phase transitions.
Marketing may well become a taboo in the not-too-distant future
Over the next few weeks, to my knowledge, there are at least four dedicated conferences on the topics of redefining intelligence, new economics, and cultural evolution.
Conference on Interdisciplinary Innovation and Collaboration
Melbourne, Australia – 2 September 2017
Auckland, New Zealand – 16 September 2017
These events are part of the quarterly CIIC unconference series, addressing challenges that go beyond the established framework of research in industry, government and academia. The workshops in September will build on the results from earlier workshops to explore the essence of humanity and how to construct organisations that perform a valuable function in the living world.
The historic record of societies and large organisations being aware of the limitations of their culture is highly unimpressive. Redefining intelligence is our chance to break out of self-destructive patterns of behaviour. It is a first step towards a better understanding of the positive and negative human potential within the ecological context of the planet.
More information on CIIC and the theme for the upcoming unconference:
Thanks to Pete Rive and Arthur Shelley at AUT and RMIT for providing CIIC with superb venues!
New Economy Conference
Brisbane, Australia – 1-3 September 2017
Building on the inaugural 2016 conference held in Sydney, the 2017 gathering invites people to come together to share stories of success, address challenges and join the broader movement so we can continue working together to build a ‘new’ economic system. The 2017 New Economy Conference will bring together hundreds of people and organisations to launch powerful new collective strategies for creating positive social and economic change, to achieve long term, liveable economies that fit within the productive capacity of a healthy environment.
More information on NENA and the Building the New Economy conference:
The Cultural Evolution Society supports evolutionary approaches to culture in humans and other animals. The society welcomes all who share this fundamental interest, including in the pursuit of basic research, teaching, or applied work. We are committed to fostering an integrative interdisciplinary community spanning traditional academic boundaries from across the social, psychological, and biological sciences, and including archaeology, computer science, economics, history, linguistics, mathematics, philosophy and religious studies. We also welcome practitioners from applied fields such as medicine and public health, psychiatry, community development, international relations, the agricultural sciences, and the sciences of past and present environmental change.
More information on CES and the related conference:
I have always been irritated by people for whom business is first and foremost about “monetisation”. Extrinsically motivated busyness people are incapable of understanding any non-trivial innovation. The worship of monetisation often goes hand-in-hand with the introduction of so-called “organisational values” as hollow slogans, with no thoughts spared for how these values are going to be enacted, and how they might create something that people within and beyond the organisation actually recognise and appreciate as valuable.
Existing approaches like the highly popular business model canvas or the OMG’s business motivation model miss the bigger picture of cultural evolution in the context of zero marginal cost communication and assume a very traditional business mindset.
Value systems
We live in a context of rapid and multidimensional cultural evolution. A few years ago the need for agreeing of what constitutes a useful direction and the need for assessing progress prompted me to design a simple modelling language for purpose and value systems.
The semantic lens is a simple tool for agreeing what is considered valuable, and it assists in identifying suitable metrics for keeping track of output or progress. As a nice side effect the metrics encouraged by the semantic lens prevent results from being dumbed down prematurely to easily corruptible monetary numbers.
Example of an instantiated semantic lens
The semantic lens is a visual language for describing human motivations. Four of the five core concepts directly relate to the outputs of human creativity, and nature, and the fifth concept, is directly connected to the first four concepts. The element of critical self-reflection invites the questioning of established values and the consideration of alternative candidate values.
A configured semantic lens assists in surfacing the cultural context and assumed value system that underpins the value proposition of a potential innovation. In the absence of an explicit value system it is impossible to reason about innovation in any meaningful way – the discussion is limited to thinking within the established cultural box and very easily deteriorates into a discussion of “ingenious ways of monetising data”.
The S23M semantic lens explains why S23M exists
Critical self-reflection : regarding all other elements of the semantic lens (in no particular order) towards sustainability, resilience, and happiness
Symbols : Co-creating organisations and systems which are understandable by future generations of humans and software tools
Nature : Maximising biodiversity
Artefacts : Minimising human generated waste
Society : Creating a more human and neurodiversity friendly environment
Generating more trust – less surprising misunderstandings, more collaborative risk taking, less exploitation, more mutual aid
Generating more learning – more open knowledge sharing, less indirect language, less hierarchical control, deeper understanding
Generating more diversity – more appreciation of difference, less coercion, more curiosity
We are in the business of strengthening / weakening specific feedback loops
The S23M semantic lens is supported by 26 principles that form the backbone of our operating model, and which assist us in building out a unique niche in the living world.
Value creating activities
To go beyond motivations and intent, and to describe the value creating activities within an economic system, or the activities of a specific organisation or individual economic agent, requires a dedicated modelling language beyond the semantic lens.
Understanding the human value creation process is not helped by the multitude of completely arbitrary and internally overlapping categorisation schemes that economists and business people use to talk about industries and sectors. The logistic lens has the potential to put an end to the distracting proliferation of jargons via five simple categories. In the logistic lens models can be nested in a fractal structure as needed to reflect the reality of complex systems.
Four of the five core concepts of the logistic lens deal with activities that produce observable results in the physical and natural environment, and all human cultural activities that are one or more levels removed from being measurable in the physical and natural environment are confined to the culture concept.
Energy and food production provide the fuel for all our human endeavours.
Design and engineering are the focus of many human creative endeavours, and have resulted in the tools that power our societies.
Transportation and communication allow human outputs, both in terms of concrete and abstract artefacts, to be shared and made available to others, and allow resources and knowledge to be deployed wherever they are needed.
Maintenance and quality related activities are those that are needed to keep human societies and human designed technologies operational.
Example of an instantiated logistic lens to structure and optimise activities within a given culture
Economic progress and value creation can be understood in terms of the cultural activities of playing and learning, and related design and engineering activities that lead to technological innovation.
Truly disruptive innovations have the characteristic of not only resulting in a new player in the economic landscape, but they also trigger or tap into a shift in value systems. Thus the semantic lens is a useful gauge for identifying and exploring potentially disruptive innovations.
Taken together the semantic and logistic lenses provide a very small and powerful language for reasoning about human behaviour and human creativity – even beyond the confines of established social norms and best business practices.
Innovation and cultural change can only be transformative if it substantially redefines social norms and so-called best practice.
Depending on who you ask, the perceptions of mathematics range from an esoteric discipline that has little relevance to everyday life to a collection of magical rituals and tools that shape the operations of human cultures. In an age of exponentially increasing data volumes, the public perception has increasingly shifted towards the latter perspective.
On the one hand it is nice to see a greater appreciation for the role of mathematics, and on the other hand the growing use of mathematical techniques has led to a set of cognitive blind spots in human society:
Blind use of mathematical formalisms – magical rituals
Blind use of second hand data – unvalidated inputs
Blind use of implicit assumptions – unvalidated assumptions
Blind use of second hand algorithms – unvalidated software
Blind use of terminology – implicit semantic integration
Blind use of numbers – numbers with no sanity checks
Construction of formal models is no longer the exclusive domain of mathematicians, physical scientists, and engineers. Large and fast flowing data streams from very large networks of devices and sensors have popularised the discipline of data science, which is mostly practiced within corporations, within constraints dictated by business imperatives, and mostly without external and independent supervision.
The most worrying aspect of corporate data science is the power that corporations can wield over the interpretation of social data, and the corresponding lack of power of those that produce and share social data. The power imbalance between corporations and society is facilitated by the six cognitive blind spots, which affect the construction of formal models and their technological implementations in multiple ways:
Magical rituals lead to a lack of understanding of algorithm convergence criteria and limits of applicability, to suboptimal results, and to invalid conclusions. Examples: Naive use of frequentist statistical techniques and incorrect interpretations of p-values by social scientists, or naive use of numerical algorithms by developers of machine learning algorithms.
Unvalidated inputs open the door for poor measurements and questionable sampling techniques. Examples: use of data sets collected by a range of different instruments with unspecified characteristics, or incorrect priors in Bayesian probabilistic models.
Unvalidated assumptions enable the use of speculative causal relationships, simplistic assumptions about human nature, and create a platform for ideological bias. Examples: many economic models rest on outdated assumptions about human behaviour, and consciously ignore evidence from other disciplines that conflicts with established economic dogma.
Unvalidated software can produce invalid results, contradictions, and unexpected error conditions . Examples: outages of digital services from banks and telecommunications service providers are often treated as unavoidable, and computational errors sometimes cost hundreds of millions of dollars or hundreds of lives.
Unvalidated semantic links between mathematical formalisms, data, assumptions and software facilitate further bias and spurious complexity. Examples: Many case studies show that formalisation of semantic links and systematic elimination of spurious complexity can reduce overall complexity by factors between 3 and 20, whilst improving computational performance.
Unvalidated numbers can enable order of magnitude mistakes and obvious data patterns to remain undetected. Example: Without adequate visual representations, even simple numbers can be very confusing for a numerically challenged audience.
Whilst a corporation may not have an explicit agenda for creating distorted and dangerously misleading models, the mechanics of financial economics create an irresistible temptation to optimise corporate profit by systematically shifting economic externalities into cognitive blind spots. A similar logic applies to government departments that have been tasked to meet numerically specified objectives.
Mathematical understanding and numerical literacy is becoming increasingly important, but it is unrealistic to assume that the majority of the population will become sufficiently proficient in mathematics and statistics to be able to validate and critique the formal models employed by corporations and governments. Transparency, including open science, open data, and open source software are are emerging as essential tools for independent oversight of cognitive blind spots:
Mathematicians must be able to review the formalisms that are being used
Statisticians must be able to review measurement techniques and input data sources
Scientists and experts from disciplines relevant to the problem domain must be able to review assumptions
Software engineers familiar with the software tools that are being used must be able to review software implementations
Mathematicians with an understanding of category theory, model theory, denotational semantics, and conceptual modelling must be able to review semantic links between mathematical formalisms, terminology, data, assumptions, and software
Mathematicians and statisticians must be able to review data representations
In a zero marginal cost society, transparency allows scarce and highly specialised mathematical knowledge to be used for the benefit of society. It is very encouraging to note the similarity in knowledge sharing culture between the mathematical community and the open source software community, and to note the decreasing relevance of opaque closed source software.
The more society depends on decisions made with the help of mathematical models, the more important it becomes that these decisions adequately accommodate the concrete needs of individuals and local communities, and that the language used to reason about economics remains understandable, and enables the articulation of economic goals in simple terms.
The big human battle of this century is going to be the democratisation of data and all forms of knowledge, and the introduction of digital government with the help of free and open source software
Whilst undoubtedly the reaction of the planet to the explosion of human activities with climate change and other symptoms is the largest change process that has ever occurred in human history in the physical realm, the exponential growth of the Internet of Things and digital information flows is triggering the largest change process in the realm of human organisation that societies have ever experienced.
The digital realm
Sensor networks and pervasive use of RFID tags are generating a flood of data and lively machine-to-machine chatter. Machines have replaced humans as the most social species on the planet, and this must inform the approach to the development of healthy economic ecosystems.
Sensors that are part of the Internet of Things
When data scientists and automation engineers collaborate with human domain experts in various disciplines, machine-generated data is the magic ingredient for solving the hardest automation problems.
In domains such as manufacturing and logistics the writing is on the wall. Introduction of self-driving vehicles and just a few more robots on the shop floor will eliminate the human element in the social chatter at the workplace within the next 10 years.
The medical field is being revolutionised by the downward spiral of the cost of genetic analysis, and by the development of medical robots and medical devices that are hooked up to the Internet, paving the way for machine learning algorithms and big data to replace many of the interactions with human medical professionals.
The road ahead for the provision of government services is clearly digital. It is conceivable that established bureaucracies can resist the trend to digitisation for a few years, but any delay will not prevent the inevitability of automation.
Large global surveys show that more than 70% of employees are disengaged at work. It is mainly in manufacturing that automation directly replaces human labour. In many other fields the shift in responsibilities from humans to machines initially goes hand in hand with the invention of new roles and loss of a clear purpose.
Traditional work is being transformed into a job for a machine. Exceptions are few and far between.
Data that is not sufficiently accessible is only of very limited value to society. The most beneficial and disruptive data driven innovation are those that result from the creative combination of data sets from two or more different sources.
It is unrealistic to assume that the most creative minds can be found via the traditional channel of employment, and it is unrealistic that such minds can achieve the best results if data is locked up in organisation-specific or national silos.
The most valuable data is data that has been meticulously validated, and that is made available in the public domain. It is no coincidence that software, data, and innovation is increasingly produced in the public domain. Jeremy Rifkin describes the emergence of a third mode of commons-based digitally networked production that is distinct from the property- and contract-based modes of firms and markets.
It is worthwhile remembering the origin of the word economics. It used to denote the rules for good household management. On a planet that hosts life, household management occurs at all levels of scale, from the activities of single cells right up to processes that involve the entire planetary ecosystem. Human economics are part of a much bigger picture that always included biological economics and that now also includes economics in the digital realm.
To be able to reason about economics at a planetary level the planet needs a language for reasoning about economic ecosystems, only some of which may contain humans. Ideally such a language should be understandable by humans, but must also be capable of reaching beyond the scope of human socio-economic systems. In particular the language must not be coloured by any concrete human culture or economic ideology, and must be able to represent dependencies and feedback loops at all levels of scale, as well as feedback loops between levels of scale, to enable adequate representation of the fractal characteristic of nature.
The digital extension of the planetary nervous system
In biology the use of electrical impulses for communication is largely confined to communication within individual organisms, and communication between organisms is largely handled via electromagnetic waves (light, heat), pressure waves (sound), and chemicals (key-lock combinations of molecules).
The emergence of the Internet of Things is adding to the communication between human made devices, which in turn interact with the local biological environment via sensors and actuators. The impact of this development is hard to overestimate. The number of “tangible” things that might be computerized is approaching 200 billion, and this number does not include large sensor networks that are being rolled out by scientists in cities and in the natural environment. Scientists are talking about trillion-sensor networks within 10 years. The number of sensors in mobile devices is already more than 50 billion.
Compared to chemical communication channels between organisms, the speed of digital communication is orders of magnitude faster. The overall effect of equipping the planet with a ubiquitous digital nervous system is comparable to the evolution of animals with nervous systems and brains – it opens up completely new possibilities for household management at all levels of scale.
The complexity of the Internet of Things that is emerging on the horizon over the next decade is comparable to the complexity of the human brain, and the volume of data flows handled by the network is orders of magnitudes larger than anything a human brain is able to handle.
The global brain
Over the course of the last century, starting with the installation of the first telegraph lines, humans have embarked on the journey of equipping the planet with a digital electronic brain. To most human observers this effort has only become reasonably obvious with the rise of the Web over the last 20 years.
Human perception and human thought processes are strongly biased towards the time scales that matter to humans on a daily basis to the time scale of a human lifetime. Humans are largely blind to events and processes that occur in sub-second intervals and processes that are sufficiently slow. Similarly human perception is biased strongly towards living and physical entities that are comparable to the physical size of humans plus minus two orders of magnitude.
As a result of their cognitive limitations and biases, humans are challenged to understand non-human intelligences that operate in the natural world at different scales of time and different scales of size, such as ant colonies and the behaviour of networks of plants and microorganisms. Humans need to take several steps back in order to appreciate that intelligence may not only exist at human scales of size and time.
The extreme loss of biodiversity that characterises the anthropocene should be a warning, as it highlights the extent of human ignorance regarding the knowledge and intelligence that evolution has produced over a period of several billion years.
Just like an individual human is a complex adaptive system, the planet as a whole is a complex adaptive system. All intelligent systems, whether biological or human created, contain representations of themselves, and they use these representations to generate goal directed behaviour. Examples of intelligent systems include not only individual organisms, but also large scale and long-lived entities such as native forests, ant colonies, and coral reefs. The reflexive representations of these systems are encoded primarily in living DNA.
From an external perspective it nearly seems as if the planetary biological brain, powerful – but thinking slowly in chemical and biological signals over thousands of years, has shaped the evolution of humans for the specific purpose of developing and deploying a faster thinking global digital brain.
The global digital brain is currently still in under development, not unlike the brain of a human baby before birth. All corners of the planet are being wired up and connected to sensors and actuators. The level of resilience of the overall network depends on the levels of decentralisation, redundancy, and variability within the network. A hierarchical structure of subsystems as envisaged by technologist Ray Kurzweil is influenced by elements of established economic ideology rather than by the resilient neural designs found in biology. A hierarchical global brain would likely suffer from recurring outages and from a lack of behavioural plasticity, not unlike the Cloud services from Microsoft and Amazon that define the current technological landscape.
Global thinking
The ideology of economic globalisation is dominated by simplistic and flawed assumptions. In particular the concepts of money and globally convertible currencies are no longer helpful and have become counter-productive. The limitations of the monetary system are best understood by examining the historic context in which money and currencies were invented, which predates the development of digital networks by several thousand years. At the time a simple and crude metric in the form of money was the best technology available to store information about economic flows.
As the number of humans has exploded, and as human societies have learned to harness energy in the form of fossil fuels to accelerate and automate manufacturing processes, the old monetary metrics have become less and less helpful as economic signals. In particular the impact of economic externalities that are ignored by the old metrics, both in the natural environment as well as in the human social sphere, is becoming increasingly obvious.
The global digital brain allows flows of energy, physical resources, and economic goods to be tracked in minute detail, without resorting to crude monetary metrics and assumptions of fungibility that open the door to suppressing inconvenient externalities.
Metrics are still required, but the new metrics must provide a direct and undistorted representation of flows of energy, physical resources, and economic goods. Such highly context specific metrics enable computational simulation and optimisation of zero-waste economics. Their role is similar to the role of chemical signalling substances used by biological organisms.
Global thinking requires the extension of a zero-waste approach to economics to the planetary level – leaving no room for any known externalities, and encouraging continuous monitoring to detect unknown externalities that may be affecting the planetary ecosystem.
The future of human economics
The real benefits of the global digital brain will be realised when massive amounts of machine generated data become accessible in the public domain in the form of disruptive innovation, and are used to solve complex optimisation problems in transportation networks, distributed generation and supply of power, healthcare, recycling of non-renewable resources, industrial automation, and agriculture.
Five years ago Tim O’Reilly predicted a war for control of the Web. The hype around big data has let many organisations forget that the Web and social media in particular is already saturated with explicit and implicit marketing messages, and that there is an upper bound to the available time (attention) and money for discretionary purchases. A growing list of organisations is fighting over a very limited amount of potential revenue, unable to see the bigger picture of global economics.
Over the next decade one of the biggest challenges will be the required shift in organisational culture, away from simplistic monetisation of big data, towards collaboration and extensive data and knowledge sharing across disciplines and organisational boundaries. The social implications of advanced automation across entire economic ecosystems, and a corresponding necessary shift in the education system need to be addressed.
The future of humans
Human capabilities and limitations are under the spot light. How long will it take for human minds to shift gears, away from the power politics and hierarchically organised societies that still reflect the cultural norms of our primate cousins, and from myopic human-centric economics, towards planetary economics that recognise the interconnectedness of life across space and time?
The future of democratic governance could be one where people vote for human understandable open source legislation that is directly executable by intelligent software systems. Corporate and government politicians will no longer be deemed as an essential part of human society. Instead, any concentration of power in human hands is likely to be recognised as an unacceptable risk to the welfare of society and the health of the planet.
Earth
Humans have to ask themselves whether they want to continue to be useful parts of the ecosystem of the planet or whether they prefer to take on the role of a genetic experiment that the planet switched on and off for a brief period in its development.
Oh the irony. Last week I wrote an article on the role of service resilience in shaping a positive user experience, and today I’m trying to use a basic digital service to charge up a mobile with credit before travelling overseas – and receive the following notification, along the lines of:
Dear customer, unfortunately the opening hours of our digital service are top secret.
Not even an indication of when it may be worthwhile trying again. The local 0800 number is also not of much help to a traveller. The particular incident is just one example of typical quality of service in the digital realm. Last week, before this wonderful user experience, I wrote:
The digitisation of services that used to be delivered manually puts the spotlight on user experience as human interactions are replaced with human to software interactions. Organisations that are intending to transition to digital service delivery must consider all the implications from a customer’s perspective. The larger the number of customers, the more preparation is required, and the higher the demands in terms of resilience and scalability of service delivery. Organisations that do not think beyond the business-as-usual scenario of service delivery may find that customer satisfaction ratings can plummet rapidly.
Promises made in formal service level agreements are easily broken. Especially if a service provider operates a monopoly, the service provider has very little incentive to improve quality of service, and ignores the full downstream costs of outages incurred by service users.
All assurances made in service level agreements with external service providers need to be scrutinised. Seemingly straightforward claims such as 99.99% availability must be broken down into more meaningful assurances. Does 99.9% availability mean one outage of up to 9 hours per year, or a 10 minute outage per week, or a 90 second outage per day? Does the availability figure include or exclude any scheduled service maintenance windows?
My recommendation to all operators of digital services: Compute the overall risk exposure to unavailability of services and make informed decisions on the level of service that must be offered to customers. As a rule, when transitioning from manual services to digital services, ensure that customers benefit from an increase in service availability. The convenience of close to 24×7 availability is an important factor to entice customers to use the digital channel.
The shift of business applications and business data into the Cloud has led to the following challenges:
The physical locations at which data is stored, and the physical locations through which data travels are increasingly unknown to the producers and consumers of data.
Data ownership and the responsibility of data custodianship is increasingly impossible to determine, as deep Web service supply chains transect multiple contracts and jurisdictional boundaries.
Local (national) privacy legislation is increasingly impossible to enforce.
The control over the integration points between a specific pair of Cloud services is migrating away from the thousands and millions of organisations whose data is being integrated to a few handfuls of vendors that specialise in connecting the specific pair of Cloud services.
Correspondingly the responsibility for the robustness and reliability of system integration solutions is shifting to a small number of proprietary Cloud services.
The centralised and constrained Web of today
The structure of the Web of today artificially imposes the same constraints on the digital realm that apply in the physical realm.
Centralised and hierarchical control of the Web creates a whole number of avoidable problems. Netizens, and especially the younger generation of digital natives, are using the digital realm as an extension of their brain. The value of the digital realm to human society is not found in the technology that is being used, the value is found in the information, knowledge and insights that flow, evolve, and multiply in the digital realm. To be very clear, Web technology is fully commoditised. There is very little intrinsic value in the mundane software that powers the services from Google, Facebook, Microsoft, and other providers of Cloud platforms. The digital realm is currently owned and controlled by a small number of corporations, which is increasingly incompatible with its use value:
Digital knowledge as a personal brain extension
Unlimited on-demand communication between any number of netizens
A public tool for tracing information flows and for independent validation of scientific knowledge
A globally accessible interface to technologies that operate in the physical realm
Leaving these functions in the hands of a small number of corporations is not in the interest of society.
The decentralised Web we should aim for
It is time to acknowledge the commoditisation of digital technology, to decentralise control of the Web, and to provide digital technology as a public utility to all netizens, without any artificial constraints or interference.
What are the implications for governments and governance?
The governance challenge consists of:
Protecting personal freedom in the digital realm
Sustainable management of limited resources in the physical realm
Integration of social and ecological concerns in the interest of the inhabitants of the biosphere
Important first steps that can be undertaken today to address the governance challenge are outlined here.





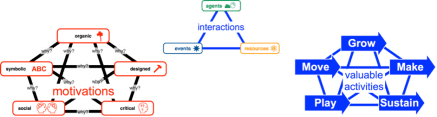

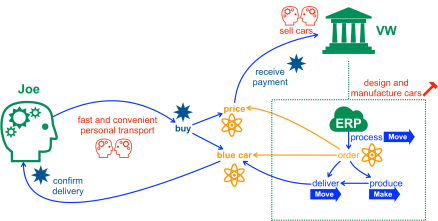













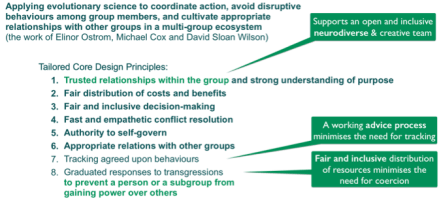

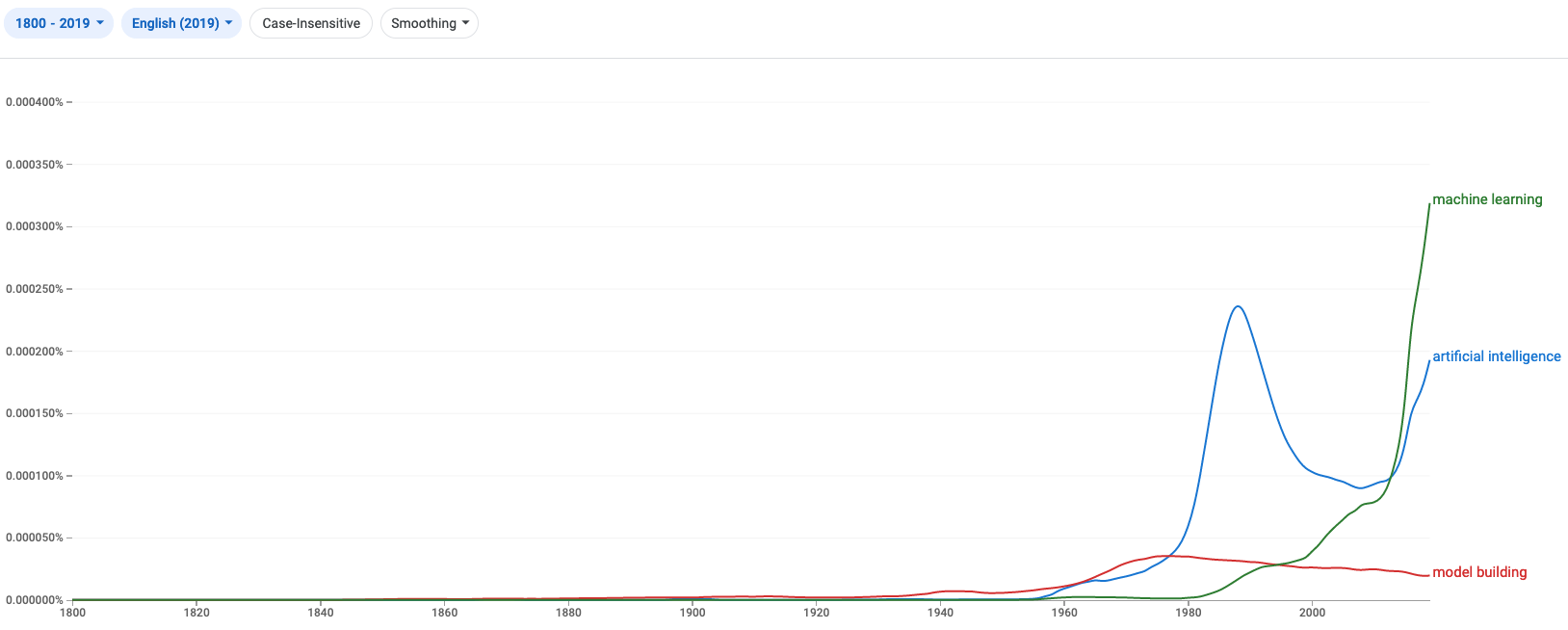




 In all domains where decisions and actions may have significant impact on others and on the environment we live in, adopting a more autistic mindset in relation to human stories may improve human decision making. In the Asch conformity experiment,
In all domains where decisions and actions may have significant impact on others and on the environment we live in, adopting a more autistic mindset in relation to human stories may improve human decision making. In the Asch conformity experiment, 


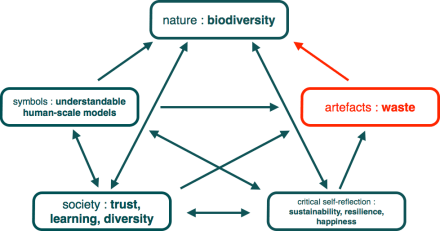










You must be logged in to post a comment.